简介: 1 eBPF 介绍eBPF 是革命性技术, 起源于 linux 内核, 能够在操作系统内核中执行沙盒程序。旨在不改变内核源码或加载内核模块的前提下安全便捷的扩展内核能力。1.1 demo 展示demo程序如下:#include <linux/bpf.h> #define SEC(NAME) attribute((section(NAME), used)) SEC("
eBPF 介绍
eBPF 是革命性技术, 起源于 linux 内核, 能够在操作系统内核中执行沙盒程序。旨在不改变内核源码或加载内核模块的前提下安全便捷的扩展内核能力。
demo 展示
demo程序如下:
#include <linux/bpf.h>
#define SEC(NAME) __attribute__((section(NAME), used))
SEC("xdp")
int xdp_drop_the_world(struct xdp_md *ctx) {
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
执行步骤:
clang -O2 -target bpf -c demo.c -o demo.o
sudo ip link set dev lo xdp obj demo.o sec xdp verbose
sudo ip link set dev lo xdp off
效果:
终端执行 ping 程序,不断有输出,
执行 sudo ip link set dev lo xdp obj demo.o sec xdp verbose停止
输出,执行 sudo ip link set dev lo xdp off后恢复输出。
此处为语雀视频卡片,点击链接查看:ebpf example.mov
BPF 的由来
eBPF 是 extended BPF 的简称,而 BPF 的全称是 Berkeley Packet Filter, 即伯克利报文过滤器,它的设计思想来源于 1992 年的一篇论文“The BSD packet filter: A New architecture for user-level packet capture” (《BSD数据包过滤器:一种用于用户级数据包捕获的新体系结构》)。最初,BPF 是在 BSD 内核实现的,后来,由于其出色的设计思想,其他操作系统也将其引入, 包括 Linux。
举个例子,在分析网络问题时,我们会使用 tcpdump 获取网络报文,tcpdump 支持通过 -d 选项可显示tcpdump的过滤规则转换后的特殊指令,如下所示:
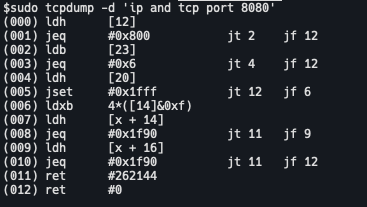
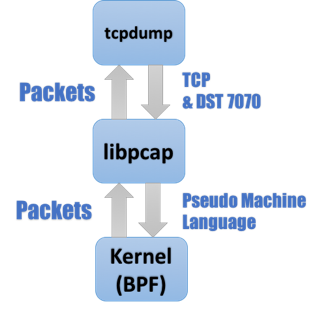
而这些特殊的指令就是BPF(Berkeley Packet Filter,伯克利包过滤器),这种特殊指令通过 libpcap 接口传递进入内核,当网卡收到了数据包后会执行注册的 AF_PACK 协议中的 packet_rcv 函数,执行用户态传入的 BPF 指令,如果满足过滤规则就 clone 到用户态。通过不断优化这些指令来提高用户过滤获取数据包的性能。大体流程如下:
BPF 历史:
- 1997 年合并入 Linux 2.1.75 版本(BPF 开始位于 BSD 系统)
- 2011 年加入 BPF JIT 编译器
- 2012 年为 seccomp 添加 BPF过滤器
当前 BPF 的应用场景:
- tcpdump 格式的报文过滤
- Linux 网络流量控制 TC Qos cls_bpf
- seccomp-bpf 沙盒程序系统调用过滤
- Netfilter iptables xt_bpf
思考:BPF解决了什么问题 ?
- 将程序逻辑挂载到内核执行
- 内核态直接操作,执行性能高,将数据包过滤技术性能提升 20 倍以上
什么是 eBPF
eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。
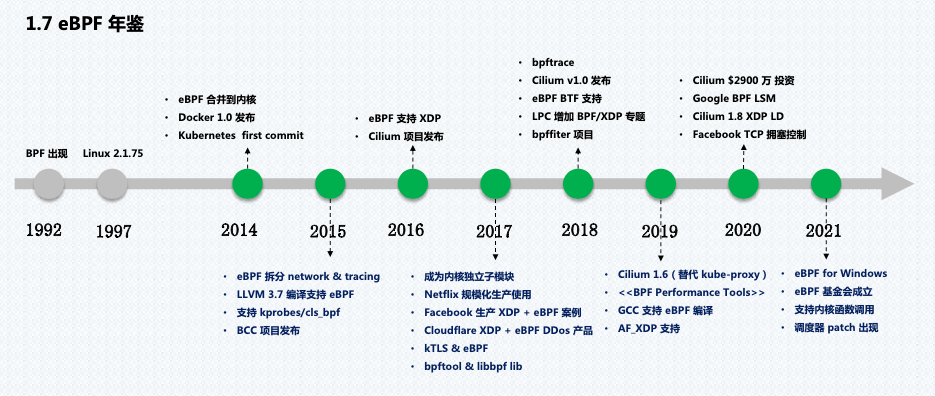
出于对更好的 Linux 跟踪工具的需求,eBPF 从 dtrace 中汲取灵感,dtrace 是一种主要用于 Solaris 和 BSD 操作系统的动态跟踪工具。与 dtrace 不同,Linux 无法全面了解正在运行的系统,因为它仅限于系统调用、库调用和函数的特定框架。在Berkeley Packet Filter (BPF)(一种使用内核 VM 编写打包过滤代码的工具)的基础上,一小群工程师开始扩展 BPF 后端以提供与 dtrace 类似的功能集,eBPF 诞生了。发展历史如下:
eBPF 比起传统的 BPF 来说,传统的 BPF 只能用于网络过滤,而 eBPF 则可以用于更多的应用场景,包括网络监控、安全过滤和性能分析等。另外,eBPF 允许常规用户空间应用程序将要在 Linux 内核中执行的逻辑打包为字节码,当某些事件(称为挂钩)发生时,内核会调用 eBPF 程序。此类挂钩的示例包括系统调用、网络事件等。
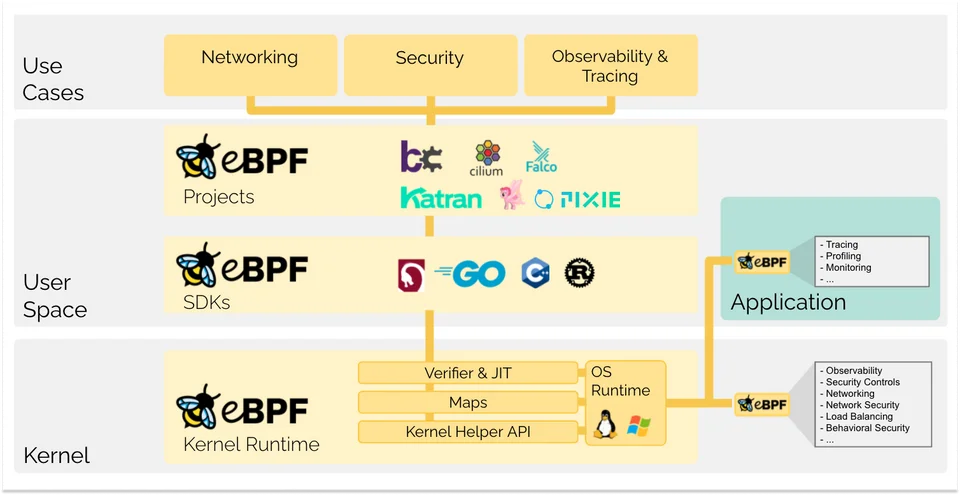
后面会做详细介绍。
思考:eBPF 和内核版本关系是什么?
eBPF 技术在不断发展,越新的内核包含特性越丰富。参考文档 https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
使用高版本内核编写内核程序,如果使用到新实现的 eBPF 特性,那么该程序在低版本内核可能就无法运行。目前阿里云售卖的 ecs 是 4.19 版本内核。
$ uname -a
Linux iZt4nehxuneswo3c2bvol2Z 4.19.91-23.al7.x86_64 #1 SMP Tue Mar 23 18:02:34 CST 2021 x86_64 x86_64 x86_64 GNU/Linux
思考:写 eBPF 程序和写内核程序区别是什么?
