本文内容简介
本文首先向大家简单介绍在学习P4过程中需要用到的工具。本文的主要特色是让对P4感兴趣的大家不费吹灰之力的在工作,学习之余,快速搭建完善的P4实验环境并开始第一个P4实验。本文的更新日期是2018年10月8日,使用相对于大多数教程来说较新的P4环境,本文提供两种搭建环境的方法,它们的特点如下:
- 虚拟机安装:一个完整的p4教学环境,无需手动搭建环境。
- 优点: 方便,快捷,对操作系统没什么要求。
- 缺点:运行较慢。
- 如果工作环境没有Linux系统,建议使用VM。
- 真机搭建:
- 优点:运行速率快,环境较新。
- 缺点:可能会遇到错误,需要一个ubuntu系统。
- 不用担心费神的环境搭建,本文将提供一个一键搭建环境的脚本。这个脚本通过了我多次测试。
实验环境介绍
- 操作系统: Ubuntu 16.04 LTS 64位 桌面版
- python : 2.7.12
- 推荐内存: 4G 以上
各个组件简介
主要需要安装5个组件:
- bmv2
- p4c
- mininet
- p4-tutorial
- PI
首先要明白他们各自的作用【图片来源于p4.org】:
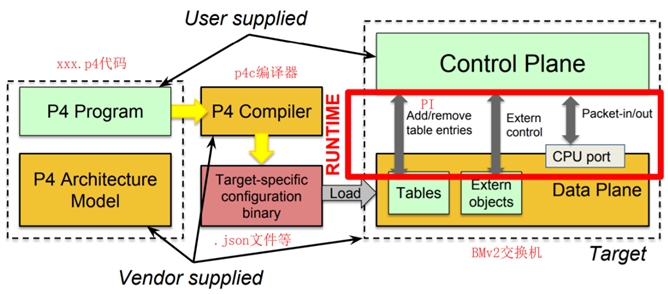
如图,我们写好xxx.p4代码,通过 p4c 这个 p4 compiler 将p4代码编译成为p4交换机可以理解的各种”机器代码”。如果目标交换机是 bmv2 , 那么p4c将生成 .json文件。
- p4c是一款 p4编译器。
- BMv2是支持P4编程的软件交换机。
- PI是P4 runtime的实现,用于Control Plane对数据平面的控制。
- mininet的功能是构建一个虚拟的网络拓扑。 它通过linux内核的一些特性(net命名空间),在一个主机上划分出多个虚拟网络空间,各个网络空间之间相互隔离,有自己的端口, ip等等。mininet让一个或者多个vhost(虚拟主机), 软件交换机(如ovs, bmv2)等 以进程的状态分别绑定在这些网络空间之中,共同构成一个进程级别的虚拟网络拓扑。需要注意的是这些进程级别的主机和交换机他们只是网络上的隔离,而文件系统则是共享主机的文件系统。
- p4 tutorials 提供了用于学习的实例代码,它提供了很多个带有方向性的实际场景,例如负载均衡,简单的隧道机制,源路由等。并且它事先写好了控制面代码,让p4的初学者可以集中注意力在数据面编程的学习之上。
- scapy是一个python库,提供构建数据包,抓包,解析包等功能。它功能强大,但是效率很低。由于P4编程中经常会引入各种各样的数据包,有些甚至是开发者自定义的数据包格式。所以我们可以利用scapy进行便捷的组包,发包。如果需要高速率的发包和解析包就不能使用scapy了。
搭建环境
搭建环境有两条路可以走:
- 使用环境健全的虚拟机,如果朋友们手边没有linux环境,或者希望快速上手开发,建议采取这种方式。
- 在真机中(我这里时Ubuntu16.04)搭建。建议环境与我相同,否则可能会出现各种意想不到的问题。
方法一: 虚拟机套件
- 官方提供了用于学习的虚拟机,里面有完整的环境。可以尝试访问官网链接,翻墙警告。如果不能访问外网,可以尝试访问我这个1Core, 1M带宽的服务器[资源](ftp://118.25.136.129/hox/P4 Tutorial 2018-06-01.ova)
- 官方的环境似乎比较陈旧,我利用方法二在虚拟机中搭建了一个环境,并且导出供大家使用,下面是下载链接:
- FTP服务器下载, 这个是一个云主机,如果过期或者服务器崩溃, 联系我去修复。
- 如果FTP服务器崩溃,建议自己装一个Ubuntu16.04的虚拟机,然后调用方法二,其实也很简单。
- 这里还有一个腾讯微云的链接: https://share.weiyun.com/581m3WN
方法二: 真机搭建
真机搭建需要获得各个组件的源码,然后编译安装,可能遇到各个组件之间的版本兼容性,依赖性等问题。
本来打算一步一步写出手动搭建的步骤,但过程比较痛苦,为了防止让大家陷入搭建环境这种苦涩且收益不大的环节,本文按照p4 tutorials中vagrant用于构建虚拟机环境的脚本,进行了适当修改后,最终改成一个搭建真机P4实验环境的脚本。通过这个脚本,可以方便的让大家搭建好P4学习环境,该脚本通过了本人多次测试。
建议在网络环境较好的环境下执行脚本,如果能使用国外的代理就更好了,如果网速较慢,建议晚上睡觉前执行,然后天亮后再瞅瞅,毕竟国内访问github有时真的太慢了。
相关脚本已经上传至p4-quick 。
在搭建之前
