本文地址:https://www.ebpf.top/post/ebpf_network_exporter
公有云网络问题,是一个老生常谈的事情了。今天主要简单说明下,在内网环境下去分析 & 定位这个问题。也并不是一开始就需要 eBPF 加持的,可以从简单的基础工具到监控配合去相关比较快速的定位问题,解决问题。下面会从发现问题到一步步配合使用 Or 开发一些简单的东西去解决问题的大致思路。
常见的网络相关问题
- 业务负载不均衡:业务系统会越发的复杂,不可能单个服务承接所有流量,一定会逐步迭代为一组服务承接流量,那我们是可以先用一些负载均衡组件去解决这个问题(不推荐一上来就喊,我要自研,图啥呢?),可以使用 HaProxy、Nginx 配合公有云的弹性能力去解决问题。伴随着业务的发展慢慢的当全站使用 K8s 的时候,还会遇到 Kube-Proxy 存在负载不均衡的问题,这个时候就可以应入 Envoy 到最终上线 Istio 去解决问题,做到内部服务的负载均衡(当然服务的健康检查 & 优雅停止需要考虑下)。配合边缘公有云 LB 做入流量控制,到 Kong 这种非常自动化的网关来解决业务整个边缘路由的分流能力。至此 xLB + Kong/Openresty/Apisix/Envoy + Istio(Evnoy) 基本上已经到了天花板了。(应该还有更优的)
- 网络异常抖动:日常会发生抖动的情况大致有几种情况吧。服务间异常、交换机过载、存储系统异常、业务系统 Bug,如上问题都需要专业的同学去帮助解决,并不能也不是每次都是网工的锅是吧。
- 网络延时增大:抛开业务系统问题,Slow Query、Big Key、Hot Key、消费生产(消息队列)延时等问题的话。那只能朝着网络层面去找问题了。(你想,交换机里面也有 CPU)举一个例子,家里 Wifi 为什么没啥人用也会卡,有一个东西叫信道,就好比虽然有很多信道但是呢流量都在一个信道里面跑(1个人干活,一群人看)能不卡吗?(应该能解的,这个就不懂了,不懂不捣乱)
如何定位
Istio
- Istio 监控指标里面其实已经可以发现服务链路之间的调用的情况了,就是会发现为什么有些快有些慢呢,在排除 xDS(服务发现、路由下发等,Envoy API 与 Pilot 交互) 的问题后(其实没几家公司可以触发 Istio 的 Bug 的),依然慢的莫名其妙。
Ping
- 这个是一个好东西哦,简单看看绝对富裕了。闲来无事基于 ping_exporter 加了一个 RESTful API,这样想 Ping 哪里 Ping 哪里,如果需要 K8s 里面互相 Ping 的话,其实只要依靠 K8s API 做自发现 Node 互 Ping 就能一目了然的发现很多问题了(原来网络真的很糟糕)
eBPF
- eBPF(extended Berkeley Packet Filter) 是一种可以在 Linux 内核中运行用户编写的程序,而不需要修改内核代码或加载内核模块的技术。简单说,eBPF 让 Linux 内核变得可编程化了。eBPF 程序是一个事件驱动模型。Linux 内核提供了各种 hook point,比如 system calls, function entry/exit, kernel tracepoints, network events 等。eBPF 程序通过实现想要关注的 hook point 的 callback,并把这些 callback 注册到相应的 hook point 来完成“内核编程”。
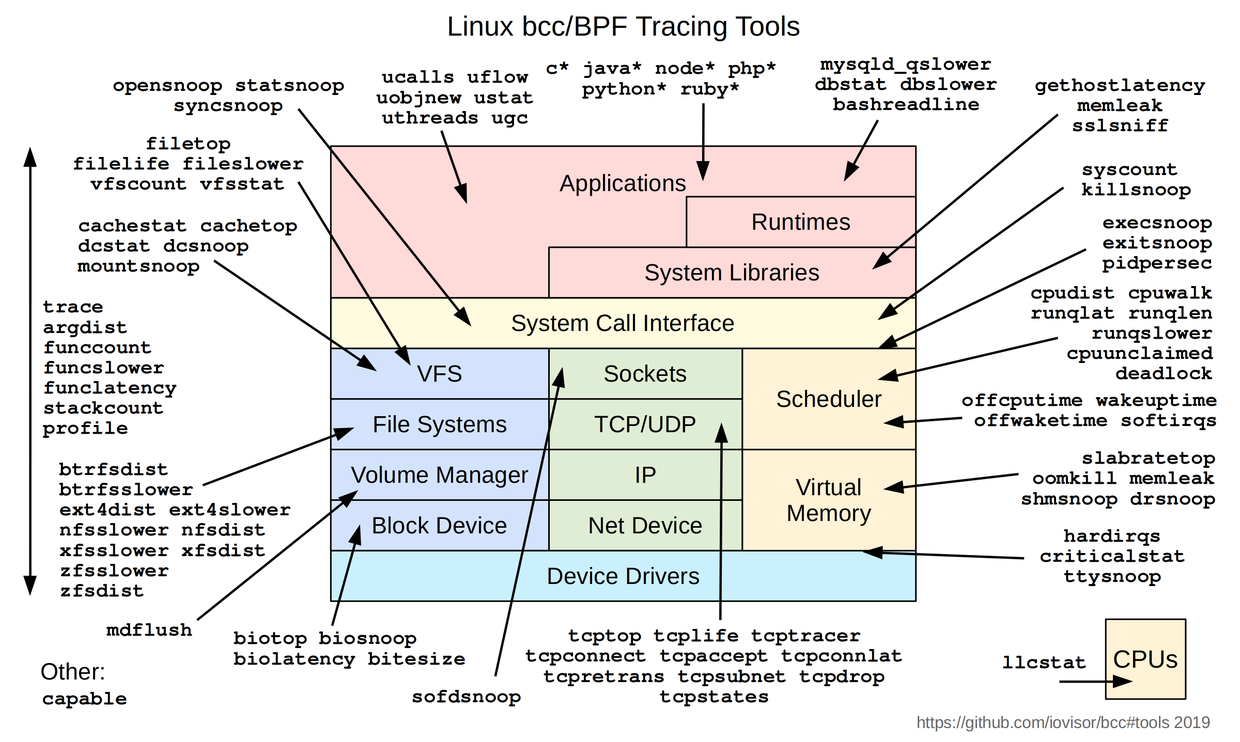
- bcc 是一个基于 eBPF 的工具包,内部包装了 LLVM。你可以用 C 语言 + Python、Lua 等高级语言编写 eBPF 程序,同时还提供了不少有用的工具。BCC是一个用于跟踪内核和操作程序的工具集,其软件包中包含了一些有用的工具和例子,它扩展了BPF(Berkeley Packet Filters),通常被称为eBPF , 在Linux3.15中首次引入,但大多数BCC的功能需要Libux4.1及以上版本。(可以话时间研究下下的,基础功能 & BPF 代码里面多有)
- bpftrace 是一门基于 eBPF 的高级追踪语言,可以方便快捷地编写 Linux 追踪程序。