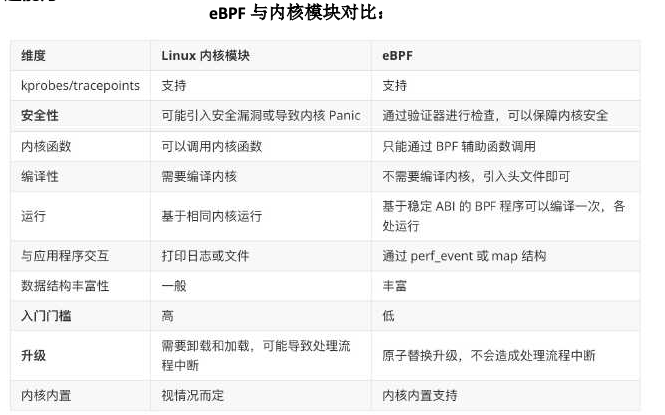
思考:cBPF 和 eBPF 区别是什么?

原理介绍
eBPF 整个技术栈如下:
当我们编写好 eBPF 程序后,内核通过事件驱动的方式执行程序逻辑。因此我们先介绍事件,然后介绍 eBPF 的编写、加载、验证等内容。
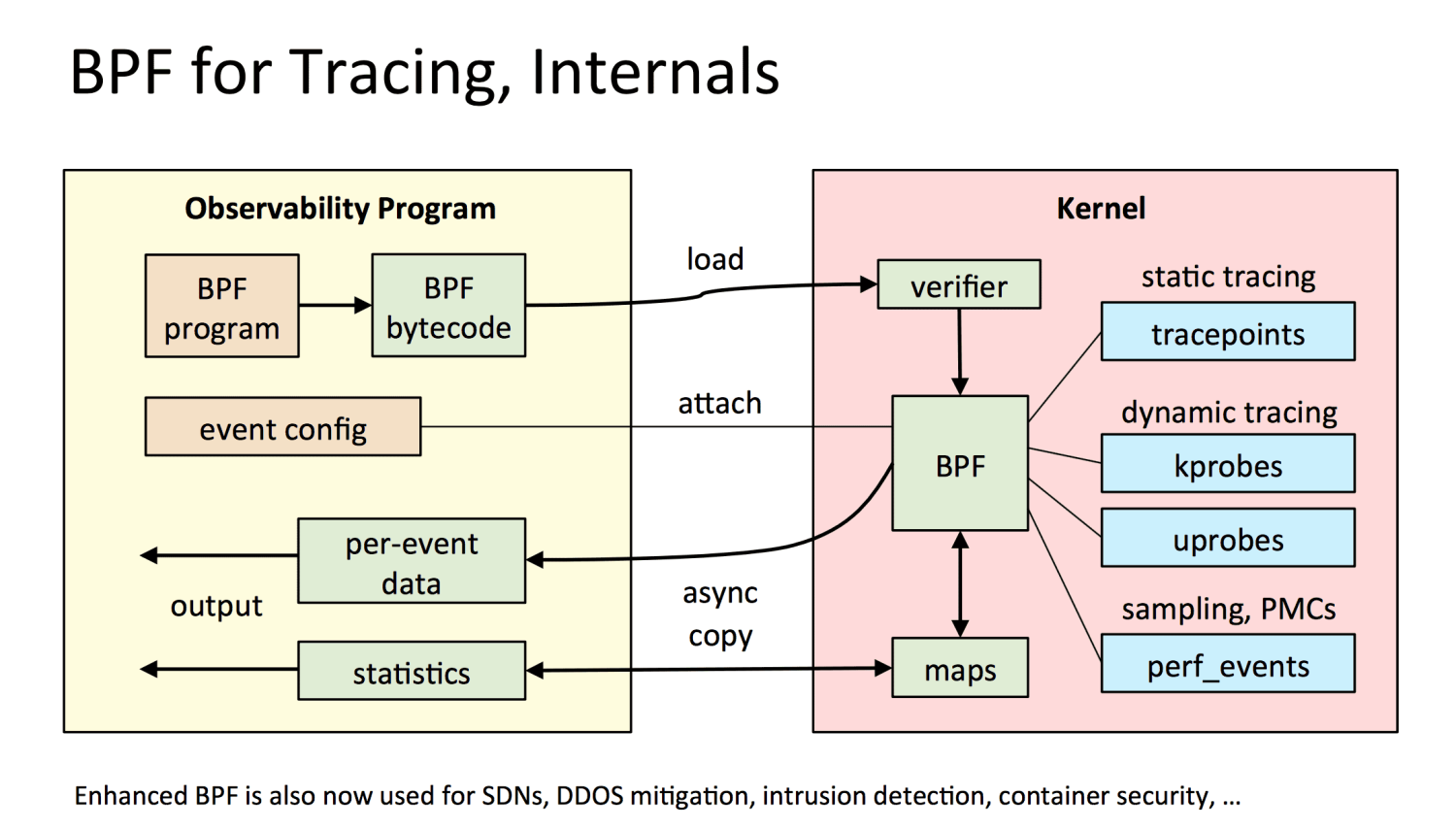
事件总览
eBPF 程序是事件驱动的,当事件发生后执行程序,从上图右边可以看到,事件可以是用户态,也可以是内核态。一些事件例子如下:
- system calls
- 一些函数入口或者出口
- 内核 tracepoint(静态)
- kprobes(动态)
- 网络事件
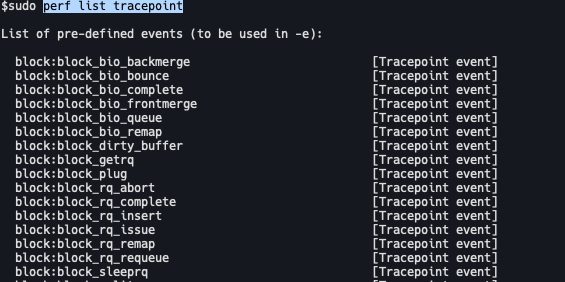
事件体系本身也比较复杂,需要对内核知识有一定的了解。以 tracepoint 事件为例,通过 perf list tracepoint可以看到内核 tracepoint:
程序编写
直接编写 eBPF 程序比较困难,初学者可以利用现有的一些项目,如:
- Cilium:k8s 上使用 eBPF 的项目 https://cilium.io/
- bcc:流行的编写 eBPF 程序的框架和库 https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
- bpftrace:为编写 eBPF 程序设计的语言 https://github.com/iovisor/bpftrace/blob/master/docs/tutorial_one_liners.md
- libbpf:通过 c 语言编写的脚手架,提供很多方便的特性方便编写程序 https://libbpf.readthedocs.io/en/latest/libbpf_overview.html
这些项目让编写 eBPF 程序更加简单,也有很多示例程序。但这些项目对 eBPF 程序进行了封装,隐藏了很多底层细节,深入学习还需要从 linux 源码入手。
基于内核源代码编写 eBPF 程序
不同版本编译内核源代码方式有一定区别,主要解决工具依赖、头文件依赖和库依赖等问题。高版本遇到的问题相对少一些。可以参考文档 https://ata.alibaba-inc.com/articles/264468。编译内核会遇到各种问题,该系列让编译简单很多,也符合阿里云上内核 4.19 要求。现在网上很多资料都是基于 5.x 内核,在生产环境使用会遇到一些问题。
内核代码 samples/bpf 中也有很多示例程序可以学习参考。
熟悉 c/c++ 的人对 eBPF 的编译过程会比较熟悉,修改 Makefile 便可以修改编译过程。
编译完成后,就会生成对应的字节码。对于内核程序,通过加载字节码运行 eBPF 程序。字节码(byte code)是一种包含执行程序、由一序列 OP代码(操作码)/数据对组成的二进制文件。因此需要将 eBPF 程序编译成字节码,最常用的方法是通过类似 LLVM 工具链编写,目前支持 python、go 、c 和 rust 等语言编写 eBPF 程序。

上面提到了字节码,我们介绍下字节码和机器码区别。
机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据(计算机只认识0和1)。