为了不破坏原环境的整洁性,我们还是在home目录下创建一个P4的工作目录,并且加入环境变量:
mkdir ~/P4
cd ~/P4
echo "P4_HOME=$(pwd)" >> ~/.bashrc
source ~/.bashrc
在运行脚本之前,先核实一下必要的环境和依赖:
- 发行版: Ubuntu 16.04 Desktop LTS , 通过
lsb_release -a查看。 - Python: 2.7.12, 通过
python --version查看。 - 内核: 4.15.0-29-generic , 通过
uanme -a查看,差不多即可。
开始搭建
先安装一些依赖:
sudo apt-get update
sudo apt-get install automake cmake libjudy-dev libpcap-dev libboost-dev libboost-test-dev libboost-program-options-dev libboost-system-dev libboost-filesystem-dev libboost-thread-dev libevent-dev libtool flex bison pkg-config g++ libssl-dev -y
sudo apt-get install cmake g++ git automake libtool libgc-dev bison flex libfl-dev libgmp-dev libboost-dev libboost-iostreams-dev libboost-graph-dev llvm pkg-config python python-scapy python-ipaddr python-ply tcpdump curl -y
sudo apt-get install libreadline6 libreadline6-dev python-pip -y
sudo pip install psutil
sudo pip install crcmod
然后创建一个文件,用于存放搭建环境的脚本:
cd $P4_HOME
touch env_up.sh
chmod +x env_up.sh
然后将以下内容,复制到 env_up.sh文件当中:
#!/bin/bash
##############################################################
# author : P4 Lang
# modified by: SEU Hox Zheng
##############################################################
# 打印脚本命令.
set -x
# 在有错误输出时停止.
set -e
# 设置相关路径和版本变量
P4_HOME=$HOME/P4
BMV2_COMMIT="7e25eeb19d01eee1a8e982dc7ee90ee438c10a05"
PI_COMMIT="219b3d67299ec09b49f433d7341049256ab5f512"
P4C_COMMIT="48a57a6ae4f96961b74bd13f6bdeac5add7bb815"
PROTOBUF_COMMIT="v3.2.0"
GRPC_COMMIT="v1.3.2"
#获得cpu核数,与某些软件的编译选项相关
NUM_CORES=`grep -c ^processor /proc/cpuinfo`
cd $P4_HOME
# 安装Mininet
git clone git://github.com/mininet/mininet mininet
cd mininet
sudo ./util/install.sh -nwv
cd ..
# 安装Protobuf
git clone https://github.com/google/protobuf.git
cd protobuf
git checkout ${PROTOBUF_COMMIT}
export CFLAGS="-Os"
export CXXFLAGS="-Os"
export LDFLAGS="-Wl,-s"
./autogen.sh
./configure --prefix=/usr
make -j${NUM_CORES}
sudo make install
sudo ldconfig
unset CFLAGS CXXFLAGS LDFLAGS
# force install python module
cd python
sudo python setup.py install
cd ../..
