导言
这几年 Programmable Hardwares(可编程硬件)越来越重要了。大家比较熟悉的可能有 FPGA 在 Machine Learning 领域针对一些特别的算法进行计算加速,包括谷歌的 TPU、苹果 M1 芯片里面的神经网络计算单元,都是在 FPGA 上面做 prototype 测试之后才做成 ASIC 产品发布出来的。
计算机网络方面,上个时代的 OpenFlow[2]讲究的是在 Control Plane (控制层)可以实时(runtime)改写 switch 和 router 上的路由表。OpenFlow 的工作方式可以简单的用下面这个图来说明。
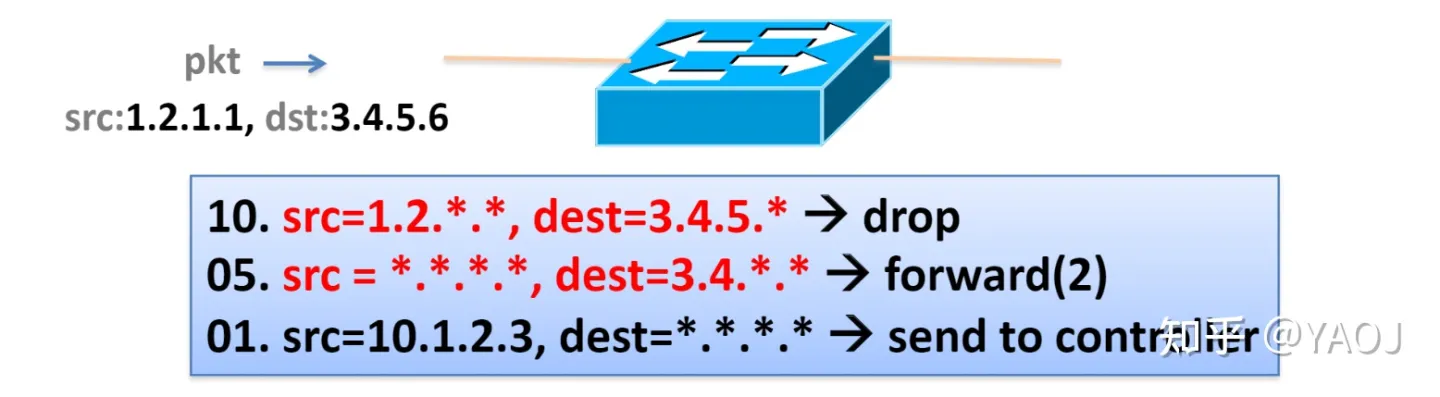
Source: github.com/nsg-ethz/p4-learning
当我们收到一个从 1.2.1.1 到 3.4.5.6 的网络包的时候,我们会在 switch 上面对照已经配置好的 rules,每个 rule 是一个 match action function。比如对于这个网络包,前两个 rule 都是符合的,第一个 rule 对应的 action 是丢掉这个包,第二个 rule 对应的 action 是从 2 号 port 转发出去。但每个 rule 的前面还有一个优先级,在有多个 rules 同时匹配的情况下,会选择最高优先级的 rule,所以这个包最终会被无情的丢掉。
十年过去了,OpenFlow 也尝试过广泛的部署,但是也面临了很多很多的问题,比如:
- 各个大厂生产的 switch 规格不一样,能够存储的 rules 的数量不一样…
- Control Plane 比 Data Plane 慢了太多,有太多时延…
- 可以实时编程的结果引入了新的复杂度,进而产生了更多可能的 bug…
- …
所以大佬们开始琢磨,能不能从更底层入手,搞一个 Protocol Independent Switch Architecture (PISA) 出来,就把计算机网络里 packet 的转发最基础的过程高度抽象化,变成下面这个图的样子,从左到右,分别是:
- Parser:先看看包里面都有啥,每一个 bit 都是什么;
- Ingress:一堆 Match-Action 的流水线,看看哪些 bits 组成的 fields 有没有我们想要的,比如目标 IP 是不是 8.8.8.8,是的话就改写一下 header 让包能被转发到它该去的地方;