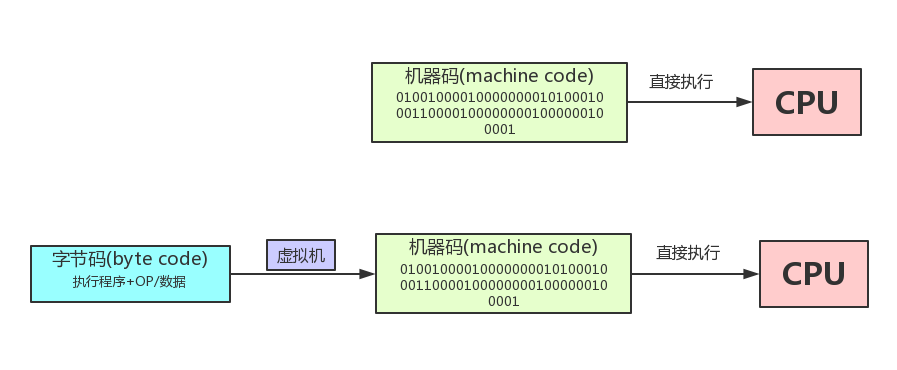
**字节码(byte code)**是一种包含执行程序、由一序列 OP代码(操作码)/数据对 组成的二进制文件。
字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
通常情况下它是已经经过编译,但与特定机器码无关。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。
加载、验证和 JIT 编译
当 eBPF 程序被编译成字节码以后,然后使用加载程序 Loader 通过 bpf() 系统调用将字节码加载至内核。加载到 linux 内核后,会对程序进行验证。验证是非常重要的一步,验证时会对程序进行很多检查。如果没有这一步,攻击者就可以任意修改内核行为,导致系统被破坏。内核使用验证器(Verfier) 组件保证执行字节码的安全性,验证过程:
- 首先进行深度优先搜索,禁止循环;其他CFG验证。
- 以上一步生成的指令作为输入,遍历所有可能的执行路径。具体说就是模拟每条指令的执行,观察寄存器和栈的状态变化。
为了实现安全检查,对 eBPF 程序有如下限制:
- eBPF程序不能调用任意的内核函数,只限于内核模块中列出的BPF辅助函数,函数支持列表也随着内核 的演进在不断增加;最新进展是支持了直接调用特定的内核函数调用
- BPF程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止
- eBPF程序中循环次数限制且必须在有限时间内结束,Linux5.3在BPF中包含了对有界循环的支持,它有一个可验证的运行时间上限
- eBPF堆栈大小被限制在MAX_BPF_STACK,截止到内核Linux5.8版本,被设置为512eBPF字节码大小最 初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令 ,对于无特权的 BPF 程序,仍然保留 4096 条限制 (BPF_MAXINSNS);新版本的 eBPF 也支持了多个 eBPF 程序级联调用, 可以通过组合实现更加强大的功能
验证完成后,进行 JIT 编译,将字节码转换成 CPU 可运行的机器码。JIT 编译器可以极大加速 BPF 程序的执行,因为与解释器相比,它们可以降低每个指令的 开销(reduce the per instruction cost)。通常,指令可以 1:1 映射到底层架构的原生 指令。另外,这也会减少生成的可执行镜像的大小,因此对 CPU 的指令缓存更友好。特别 地,对于 CISC 指令集(例如 x86),JIT 做了很多特殊优化,目的是为给定的指令产生 可能的最短操作码(emitting the shortest possible opcodes),以降低程序翻译过程所 需的空间。
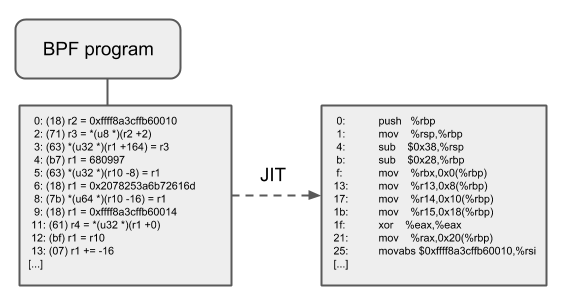
整体流程如下图:
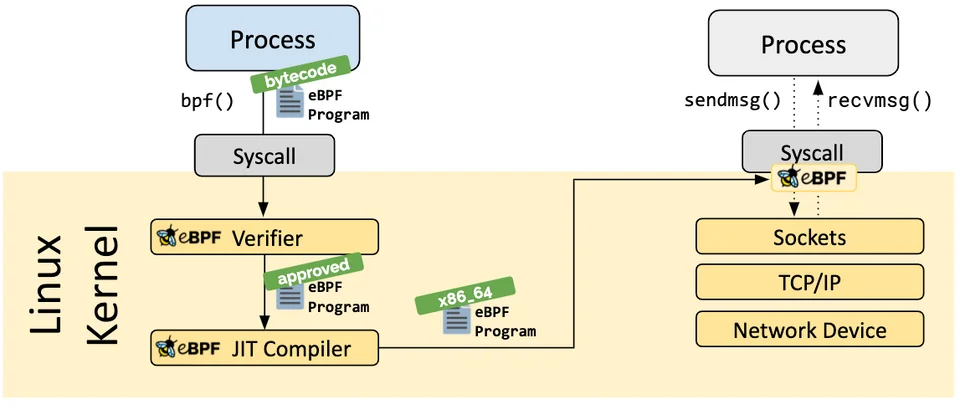
思考:如何找出所有的 eBPF 程序?
所有的 eBPF 都是通过 bpf call加载,因此在这上面挂载一个 eBPF 程序就可以知道所有加载的 eBPF 程序了。
思考:eBPF 会将内核整崩溃吗,比如程序会 core 吗?