# 安装gRPC
git clone https://github.com/grpc/grpc.git
cd grpc
git checkout ${GRPC_COMMIT}
git submodule update --init --recursive
export LDFLAGS="-Wl,-s"
make -j${NUM_CORES}
sudo make install
sudo ldconfig
unset LDFLAGS
cd ..
# Install gRPC Python Package
sudo pip install grpcio
# 安装BMv2的依赖,下面PI编译时会用到。
git clone https://github.com/p4lang/behavioral-model.git
cd behavioral-model
git checkout ${BMV2_COMMIT}
# From bmv2's install_deps.sh, we can skip apt-get install.
# Nanomsg is required by p4runtime, p4runtime is needed by BMv2...
tmpdir=`mktemp -d -p .`
cd ${tmpdir}
bash ../travis/install-thrift.sh
bash ../travis/install-nanomsg.sh
sudo ldconfig
bash ../travis/install-nnpy.sh
cd ..
sudo rm -rf $tmpdir
cd ..
# PI/P4Runtime
git clone https://github.com/p4lang/PI.git
cd PI
git checkout ${PI_COMMIT}
git submodule update --init --recursive
./autogen.sh
./configure --with-proto
make -j${NUM_CORES}
sudo make install
sudo ldconfig
cd ..
# 安装Bmv2
cd behavioral-model
./autogen.sh
./configure --enable-debugger --with-pi
make -j${NUM_CORES}
sudo make install
sudo ldconfig
# Simple_switch_grpc target
cd targets/simple_switch_grpc
./autogen.sh
./configure --with-thrift
make -j${NUM_CORES}
sudo make install
sudo ldconfig
cd ..
cd ..
cd ..
# 安装P4C,省去了check步骤(太费时间了)
git clone https://github.com/p4lang/p4c
cd p4c
git checkout ${P4C_COMMIT}
git submodule update --init --recursive
mkdir -p build
cd build
cmake ..
make -j${NUM_CORES}
sudo make install
sudo ldconfig
cd ..
cd ..
# 最后获得p4 tutorials
git clone https://github.com/p4lang/tutorials
保存退出脚本,然后执行这个脚本:
./env_up.sh
脚本开始自动为你搭建环境,如果中途遇到错误,脚本会中断,如果脚本顺利执行,那么脚本结束后,环境便搭建好了。
进行第一个实验
进行实验之前
如果你下载的是本文提供的第二种虚拟机,或者通过脚本安装了P4环境,现在P4目录下面应该是这个样子:
P4
├── behavioral-model ## BMv2 软件交换机
├── grpc ## 作为BMv2的依赖
├── mininet ## mininet 网络仿真
├── p4c ## p4c 编译器
├── PI ## PI P4 runtime库
├── protobuf ## 作为依赖
└── tutorials #### 教程目录,以及以后主要的学习,实验
我们主要的工作目录时tutorials,其余的都是被使用的工具组件。细看tutorials:
tutorials/
├── exercises # 存放各种练习
├── utils # 工具脚本目录
└── vm # 用于vagrant构建虚拟机的目录,可以无视
其中utils里面存放了一些用于调用各个组件(mininet, bmv2, PI, p4c)的脚本,有了这些脚本,我们可以专注于p4代码的开发,控制面的编写,以及拓扑的构建,而不需要费神去了解bmv2的启动命令,p4c的调用选项等等。具体如何使用,也是非常的简单,我们进入一个具体的例子查看:
# 我们切换进入 exercises/basic 这个例子
basic
├── basic.p4 # 要编写的p4代码
├── build # 生成文件的目录
├── logs # 日志文件, 在调试的时候真的非常重要!
├── Makefile ### 通过Makefile 来调用utils下的脚本!
