本文主要用于演示基于 ebpf 技术来实现对于系统调用跟踪和特定条件过滤,实现基于 BCC 的 Python 前端绑定,过程中对于代码的实现进行了详细的解释,可以作为学习 ebpf 技术解决实际问题的参考样例。
1. 样例代码
#include <stdio.h>
#include <unistd.h>
int main() {
FILE *fp; char buff[255];
printf("Pid %d\n", getpid());
fp = fopen("./hello.c", "r");
fscanf(fp, "%s", buff);
printf("Read: [%s]\n", buff );
getchar();
fclose(fp);
return 0;
}
fopen 函数是 glibc 库中的函数,可在 github 上找到 mirror 地址,最终是通过系统调用 open 来实现内核中打开文件的功能。
2. /proc 目录下的 fd
在 hello 在运行状态时,通过查看 /proc/pid/fd 可以获取到文件当前打开的文件句柄:
# ls -hl /proc/`pidof hello`/fd total 0 lrwx------ 1 root root 64 May 30 16:31 0 -> /dev/pts/0 lrwx------ 1 root root 64 May 30 16:31 1 -> /dev/pts/0 lrwx------ 1 root root 64 May 30 16:31 2 -> /dev/pts/0 lr-x------ 1 root root 64 May 30 16:31 3 -> /root/sys_call/hello.c
如果将 getchar 调整到 fclose 的下方:
int main() {
// ...
fclose(fp);
// 先关闭文件句柄
getchar();
return 0;
}
我们再去查看 /proc 目录下进程对应的 fd则无法展示出已经关闭的文件相关信息。
# ls -hl /proc/`pidof hello`/fd total 0 lrwx------ 1 root root 64 May 30 16:34 0 -> /dev/pts/0 lrwx------ 1 root root 64 May 30 16:34 1 -> /dev/pts/0 lrwx------ 1 root root 64 May 30 16:34 2 -> /dev/pts/0
Linux 提供的
lsof工具的实现原理也是遍历进程对应的/proc/pid/fd文件实现的。
这是因为 /proc/pid/fd 给我们展示的是查看目录时的文件打开的最终快照。如果我们对于某组特定进程持续跟踪文件打开的记录和结果,特别是进程频繁创建销毁的场景下,通过 /proc 文件进行查看的方式则不能够满足诉求,这时我们需要一种新的实现方式,能够帮我们实现以下功能:
- 许多对于进程运行过程中的所有文件打开记录和状态进行跟踪
- 对于频繁创建销毁的进程也能够实现跟踪
- 能够基于更多维度进行跟踪,比如进程名或者特定的文件
Linux 内核中的 eBPF 技术,可通过跟踪内核中文件打开的系统调用通过编程的方式实现。
3. 使用 eBPF 实时跟踪文件记录
在真正进入到 eBPF 环节之前,我们需要简单复习一些系统调用的基础知识。
3.1 系统调用(syscall)
在 Linux 的系统实现中,分为了用户态和内核态。用户态的程序工作在较低级别的状态,操作系统提供的核心服务工作在高级别的内核态,从而避免用户应用程序破坏系统的正常运行,实现了用户级别的隔离。
为了方便用户态的程序访问到操作系统内核态的功能,操作系统提供了系统调用层。用户态的程序用过系统调用来访问操作系统内核态功能,从而从用户态转向级别更高的内核态,一般情况下应用程序并不会直接访问系统调用,而是通过 glibc 库提供函数实现的,例如库中的 open 函数对应到系统调用中 sys_open 函数。截止到 Linux 5.4 版本内核,64 位操作系统中大概有 547 个系统调用,具体参见syscall_64.tbl。
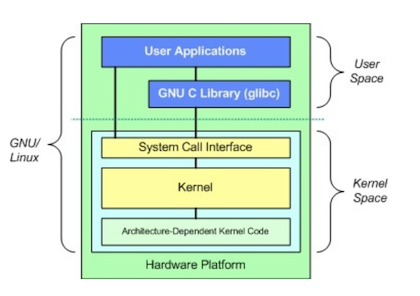
3.2 eBPF 系统调用跟踪
eBPF 对于系统调用的底层支持采用的是 kprobe 机制,kprobe 是针对内核函数跟踪的一种机制。由于原始的 eBPF 编程是基于 Linux C 语言的,入门的门槛比较高,开源项目 BCC 提供了更高的抽象,BCC 支持 Python、Lua 和 C++ 等高级语言,这大大降低了编程的门槛。本样例我们使用采用 Python 语言编写(基于 BCC)。代码运行前,需要提前安装 BCC 项目,安装方式参见 INSTALL.md。
3.3 open 系统调用跟踪
open_ebpf.py 程序基于 eBPF 开源项目 BCC 中的 Python 框架搭建,运行时会将系统中所有程序调用 open 函数的记录打印出来。
#!/usr/bin/python from bcc import BPF prog = """ int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) { u32 pid = bpf_get_current_pid_tgid() >> 32; u32 uid = bpf_get_current_uid_gid(); bpf_trace_printk("%d [%s]\\n", pid, filename); return 0; } """ b = BPF(text=prog) b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open") try: b.trace_print() except KeyboardInterrupt: exit()
程序运行结果如下:
# ./open_ebpf.py AliYunDun-1732 [012] d... 11761.163446: : 1732 [/var/log/secure] CmsGoAgent.linu-931 [010] d... 11761.259430: : 722 [/proc/loadavg]
代码详解:
-
from bcc import BPF该行为从 bcc 的 Python 库导入 BPF 包; -
prog = ‘’‘ xxx ’‘’该变量为需要编写的 eBPF 程序,为 C 语言代码,常见函数参见 reference_guide;-
trace_syscall_open函数原型为sys_open函数在内核中的定义原型,其中第一个参数struct pt_regs *ctx为 BPF 程序需要添加的上下文变量,后续参数参见sys_open。 -
asmlinkage long sys_open(const char __user *filename, int flags, umode_t mode);
-