根据前面验证器介绍可以防止让内核崩溃。具体到 eBPF 程序会 coredump吗?在网上没有搜索到答案,自己写个程序验证行为,构造一个访问空指针情况,验证器检查出来。
程序代码第 14 行将指针改为空:
SEC("xdp")
int xdp_drop_the_world(struct xdp_md *ctx) {
// drop everything
// 意思是无论什么网络数据包,都drop丢弃掉
void *data = (void*)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void*)eth + sizeof(*eth) <= data_end) {
struct iphdr *ip = data + sizeof(*eth);
if ((void*)ip + sizeof(*ip) <= data_end) {
if (ip->protocol == IPPROTO_UDP) {
struct udphdr *udp = (void*)ip + sizeof(*ip);
if ((void*)udp + sizeof(*udp) <= data_end) {
udp = 0;
if (udp->dest == __builtin_bswap16(7999)) {
udp->dest = __builtin_bswap16(7998);
}
}
}
}
}
return XDP_PASS;
}
加载报错信息:
lemon@lemon-server:~$ sudo ip link set dev lo xdp obj xdp-example.o sec xdp verbose~
libbpf: load bpf program failed: Permission denied
libbpf: -- BEGIN DUMP LOG ---
libbpf:
0: (61) r2 = *(u32 *)(r1 +0)
1: (61) r1 = *(u32 *)(r1 +4)
2: (bf) r3 = r2
3: (07) r3 += 14
4: (2d) if r3 > r1 goto pc+12
R1_w=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=0,r=14,imm=0) R3_w=pkt(id=0,off=14,r=14,imm=0) R10=fp0
5: (bf) r3 = r2
6: (07) r3 += 34
7: (2d) if r3 > r1 goto pc+9
R1_w=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=0,r=34,imm=0) R3_w=pkt(id=0,off=34,r=34,imm=0) R10=fp0
8: (71) r3 = *(u8 *)(r2 +23)
9: (55) if r3 != 0x11 goto pc+7
R1=pkt_end(id=0,off=0,imm=0) R2=pkt(id=0,off=0,r=34,imm=0) R3=inv17 R10=fp0
10: (07) r2 += 42
11: (2d) if r2 > r1 goto pc+5
R1=pkt_end(id=0,off=0,imm=0) R2_w=pkt(id=0,off=42,r=42,imm=0) R3=inv17 R10=fp0
12: (b7) r1 = 2
13: (69) r2 = *(u16 *)(r1 +0)
R1 invalid mem access 'inv'
processed 14 insns (limit 1000000) max_states_per_insn 0 total_states 1 peak_states 1 mark_read 1
libbpf: -- END LOG --
libbpf: failed to load program 'xdp_drop_the_world'
libbpf: failed to load object 'xdp-example.o'
思考:eBPF 对内核性能有影响吗?
验证器对 eBPF 程序做了限制,防止对内核产生很大影响。比如性能方面限制指令数量和禁止 while 循环。所以不可能出现一个 eBPF 程序运行 1s 影响内核。根据一些实践经验介绍,对内核性能影响较小,不用过于担心。
存储模块
eBPF 的存储模块由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。当使用较大的内存,需要用map。
Map 是 eBPF 的核心功能。内核运行的代码与加载其的用户空间程序可以通过 map 机制实现双向实时通信,这个特性非常有用,让内核态程序和用户态程序相互影响,有点类似 go 语言中的 channel。
BPF Map是驻留在内核中的以键/值方式存储的数据结构,可以被任何知道它们的 eBPF 程序访问。在用户空间运行的程序也可以通过使用文件描述符来访问eBPF Map。可以在eBPF Map中存储任何类型的数据,但需要指定个数和大小。在内核中,键和值都被视为二进制的方式来存储。
eBPF Map用于用户空间和内核空间之间进行双向的数据交换、信息传递。彼此共享MAP的BPF程序不需要具有相同的程序类型。
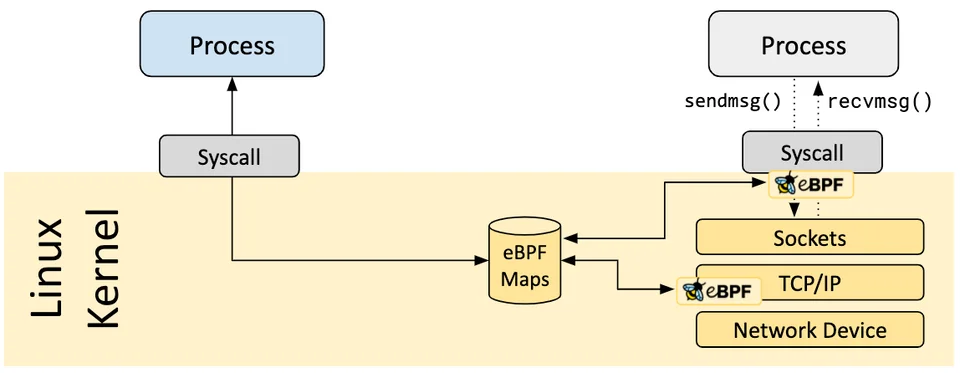
Map 类型有:
- Hash tables, Arrays
- LRU (Least Recently Used)
- Ring Buffer
- Stack Trace
- LPM (Longest Prefix match)
- …
可以 linux 看到相关定义
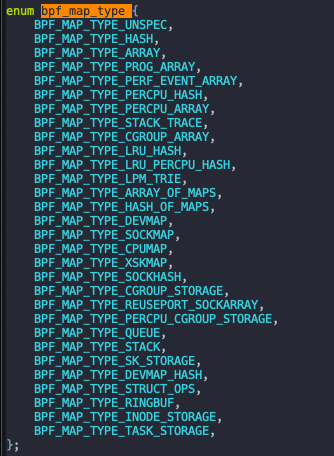
更多详细内容参考 https://yuque.antfin.com/qe7tfv/gf2vxx/xnkqatrg545utnmg
eBPF Map也有自己的 CRUD,主要操作如下:
- bpf_map_create 函数,创建 Map
- bpf_map_lookup_elem(map, key)函数,通过key查询BPF Map,得到对应value
- bpf_map_update_elem(map, key, value, options)函数,通过key-value更新BPF Map,如果这个key不存在,也可以作为新的元素插入到BPF Map中去
- bpf_map_get_next_key(map, lookup_key, next_key)函数,这个函数可以用来遍历BPF Map,下文有具体的介绍。
辅助函数
eBPF 程序并不能随意调用内核函数,因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互。限制对内核函数调用也是保证 eBPF 程序安全性的重要部分。
从内核 5.13 版本开始,部分内核函数(如 tcp_slow_start()、tcp_reno_ssthresh() 等)也可以被 BPF 程序直接调用了。 不过,这些函数只能在 TCP 拥塞控制算法的 BPF 程序中调用。
查看所有helper函数:https://man7.org/linux/man-pages/man2/bpf.2.html

不同类型的 eBPF 程序所支持的辅助函数是不同的。比如,对于kprobe类型的 eBPF 程序,可以在命令行中执行 bpftool feature probe ,来查询当前系统支持的辅助函数列表:
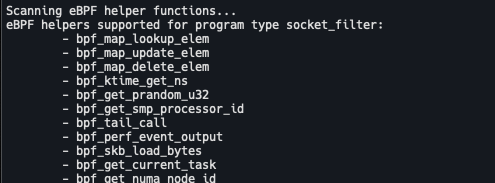
辅助函数类型包括:
- 生成随机数
- 获取时间
- 操作 eBPF Maps
- 获取进程上下文
- 操作网络报文
- ….