├── pcaps # 生成的pcap包,可以使用wireshark等工具来分析
├── README.md # 详细的指导
├── receive.py ## 利用scapy写的抓取和分析数据包的工具
├── s1-runtime.json #
├── s2-runtime.json # 在运行同时加载入交换机的控制面代码,这里有争议,稍后再谈
├── s3-runtime.json #
├── send.py ## 利用scapy写的构建和发送数据包的工具
├── solution # 这里有这个例子的示例代码(答案)
└── topology.json # 描述拓扑的json文件
可以看到,通过Makefile,我们可以调用utils下的脚本,让我们的p4代码跑起来:
make run # 启动命令
### ...启动过程中的输出
mininet> # mininet 命令行
### ... 你的一些实验操作
mininet> exit # 退出mininet 命令行
make clean # 清理上次运行留下的缓存文件和遗留的进程,重要,否则下次运行会可能使用旧的代码。
调用make run,我们可以运行当前目录下(以basic目录为例)的代码,它将执行以下几个步骤:
- 编译basic.p4 代码,生成basic.json
- 解析topology.json, 并且构建相应的mininet仿真拓扑,按照该拓扑启动一台或者多台BMv2交换机,以及一些host
- 启动BMv2的同时会将p4代码编译产生的json文件导入
- 启动BMv2后会解析 sN-runtime.json 文件,将其载入 交换机sN流表之中
- 进入mininet命令行,同时开始记录log以及搜集pcap文件
在新版本的tutorials中,载入静态流表项时采用了runtime方法,而非之前的CLI方法,我们查看一下s1-runtime.json的部分
....
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.1.1", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "00:00:00:00:01:01",
"port": 1
}
}
....
这是一个json文件,可以看到,其作用是定义一个个具体的流表项,标明了流表项所处的位置,匹配域,匹配模式,动作名,以及动作参数。这些字段都依赖于我们P4代码中所自定义的流表,匹配域和动作。
开始第一个实验basic
查看要实现的功能
查看README,里面这样介绍这个实验:
The objective of this exercise is to write a P4 program that
implements basic forwarding. To keep things simple, we will just
implement forwarding for IPv4.
...
可以看到这是一个实现转发功能的P4实例,文件剩余部分是进行实验具体的思路和指令,建议大家多多查阅README,以后就可以自己学习啦~
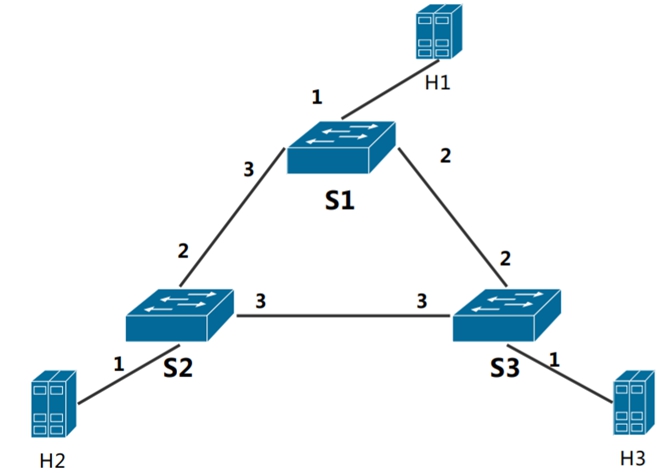
查看网络拓扑结构 topology.json:
{
"hosts": [
"h1",
"h2",
"h3"
],
"switches": {
"s1": { "runtime_json" : "s1-runtime.json" },
"s2": { "runtime_json" : "s2-runtime.json" },
"s3": { "runtime_json" : "s3-runtime.json" }
},
"links": [
["h1", "s1"], ["s1", "s2"], ["s1", "s3"],
["s3", "s2"], ["s2", "h2"], ["s3", "h3"]
]
}
清晰明了:这个拓扑中有3个switch,3个host,构成一个三角形的拓扑,注意到定义switches的时候,会定义载入到交换机的流表项文件”sN-runtime.json”。
了解大概之后,我们开始编写basic.p4代码:
回忆代码要实现的功能:ip_v4转发。我们需要完成的是tutorials中的TODO部分。
在代码的开头, 我们得知该代码是P4_16版本,使用的是我们之前谈到的v1_model。
/* -*- P4_16 -*- */