- `bpf_trace_printk` 为简单的调试方式,输出到文件 `/sys/kernel/debug/tracing/trace_pipe` 中,最大只允许 3 个参数,而且只运行一个 `%s` 的参数;另外 `trace_pipe` 是所有共享的,这也可能导致输出会冲突,应尽量采用 BPF_PERF_OUTPUT() 的方式,此处只是用于演示功能使用。
-
b = BPF(text=prog)使用我们定义的prog初始化 BPF 对象 b; -
b.attach_kprobe是将我们定义的跟踪函数与系统调用open函数进行关联;b.get_syscall_fnname("open")是提供的便利函数,可以获取到 syscall 对应的函数名,底层源码为 c++ 实现。
-
b.trace_print()则是读取bpf_trace_printk的输出,并打印;
另外还有一种简便的使用方式,声明函数的时候使用特定的前缀和函数名,此种约定就可以省略
b.attach_kprobe显示的使用,例如:prog = """ int syscall_open(struct pt_regs *ctx, const char __user *filename,int flags) { // ... } """ // 上述按照特定格式约定了,此处的 attach_kprobe 就不再需要调用 // b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open")函数名的组成为 ”类型“ + 内核函数的方式,
syscall,表示类型是syscall,跟踪的函数是open,需要注意的是syscall与open之间为两个连续的下划线。相对应的类型还有kprobe/kretprobe等。详情参见这里。
3.4 支持 PID 过滤版本
为了方便统计特定进程的文件打开情况,我们还需要增强为支持按照 PID 过滤的功能。
open_pid_ebpf.py 在上述版本的基础上增加了命令行输入 PID 和底层 eBPF 程序支持 PID 过滤的功能。
#!/usr/bin/python from bcc import BPF import argparse # +add prog = """ int trace_syscall_open(struct pt_regs *ctx, const char __user *filename, int flags) { u32 pid = bpf_get_current_pid_tgid() >> 32; u32 uid = bpf_get_current_uid_gid(); PID_FILTER // + add PID FILTER bpf_trace_printk("%d [%s]\\n", pid, filename); return 0; } """ examples = """examples: ./open_pid_ebpf -p 181 # only trace PID 181 """ parser = argparse.ArgumentParser( description="Trace open() syscalls", formatter_class=argparse.RawDescriptionHelpFormatter, epilog=examples) parser.add_argument("-p", "--pid", help="trace this PID only") args = parser.parse_args() if args.pid: prog = prog.replace('PID_FILTER', 'if (pid != %s) { return 0; }' % args.pid) else: prog = prog.replace('PID_TID_FILTER', '') b = BPF(text=prog) b.attach_kprobe(event=b.get_syscall_fnname("open"), fn_name="trace_syscall_open") try: b.trace_print() except KeyboardInterrupt: exit()
运行结果如下:
# ./open_pid.py -p 4214 # hello pid hello-4214 [003] d... 11693.160177: : 4214 [./hello.c]
3.5 后续程序增强
- 目前只是使用
bpf_trace_printk进行了打印,生产中的跟踪程序应采用BPF_PERF_OUTPUT的方式。 - 当前只是支持了 PID 过滤,可以提供更加丰富的过滤条件,比如支持 TID,filename和 cmd 等多维度。
- 基于
kprobe机制对于函数的入口进行了跟踪,还可以基于kretporbe对于函数返回的结果进行跟踪。 - 打开文件的方式并不仅仅只有
open函数,还有openat和openat2等函数,也需要统一支持,才能涵盖所有的路径,参见这里。
BCC 中的 opensnoop.py 已经实现了上述的各种功能,可以作为我们自己编写的参考。
此处我们只是为了展示如何使用 eBPF 进行功能开发,实现了对于 open 系统调用跟踪和基于 PID de 过滤,麻雀虽小五脏俱全,我们可以很容易基于此样例进行扩展,实现我们个性化定制的跟踪。
实际上 BCC 中已经包含了大多数场景下使用的工具,例如实现功能更加丰富的 opensnoop.py,能够满足对于文件访问跟踪的大多数场景。opensnoop 的样例如下:
./opensnoop # trace all open() syscalls ./opensnoop -T # include timestamps ./opensnoop -U # include UID ./opensnoop -x # only show failed opens ./opensnoop -p 181 # only trace PID 181 ./opensnoop -t 123 # only trace TID 123 ./opensnoop -u 1000 # only trace UID 1000 ./opensnoop -d 10 # trace for 10 seconds only ./opensnoop -n main # only print process names containing "main" ./opensnoop -e # show extended fields ./opensnoop -f O_WRONLY -f O_RDWR # only print calls for writing ./opensnoop --cgroupmap mappath # only trace cgroups in this BPF map ./opensnoop --mntnsmap mappath # only trace mount namespaces in the map
4. 参考
-
How to turn any syscall into an event: Introducing eBPF Kernel probes
-
原文作者:DavidDi
-
**版权声明:**本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。