关于 eBPF 的程序类型,我们后面做介绍。
尾调用
通过 Tail & Function Calls,我们可以使用一个 eBPF 程序调用另一个 eBPF 程序。这样组合起来就可以实现复杂的功能。如下图:
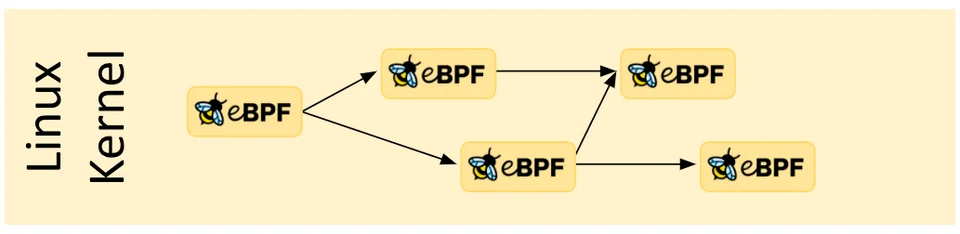
有了尾调用,就可以把复杂的逻辑拆分到多个 eBPF 程序中,减少代码规模,更加易于维护。
程序类型
eBPF 程序类型决定了一个 eBPF 程序可以挂载的事件类型和事件参数,这也就意味着,内核中不同事件会触发不同类型的 eBPF 程序。程序类型根据挂载的事件确定。
根据内核头文件 bpf.h 中 bpf_prog_type 的定义,Linux 内核 v5.13 已经支持 30 种不同类型的 eBPF 程序(注意, BPF_PROG_TYPE_UNSPEC表示未定义):
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC, /* Reserve 0 as invalid program type */
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
};
对于具体的内核来说,因为不同内核的版本和编译配置选项不同,一个内核并不会支持所有的程序类型。你可以在命令行中执行下面的命令,来查询当前系统支持的程序类型:
bpftool feature probe | grep program_type
根据具体功能和应用场景的不同,这些程序类型大致可以划分为三类
- 第一类是跟踪,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么。
- 第二类是网络,即对网络数据包进行过滤和处理,以便了解和控制网络数据包的收发过程。
- 第三类是除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等。
程序解析
我们以一个程序为例说明程序类型转换过程。
#include <linux/bpf.h>
#define SEC(NAME) __attribute__((section(NAME), used))
static int (*bpf_trace_printk)(const char *fmt, int fmt_size,
...) = (void *)BPF_FUNC_trace_printk;
SEC("tracepoint/syscalls/sys_enter_execve") // 这个名字是程序类型吗?
int bpf_prog(void *ctx) {
char msg[] = "Hello, BPF World!";
bpf_trace_printk(msg, sizeof(msg));
return 0;
}
char __license[] SEC("license") = "GPL";
思考:上面哪段代码表示了 eBPF 的程序类型?
程序类型信息通过 SEC(“tracepoint/syscalls/sys_enter_execve”) 标识,SEC 表示在 ELF 格式文件中的段名。但这行代码如何转成内核识别的类型呢?首先查看生成的二进制文件:
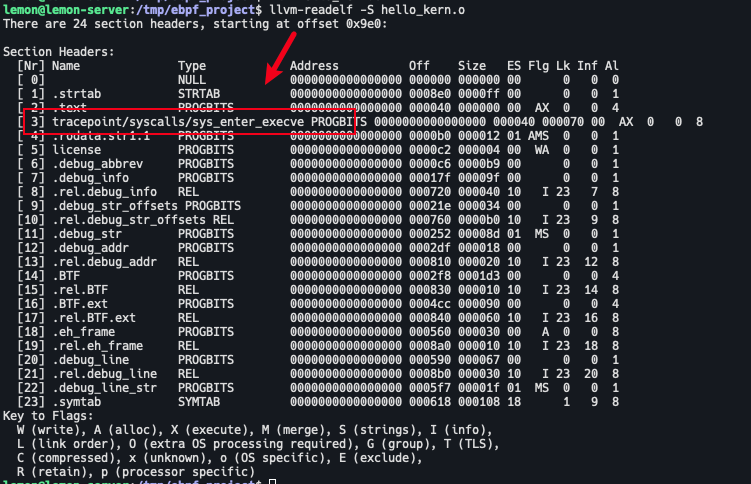
查看内核代码 tools/lib/bpf/libbpf.c:
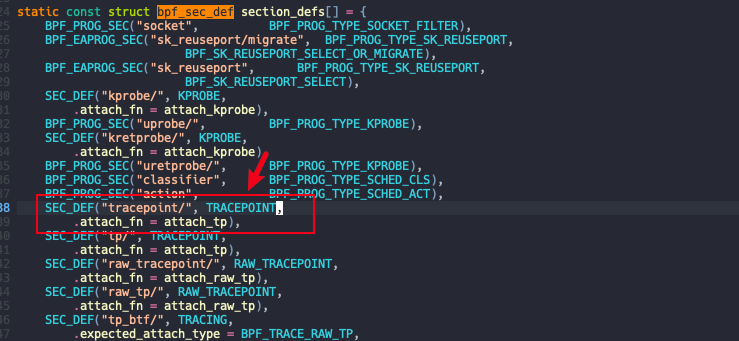
除了上面内核态部分程序,eBPF 也要求有用户态部分程序,名字如 **_kern.c 和 **_user.c。对应上面的 **_user.c 代码如下:
#include <stdio.h>
#include <fcntl.h>
#include <poll.h>
#include <time.h>
#include <signal.h>
#include <bpf/libbpf.h>
int main(int argc, char **argv)
{
struct perf_buffer_opts pb_opts = {};
struct bpf_link *link = NULL;
struct bpf_program *prog;
struct perf_buffer *pb;
struct bpf_object *obj;
int map_fd, ret = 0;
char filename[256];
FILE *f;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
obj = bpf_object__open_file(filename, NULL);
if (libbpf_get_error(obj)) {
fprintf(stderr, "ERROR: opening BPF object file failed\n");
return 0;
}
/* load BPF program */
if (bpf_object__load(obj)) {
fprintf(stderr, "ERROR: loading BPF object file failed\n");
goto cleanup;
}
prog = bpf_object__find_program_by_name(obj, "bpf_prog");