#include <core.p4>
#include <v1model.p4>
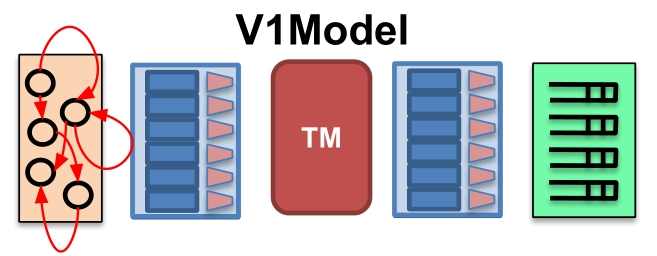
通过查看main回顾v1_model:
V1Switch(
MyParser(), // 解析数据包,提取包头
MyVerifyChecksum(), // 校验和验证
MyIngress(), // 输入处理
MyEgress(), // 输出处理
MyComputeChecksum(), // 计算新的校验和
MyDeparser() // 逆解析器
) main;
我们要需要完成以下几个基本的步骤,其余部分可以暂时省略。
- 定义相关数据结构:根据需求,我们需要定义 ipv4数据包头以及其下层的以太网包头结构。
- 解析数据包:我们在此提取ipv4包头。
- MyIngress:得到了数据包头,我们定义一个用于转发的流表,然后定义匹配域和动作。
- MyDeparser:逆解析器
- 写好控制面代码
定义数据结构:
header ethernet_t {
macAddr_t dstAddr; // macAddr_t 是 typedef bit<48> 的自定义类型
macAddr_t srcAddr;
bit<16> etherType;
}
header ipv4_t {
bit<4> version;
bit<4> ihl;
bit<8> diffserv;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
ip4Addr_t srcAddr;
ip4Addr_t dstAddr;
}
struct metadata {
/* 这个例子用不到metadata */
}
Parser 解析数据包
parser是一个有限状态机。从 start 状态开始,每一个状态便解析一种协议,然后根据低层协议的类型字段,选择解析高一层协议的状态,然后transition到该状态解析上层协议,最后transition到accept。具体如下:
parser MyParser(packet_in packet,
out headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
state start {
transition parse_ethernet; //转移到解析以太包头的状态
}
state parse_ethernet {
packet.extract(hdr.ethernet); //根据我们定义的数据结构提取以太包头
transition select(hdr.ethernet.etherType) { // 根据协议类型选择下一个状态
// 类似于switch
0x0800: parse_ipv4; //如果是0x0800,则转换到parse_ipv4状态
default: accept; // 默认是接受,进入下一步处理
}
state parse_ipv4 {
packet.extract(hdr.ipv4); //提取ip包头
transition accept;
}
}
}
Ingress
- 在Ingress中,我们要实现一个转发功能,因此需要定义一个用于转发的流表:
table ipv4_lpm {
key = { //流表拥有的匹配域
hdr.ipv4.dstAddr: lpm; // 匹配字段是数据包头的ip目的地址
// lpm 说明匹配的模式是 Longest Prefix Match,即最长前缀匹配
// 当然还有 exact(完全匹配), ternary(三元匹配)
}
actions = { //流表拥有的动作类型集合
ipv4_forward; //我们需要一个转发动作,这个需要稍后自定义
drop; // 丢弃动作
NoAction; // 空动作
}
size = 1024; //流表可以容纳多少流表项
default_action = drop(); // table miss 是丢弃动作
}
- 我们需要自己实现以下几个动作:
action drop() {
mark_to_drop(); //内置函数,将当前数据包标记为即将丢弃的数据包
}
action ipv4_forward(macAddr_t dstAddr, egressSpec_t port) {
//转发需要以下几个步骤
standard_metadata.egress_spec = port; //即将输出的端口从参数中获取,而参数需要由控制面传递
