哈希表
什么是哈希表
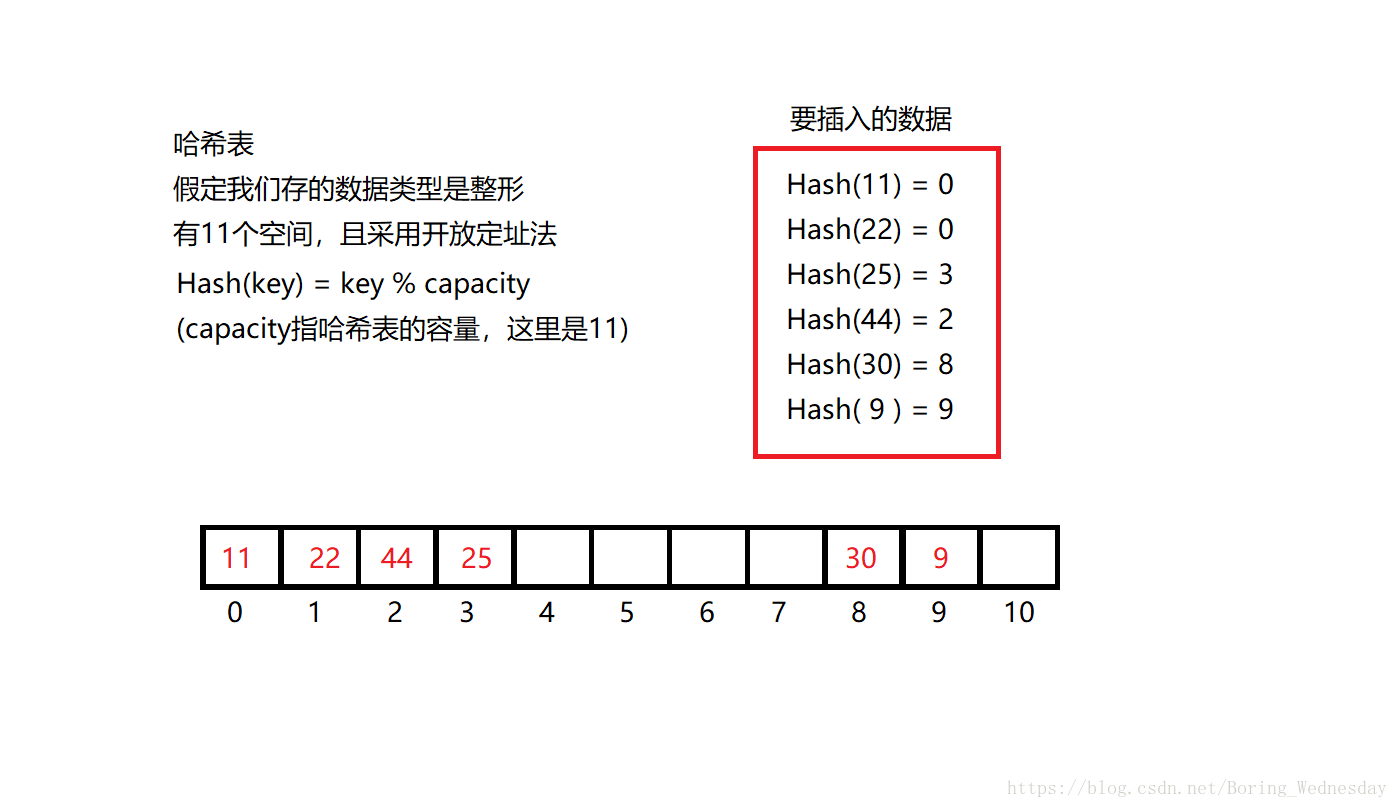
哈希表就是一个元素有一一对应位置的一个表,如下图,哈希表也叫散列表,和函数的一个x对应一个y类似,不存在多个y对应一个x,当然哈希表可能有多个数对应一个下标,我们后面讲,这里暂且理解为和函数一样,是一种映射。 在图中,哈希表存的数据位整形,如果我们存手机号,可以将后四位作为key,或者是后四位经过一个算数处理,当作key也可以。
哈希表作为一个查找时间复杂度只有O(1)的数据接结构,可以说效率非常高。 对于二叉搜索树而言,二叉搜索树中的元素存储位置和其值没有直接对应关系,需要多次将关键码进行比较来查询。 相比二叉搜索树,哈希表有一对一对应的映射关系,不需要多次比较来查找。 我认为这是典型的空间换时间的数据结构,通过一对一映射的方式,必将有空间为空,说明其空间利用率其实不是100%,像java中,哈希表的存储利用率为0.75,超过0.75这个预设值,哈希表将被扩容,我在这篇文章中所用的开放定址法的代码将这个值控制在0.7,而拉链法的比例控制为1。
哈希冲突 如上图一样,11和22在哈希表容量为11的时候,他们对应的都是0,这就有了冲突,解决冲突有两种办法,开散列和闭散列。
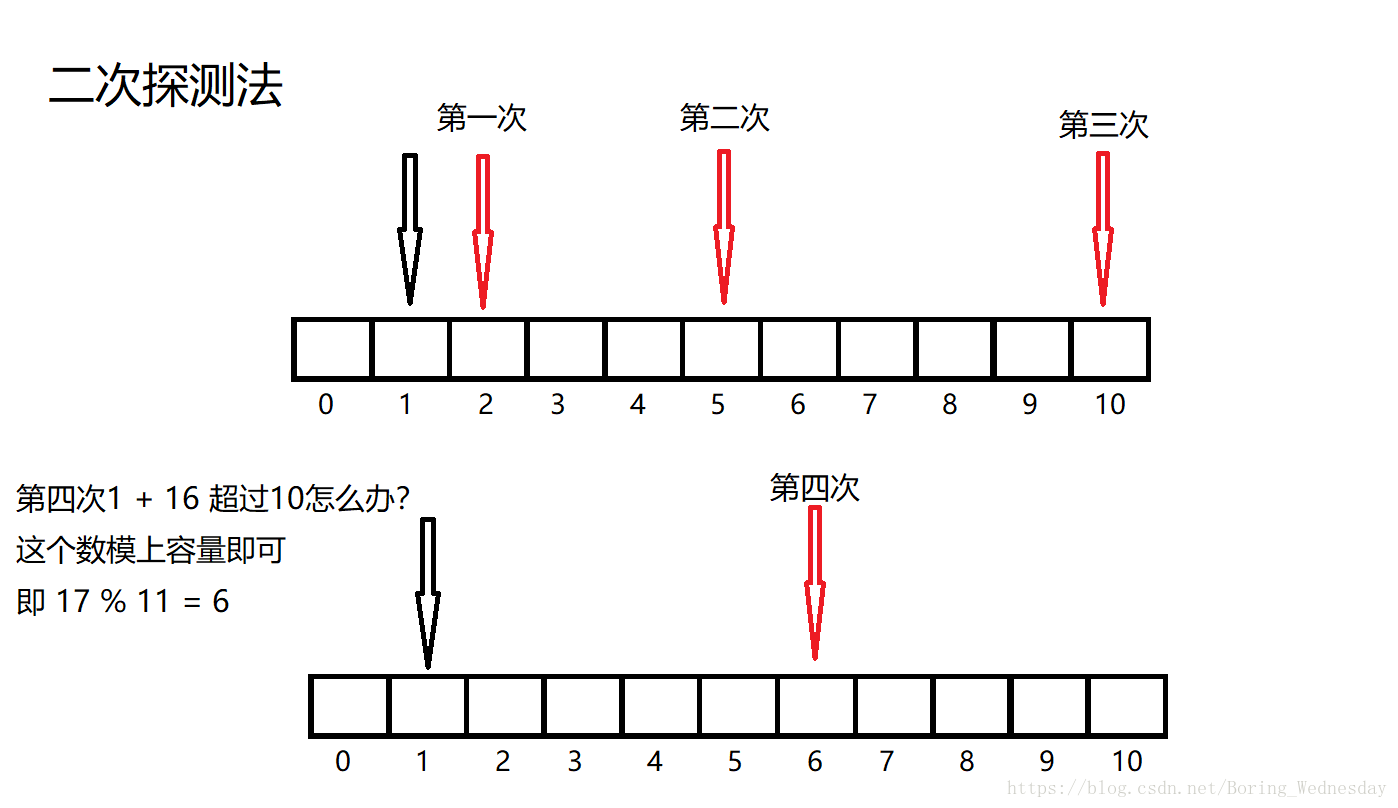
开散列 开散列又叫开放定址法,一个位置只存一个元素,如果新来的元素发现该位置有冲突,就向后寻找,直至找到一个空位为止,存入数据,但是很多时候这种方法很不好,容易造成过多的冲突,于是有了二次线性探测,和直接探测不同,二次探测是依次往后探测n的平方个,第一次往后一个,第二次往后4个,第三次往后9个。
闭散列(用此种方法实现的哈希表称之为哈希桶) 闭散列又称拉链法,当有数冲突的时候,不是往后找,而是直接挂在这个位置的下面,像链表一样挂起来,这个方式一容量和元素个数的比例一般控制为1,多了会影响查找效率。

但是这种方法也有个坏处,假如有人恶意将其所有元素均存在一个位置,然后进行访问,就会出现访问速度过慢的问题,假如这被应用在网站的话,就会造成网站崩溃,无法访问。
负载因子 负载因子我在上面也有带着提到过,这里详细说一下。 负载因子α = 表中元素个数 / 散列表的长度 由于表长是定值,所以α和填入表中的元素个数成正比,α越大,表明表中数据越多,冲突的可能性越大,反之冲突越小。 实际上,散列表的平均查找长度是载荷因子α 的函数,只是不同处理冲突的方法有不同的函数。 对于开放定址法,负载因子是特别中原的因素,应严格控制在0.7~0.8以下,超过0.8,查表时CPU的缓存不命中(cache missing)按照指数曲线上升,因此一些采用开放定址法的库比如java就是限制负载因子为0.75,超过则resize。 ———————————————— 版权声明:本文为CSDN博主「无聊星期三」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/Boring_Wednesday/article/details/80316884