if (libbpf_get_error(prog)) {
fprintf(stderr, "ERROR: finding a prog in obj file failed\n");
goto cleanup;
}
link = bpf_program__attach(prog);
if (libbpf_get_error(link)) {
fprintf(stderr, "ERROR: bpf_program__attach failed\n");
link = NULL;
goto cleanup;
}
cleanup:
bpf_link__destroy(link);
bpf_object__close(obj);
return ret;
}
程序中的 bpf_object__open_file、bpf_object__load等函数就对应了加载等逻辑,在 libbpf.c 文件中都有代码实现。
问题排查
程序调试
eBPF 程序能的使用的C语言库数量有限,并且不支持调用外部库,想要调试程序比较困难,比如 printf 函数无法直接使用。
为了克服这个限制,最常用的一种方法是定义和使用BPF辅助函数,即helper function。比如可以使用bpf_trace_printk()辅助函数,这个函数可以根据用户定义的输出,将BPF程序产生的对应日志消息保存在用来跟踪内核的文件夹(/sys/kernel/debug/tracing/),这样,我们就可以通过这些日志信息,分析和发现BPF程序执行过程中可能出现的错误。
typedef unsigned int u32;
#define bpfprint(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), \
##__VA_ARGS__); \
})
// 使用
bpfprint("src ip addr2:.%d\n",(ip_src >> 24) & 0xFF);
生产问题排查
bpf_trace_printk 程序有如下问题:
- 最大只支持3个参数,而且只运行一个%s的参数
- 程序共享输出共享/sys/kernel/debug/tracing/trace_pipe文件,可能导致文件输出错乱
- 该实现方式在数据量大的时候,性能也存在一定的问题
因此在生产上很难使用 bpf_trace_printk。对于日志数据,eBPF 程序可以通过 perf event(一种 map)发送给用户态程序,由用户态程序负责打印。相关资料:
https://lwn.net/Articles/649965/
https://mozillazg.com/2021/04/ebpf-gobpf-store-and-read-data-use-perf-event.html
使用案例
BCC 工具
为了简化 BPF 程序开发,社区创建了 BCC 项目:其为编写、加载和运行 eBPF 程序提供了一个易于使用的框架,除了“限制性 C”之外,还可以通过编写简单的 Python 或 Lua 脚本来实现。
BCC 是个工具库,里面有很多有用的程序可以使用。
内存检测:

登录审计:
examples:
./tcpaccept # trace all TCP accept()s
./tcpaccept -t # include timestamps
./tcpaccept -P 80,81 # only trace port 80 and 81
./tcpaccept -p 181 # only trace PID 181
./tcpaccept --cgroupmap mappath # only trace cgroups in this BPF map
./tcpaccept --mntnsmap mappath # only trace mount namespaces in the map
./tcpaccept -4 # trace IPv4 family only
./tcpaccept -6 # trace IPv6 family only
效果如下:

除了 BCC,例外一个很好用的工具是 BPFTrace https://github.com/iovisor/bpftrace,是一个用于LinuxeBPF的高级跟踪语言,语法类似awk脚本语言。 bpftrace 使用 LLVM 作为后端,将脚本编译成BPF 字节码,并可使用现有的 Linux 跟踪能力和附件点进行交互的库。
如果你文本处理经常使用 awk 工具,应该可以体会到其中的好处。
网络
我们从 RX(报文到达)和 TX(报文发送)两个链路说明网络程序。主要模块是 XDP 和 TC 模块。如下图:
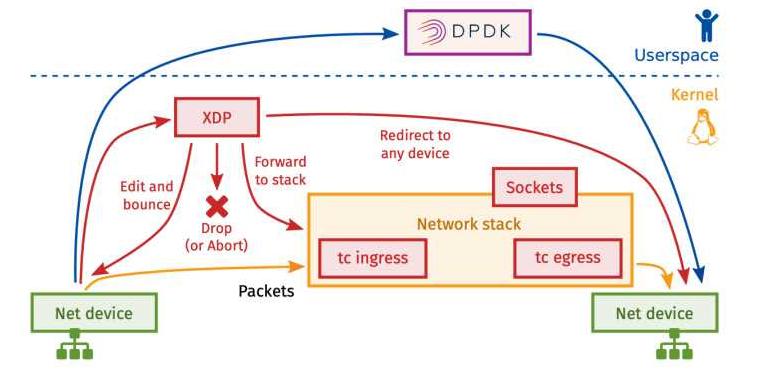
此处我们主要介绍 XDP 模块。XDP 对应 RX 链路,在报文到达时触发。在讲 XDP 之前,我们说明下现在高性能网络的一些问题:
- 内核在处理网络数据的时候采用软中断方式
- 需要构造sk_buff结构体,在大量网络数据包场景下会导致系统性能下降
- 用户态和内核态的频繁的上下文切换
为了实现高性能网络,一种思路是绕过内核,全部在用户态处理,如 Intel 的 DPDK 项目。另一种思路就是使用 XDP。XDP处理报文行为如下:
- XDP_DROP 丢弃数据包,这通常发生在驱动程序最早的 RX 阶段,对于降低 Dos 场景而言,尽早丢弃包是关键,这可以尽量少的占用 CPU 的处理时间;
- XDP_TX :转发数据包,可能发生在数据包被修改前或修改后,将处理后的数据包发回给相同的网卡;
- XDP_PASS:将数据包传递到普通网络协议栈处理,与没有 XDP BPF 程序运行的效果一致;
- XDP_REDIRECT :与 XDP_TX 类似,只是转发的目的地可以为其他 CPU 处理队列、不同的网卡或转发到特定的用户空间 socket(AF_XDP),具体依赖于 Redirect Map 的设置;
- XDP_ABORTED 表示 BPF 程序错误,并导致数据包对丢弃,可通过 trace_xdp_exception 跟踪点进行额外监控;
性能数据:
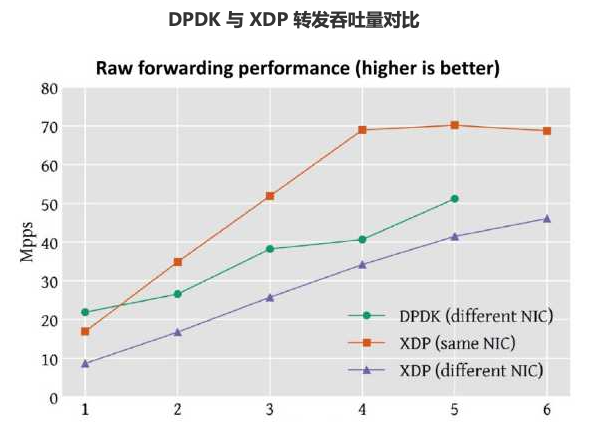
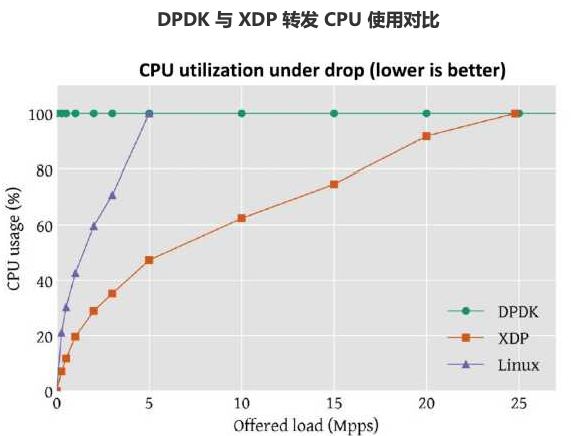
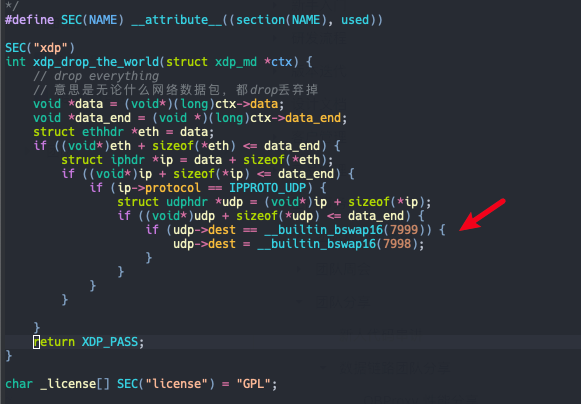
XDP 可以完成很多网络相关功能,再举个例子,如下面例子将发给 7999 端口的报文转发给 7998:
云原生 Cilium 项目
Cilium 是一款开源软件,也是 CNCF 的孵化项目,目前已有公司提供商业化支持,还有基于 Cilium 实现的服务网格解决方案。最初它仅是作为一个 Kubernetes 网络组件。Cilium 底层是基于 Linux 内核的新技术 eBPF,可以在 Linux 系统中动态注入强大的安全性、可见性和网络控制逻辑。 Cilium 基于 eBPF 提供了多集群路由、替代 kube-proxy 实现负载均衡、透明加密以及网络和服务安全等诸多功能。Cilium 底层是基于 Linux 内核的新技术 eBPF,可以在 Linux 系统中动态注入强大的安全性、可见性和网络控制逻辑。 Cilium 基于 eBPF 提供了多集群路由、替代 kube-proxy 实现负载均衡、透明加密以及网络和服务安全等诸多功能。

注意:Cilium 要求 Linux kernel 版本在 4.8.0 以上,Cilium 官方建议 kernel 版本至少在 4.9.17 以上。
基于 eBPF,也可以加速 k8s 的网络,现有网络的调用路径如下,每一步都用标号标识:

通过 eBPF 可以大大减少调用,效果如下,黄色部分的逻辑都可以省略:
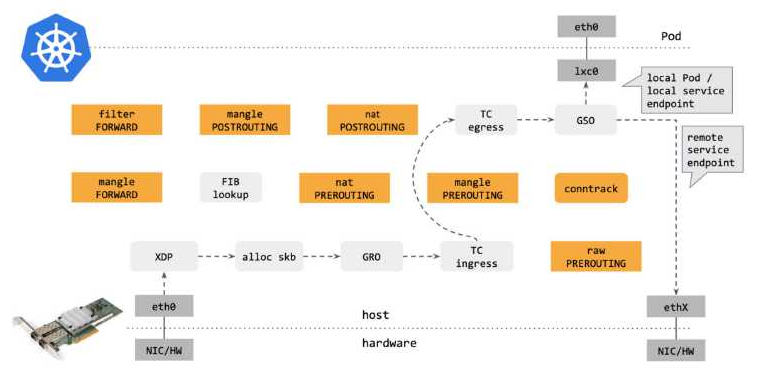
国外公司使用
国外公司使用如下:
- Facebook:Katran 开源负载均衡器, L4LB、DDoS、Tracing
- Netflix:BPF 重度用户,例如生产环境 Tracing
- Google:Android、服务器安全以及其他很多方面,GKE 默认使用 Cilium 作为网络基础
- Cloudflare:L4LB、DDoS
- Apple:使用 Falcon 识别安全风险
- AWS:使用 eBPF 作为 RPC 观测工具等
国内公司使用
国内公司使用如下(可以从 infoq 等平台查找相关介绍):
- 字节跳动:百万主机可观测性探测和 ACL 访问控制列表
- 阿里云: CNI 网卡采用 eBPF 技术观测和故障演练拓扑
- 腾讯:Cilium 作为 TKE 的底层引擎
- 网易:轻舟平台 eBPF 和 Cilium 的实践
- 携程:Cilium + BGP 云原生网络实践
公司内部探索
eBPF 主要应用在观测诊断、网络和安全三个方向。我们从这三个方向介绍我们的工作。
观测诊断
观测性
现有很多工具都可以进行主机指标采集,如 linux 系统提供的 sar(System Activity Reporter 系统活动情况报告)。eBPF 可以提供更细粒度的指标采集并进行逻辑处理。如 TCP 相关指标:
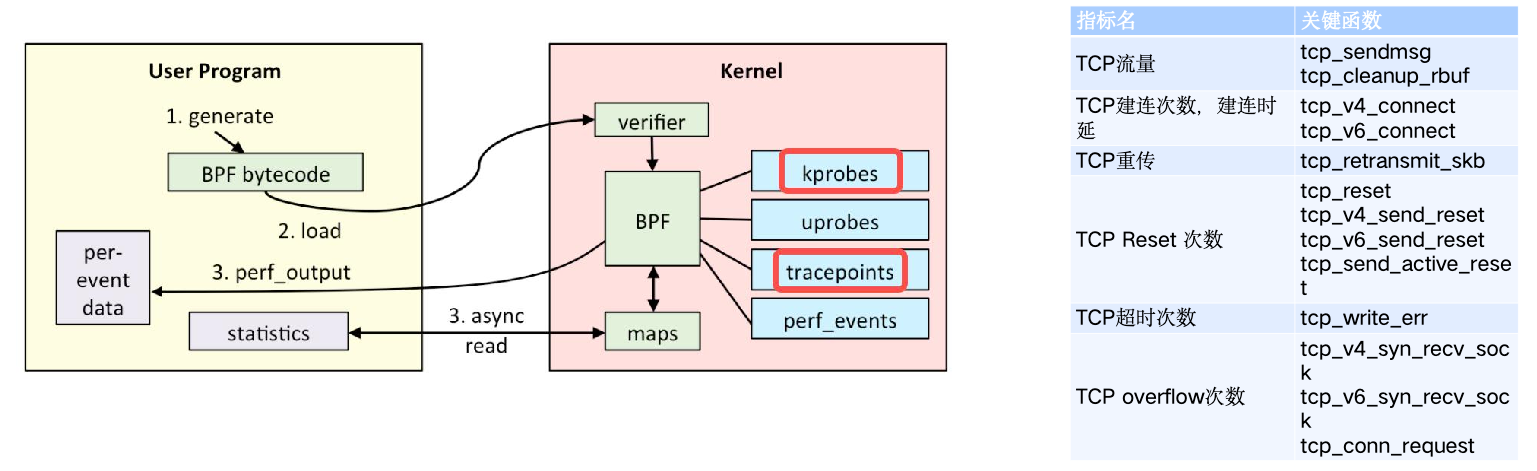
上面内容来自于 字节跳动基于 eBPF 的百万级主机网络可观测性实践与探索-林润⻰.pdf
对于 TCP 指标,也有开源项目实现 https://github.com/weaveworks/tcptracer-bpf
PolarDB 团队发布过 TcpRT:阿里云RDS智能诊断系统(发表于SIGMOD 2018)https://ata.alibaba-inc.com/articles/107312?spm=ata.25287382.0.0.11f93d0b91PS1T,其中也涉及到内核指标采集:

这些指标也可以在对应的内核函数运行 eBPF 程序采集。
OB 是分布式数据库,对磁盘、网络、内存、CPU 都有要求,因此可以根据业务特点梳理出需要的事件点用来监控。对于 OBProxy,主要是网络相关内容,比如断连接问题,可以在不修改 OBProxy 代码的情况下,监控 tcp_reset 事件记录所有断连接行为。
诊断性
OB 中有异常处理的代码,如 right_to_die_or_duty_to_live发生异常才会调用,整个线程因此会 hang 住,因此可以在用户太代码挂载 eBPF 程序,打印对于排查问题有用的信息,如函数调用堆栈。因为对应用代码无侵入性,也不需要发布新的版本。
思考:小明说连接 OBProxy,内存增加了 xx 字节,请问哪些逻辑出发了内存分配?