hdr.ethernet.srcAddr = hdr.ethernet.dstAddr; //原数据包的源地址改为目的地址
hdr.ethernet.dstAddr = dstAddr; //目的地址改为控制面传入的新的地址
hdr.ipv4.ttl = hdr.ipv4.ttl - 1; //ttl要减去1
}
Checksum 和 Deparser
这两个部分都有高度抽象的内置函数直接完成:
control MyComputeChecksum(inout headers hdr, inout metadata meta) {
apply {
update_checksum(
hdr.ipv4.isValid(),
{ hdr.ipv4.version,
hdr.ipv4.ihl,
hdr.ipv4.diffserv,
hdr.ipv4.totalLen,
hdr.ipv4.identification,
hdr.ipv4.flags,
hdr.ipv4.fragOffset,
hdr.ipv4.ttl,
hdr.ipv4.protocol,
hdr.ipv4.srcAddr,
hdr.ipv4.dstAddr },
hdr.ipv4.hdrChecksum,
HashAlgorithm.csum16);
}
}
// Deparser
control MyDeparser(packet_out packet, in headers hdr) {
apply {
packet.emit(hdr.ethernet); // 这里要注意先后顺序
packet.emit(hdr.ipv4);
}
}
写好控制面代码
虽然说官方为了让大家专注于数据面编程,已经给好了控制面指令,但是我们有必要查看一下他们,从而有了更深入的理解, 查看 s[1,2,3]-runtime.json, 里面定义了很多流表项。以s1-runtime.json为例, 具体的一条流表项为:
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.1.1", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "00:00:00:00:01:01",
"port": 1
}
}
回想,table name 就是我们在p4代码中自定义的转发表。匹配域也依照了我们自定义的代码。而动作也按照我们编写的动作代码传入了相应的参数。将所有的流表项汇总一下, 我绘制了下面的图片:
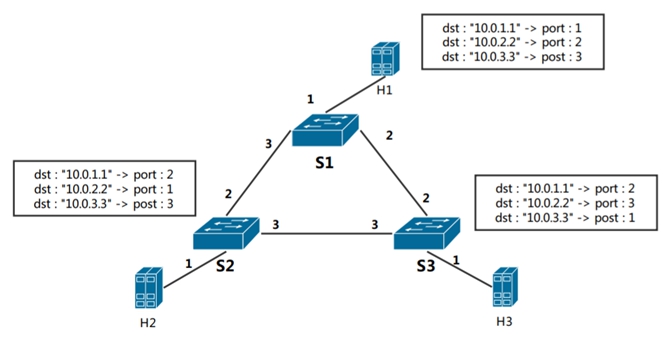
看到这一步,我们便了然了。数据面定义了转发表,而控制面下发了具体匹配转发的流表项,使得这三个主机可以互通。而在控制面下发的流表项与我们p4代码中定义的流表结构息息相关。
运行代码
make run
...
...
minint> pingall ## 进行一次pingall 测试
*** Ping: testing ping reachability
h1 -> h2 h3
h2 -> h1 h3
h3 -> h1 h2
*** Results: 0% dropped (6/6 received)
丢包率为0,说明转发功能实现了。这样我们完成了第一个实验。
一点建议
- 初次接触mininet的朋友,建议先学习mininet官方的walkthrogh。
- p4 tutorials exercises中的README写的非常详细,大家可以自己完成后面的一些练习。
总结
本文提供给大家最快捷的方式去体验,学习和使用P4。其中有方便的虚拟机直接使用,也有真机搭建的脚本。搭建好环境并且开始第一个实验后,大家可以自己专注于P4的学习啦。
第一次写文章,而且限于本人能力有限。难免有纰漏或者理解不当,还望各位谅解,如果能够给予批评指点,不胜感激!联系邮箱: zenhox@163.com,郑。

- 本站原创文章仅代表作者观点,不代表SDNLAB立场。所有原创内容版权均属SDNLAB,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用,转载须注明来自 SDNLAB并附上本文链接。 本站中所有编译类文章仅用于学习和交流目的,编译工作遵照 CC 协议,如果有侵犯到您权益的地方,请及时联系我们。
- 本文链接**:**https://www.sdnlab.com/22512.html