- 工作原理:eBPF 通过 C 语言自由扩展(这些扩展通过 LLVM 转换为 BPF 字节码后,加载到内核中执行。从图中你可以看到,eBPF 的执行需要三步:从用户跟踪程序生成 BPF 字节码;加载到内核中运行;向用户空间输出结果。
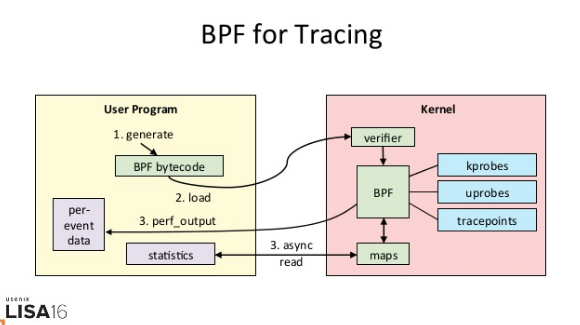
- 实际上,在 eBPF 执行过程中,编译、加载还有 maps 等操作,对所有的跟踪程序来说都是通用的。把这些过程通过 Python 抽象起来,也就诞生了 BCC(BPF Compiler Collection)。
- BCC 把 eBPF 中的各种事件源(比如 kprobe、uprobe、tracepoint 等)和数据操作(称为 Maps),也都转换成了 Python 接口(也支持 lua)。这样,使用 BCC 进行动态追踪时,编写简单的脚本就可以了。
- 不过要注意,因为需要跟内核中的数据结构交互,真正核心的事件处理逻辑,还是需要我们用 C 语言来编写。
cloudflare/ebpf_exporter
-
Prometheus exporter for custom eBPF metrics. 非常棒的一个项目,在与 K8s 结合的时候,以 DaemonSet 的形式运行在集群中,可借鉴 kube-ebpf-exporter。
-
依据 Bcc Tools tcpconnlat,配合 ebpf_exporter 的改写如下(ebpf_exporter 例子中没有网络延时相关的)
-
programs: # See: # * https://github.com/iovisor/bcc/blob/master/tools/tcpconnect.py # * https://github.com/iovisor/bcc/blob/master/tools/tcpconnlat_example.txt - name: tcpconnlat metrics: counters: - name: tcpconnlat_ipv4 help: tcp4 connection latency(ms) table: ipv4_events labels: - name: pid size: 4 decoders: - name: uint - name: sst_addr size: 4 decoders: - name: inet_ip - name: dst_addr size: 4 decoders: - name: inet_ip - name: lst_port size: 2 decoders: - name: uint - name: dst_port size: 2 decoders: - name: uint - name: proc_name size: 16 decoders: - name: string kprobes: tcp_rcv_state_process: trace_tcp_rcv_state_process tcp_v4_connect: trace_connect code: | #include <uapi/linux/ptrace.h> #include <net/sock.h> #include <net/tcp_states.h> #include <bcc/proto.h> struct info_t { u64 ts; u32 pid; char task[TASK_COMM_LEN]; }; BPF_HASH(start, struct sock *, struct info_t); // separate data structs for ipv4 struct ipv4_data_t { u32 pid; u32 saddr; u32 daddr; u16 lport; u16 dport; char task[TASK_COMM_LEN]; }; BPF_HASH(ipv4_events, struct ipv4_data_t); int trace_connect(struct pt_regs *ctx, struct sock *sk) { u32 pid = bpf_get_current_pid_tgid(); struct