内存分配都会走到内核的函数中,在对应函数上挂载 eBPF 程序,打印出调用堆栈。
网络
网络主要分为观测性和性能加速,观测性前面已经讲到,此处主要讲下性能加速。在 3.2 部分我们已经讲到过 XDP 和 DPDK,都是提升网络性能的手段。如 https://github.com/Orange-OpenSource/bmc-cache#cite-this-work对 memcached 进行了性能加速,性能提升 3~18 倍。相关论文 bmc.pdf
主要流程如下:
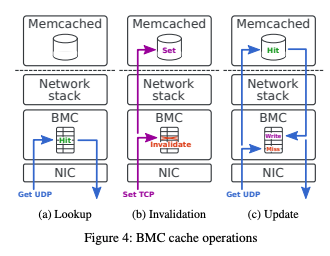
- 查询:在 eBPF 程序中查到缓存直接返回,不走网络协议栈和用户态
- 失效:将 BMC 和 Memcached 中的缓存都设置失效
- 更新:将 BMC 和 Memcached 中的缓存都进行更新
BMC 处理也被叫做 Pre-stack processing 技术。
此处抛砖引玉一下,假设 OBProxy 和 OBServer 部署在一台机器:
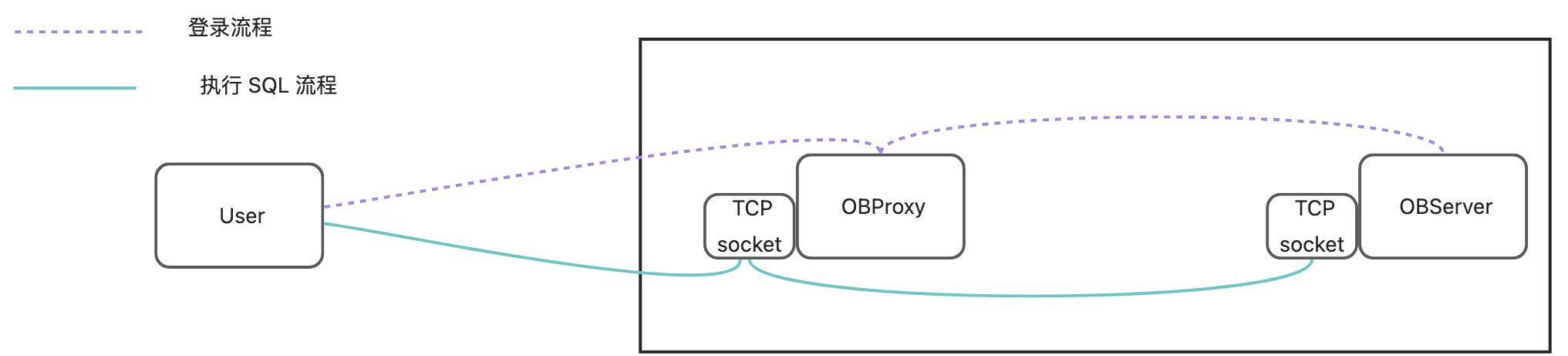
紫色虚线表示登录流程,通过 OBProxy 处理登录请求,从而确定访问的 OBServer 机器。登录成功后,我们就有了客户端连接和服务端连接的映射关系,通过 Map 传递给 eBPF 程序。绿色部分是执行 SQL 流程,执行过程直接在内核态进行转发,将 SQL 放到 OBServer 的 socket 中,这样就绕开了冗余的 TCP 协议栈处理和 OBProxy 处理,性能会得到提升。
其它:基于 DPDK 优化 TCP 协议栈也是一个性能优化方向。用户态代码相对 eBPF 技术门槛可能会低一些。
安全
基于 eBPF 也可以做很多安全方面事情。
白名单功能
文章最开始部分就是最简单的白名单功能。真正可用还需要更多控制信息确定报文行为,如基于白名单配置拦截特定 IP 的报文,主要优势是性能更好。
linux 自带的工具 iptables/netfilter 都可以提供白名单功能,iptables 常常和 ipset 结合使用,设置一些 IP 地址黑名单,防御 DDOS(distributed denial-of-service)网络攻击。对于 DDOS 这样的网络攻击,更早地丢包,就能更好地缓解 CPU 的损耗。但是用 iptables 作为防 DDOS 攻击的手段,效果往往很差。是因为 iptables 基于 netfilter 框架实现,即便是攻击报文在 netfilter 框架 PREROUTING 的 hook 点(收包路径的最早 hook 点)丢弃,也已经走过了很多 Linux 网络协议栈的处理流程。网上有比较数据,利用 XDP 技术的丢包速率要比 iptables 高 4 倍左右。
字节跳动基于 eBPF 技术实现了高性能ACL ,原理如下:
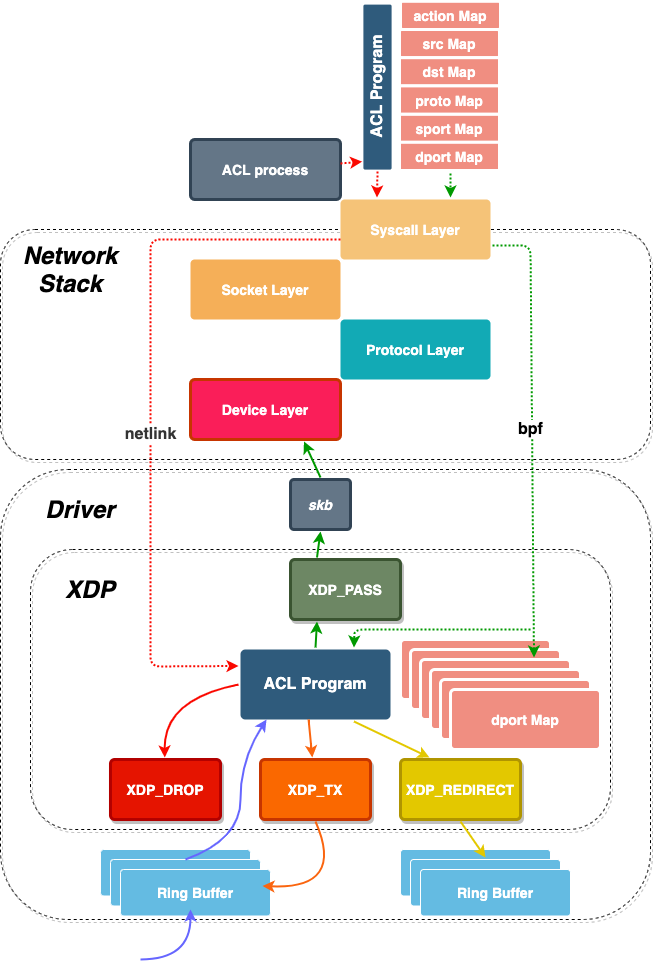
ACL 控制平面负责创建 eBPF 的 Program、Map,注入 XDP 处理流程中。其中 eBPF 的 Program 存放报文匹配、丢包等处理逻辑,eBPF 的 Map 存放 ACL 规则。参考文章 https://blog.csdn.net/ByteDanceTech/article/details/106632252
这里也可以看到程序实现思路:用户态程序实现控制面逻辑,eBPF 实现数据面逻辑。
登录审计
基于 eBPF 程序,我们可以记录所有访问特定端口如 2883 的连接。bcc 工具集合中的 tcpaccpt 实现了该功能。
防 DDos 攻击
使用 eBPF 程序,我们可以记录特定 IP 的访问流量,当流量异常时,我们可以选择丢弃报文、延迟发送等,基于 tc 类型程序可以很好的做好网络控制。
总结
根据前面介绍,eBPF 核心优势如下:
- 全覆盖:可以在内核和应用程序插桩分析问题
- 无侵入:不需要修改任何被 hook 的代码
- 可编程:有了编程能力,就可以实现各种业务逻辑,让一切皆有可能
eBPF 是一种非常强大的技术,近几年也在快速发展,并有很多的最佳实践和明星项目出现,未来会发挥更大作用。我们需要利用 eBPF,在观测、网络等部分发力,享受技术红利。
参考链接
https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/xdp-drop-ebpf.c
https://yuque.antfin-inc.com/qe7tfv/gf2vxx/iatkvc4dz65ail80
https://arthurchiao.art/blog/cilium-bpf-xdp-reference-guide-zh/#ubuntu
https://docs.cilium.io/en/latest/bpf/