info_t info = {.pid = pid}; info.ts = bpf_ktime_get_ns(); bpf_get_current_comm(&info.task, sizeof(info.task)); start.update(&sk, &info); return 0; }; // See tcp_v4_do_rcv(). So TCP_ESTBALISHED and TCP_LISTEN // are fast path and processed elsewhere, and leftovers are processed by // tcp_rcv_state_process(). We can trace this for handshake completion. // This should all be switched to static tracepoints when available. int trace_tcp_rcv_state_process(struct pt_regs *ctx, struct sock *skp) { // will be in TCP_SYN_SENT for handshake if (skp->__sk_common.skc_state != TCP_SYN_SENT) return 0; // check start and calculate delta struct info_t *infop = start.lookup(&skp); if (infop == 0) { return 0; // missed entry or filtered } u64 ts = infop->ts; u64 now = bpf_ktime_get_ns(); u64 delta_us = (now - ts) / 1000ul; u64 delta_ms = delta_us / 1000; #ifdef MIN_LATENCY if ( delta_us < DURATION_US ) { return 0; // connect latency is below latency filter minimum } #endif // pull in details u16 family = 0, lport = 0, dport = 0; family = skp->__sk_common.skc_family; lport = skp->__sk_common.skc_num; dport = skp->__sk_common.skc_dport; // emit to appropriate data path if (family == AF_INET) { struct ipv4_data_t data4 = {.pid = infop->pid}; data4.saddr = skp->__sk_common.skc_rcv_saddr; data4.daddr = skp->__sk_common.skc_daddr; data4.lport = lport; data4.dport = ntohs(dport); __builtin_memcpy(&data4.task, infop->task, sizeof(data4.task)); ipv4_events.increment(data4, delta_ms); } start.delete(&skp); return 0; }
基于上面一轮干下来,基本上哪里慢,为什么慢,怎么慢也就差不多定位了。剩下么,该干嘛干嘛。记得调用链还是非常有用的哦,配合网络监测 + 调用链,问题自然而然的就暴露啦(当然调用链接入姿势是另外一个问题啦)
最后推荐几本书吧,BPF之巅:洞悉Linux系统和应用性能 & Linux内核观测技术BPF。
原文地址:基于 eBPF 的网络检测实践
- 原文作者:孙文杰
- **原文链接:**https://www.ebpf.top/post/ebpf_network_exporter/
- **版权声明:**本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。