- Switching Logic:还要有个地方实现我们想要的逻辑,或者为了高性能,放一个 buffer,存放刚被上一个环节处理完,准备给下一个环节处理的包[3];
- Egress:又来一堆 Match-Action 的流水线,比如改写源 MAC 地址,同时提供更多对网络包的操作空间;
- Deparser:最后把我们改写好的 headers 重新写回网络包,然后送它出去。
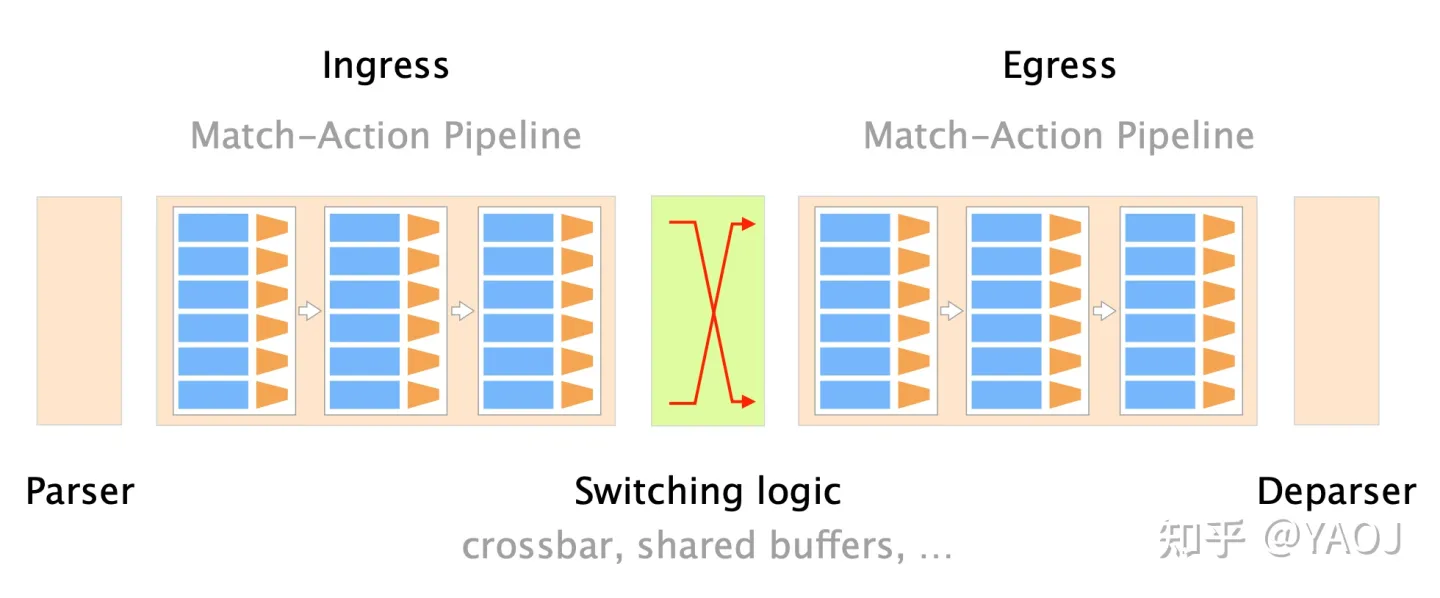
PISA, Source: github.com/nsg-ethz/p4-learning
为了能够实现这样一个架构,P4[4],就这么诞生了。P4 + PISA 其实就是一个更具普适性的 OpenFlow。
初识 P4
P4 作为一个编程语言,还算比较年轻,但也已经有 6 年多的历史了。类似于 Python 2 和 3 的版本区别,P4 也有两个版本,老的是 P4 14,新的是 P4 16。现在大厂都支持 P4 16,所以我们就好好学习新版的就好了。
P4 16 实现的模型基本等同于 PISA,叫做 v1model,长成下面这个样子。
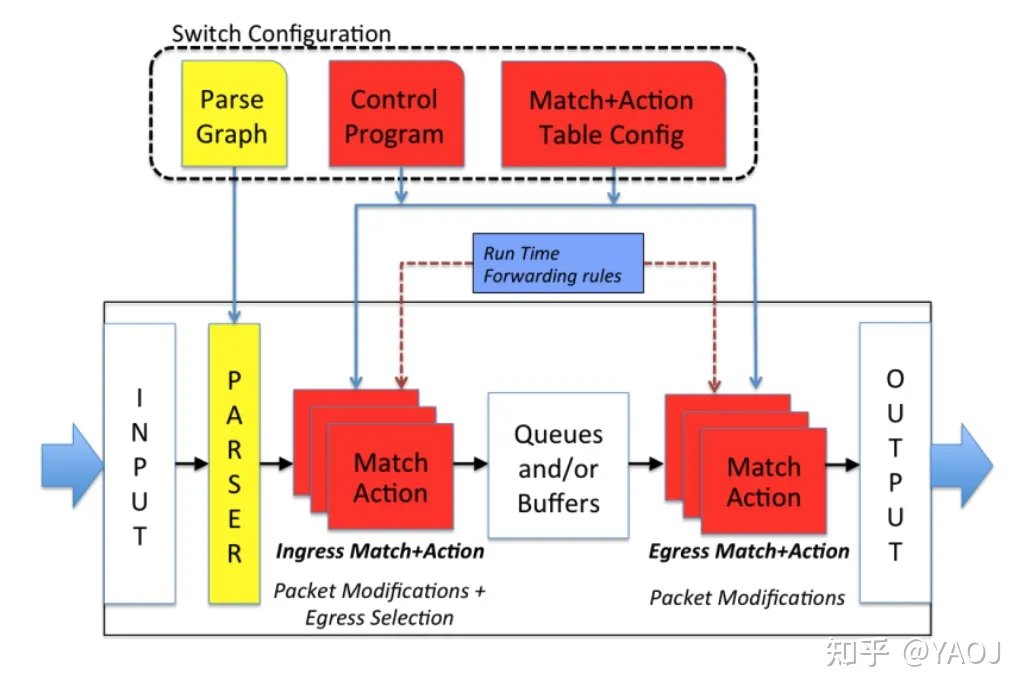
Source: https://p4.org/p4-spec/p4-14/v1.0.4/tex/p4.pdf
毕竟作为一个假装是硬件语言的语言,用 P4 编出来的逻辑,也可以实现在 FPGA 上,比如 Xilinx 的 NetFPGA Sume(关于如何购买这块板子,可以看我之前写过的回答:斯坦福使用netfpga 开发板在哪儿可以购买?)。大概的逻辑就是下图所示。由 P4 的代码,经由 Xilinx 的编译器编译成他们的架构可以理解的 binary,就可以在具有超高 throughput 的板子上跑了。当然这一切说来简单,真正去用了 Xilinx 的编译器,然后仿真验证,再上板子上跑,其实是很漫长的过程… 而且一路都会被玄学的迷雾所笼罩,所以如果有同学在做这方面的工作,加油你是最棒的!

Source: http://isfpga.org/fpga2018/slides/FPGA-2018-P4-tutorial.pdf
接下来就说一下 P4 的语法。P4 是一种静态语言,有点类似 C。一个代码文件基本上都长成下面这个样子。
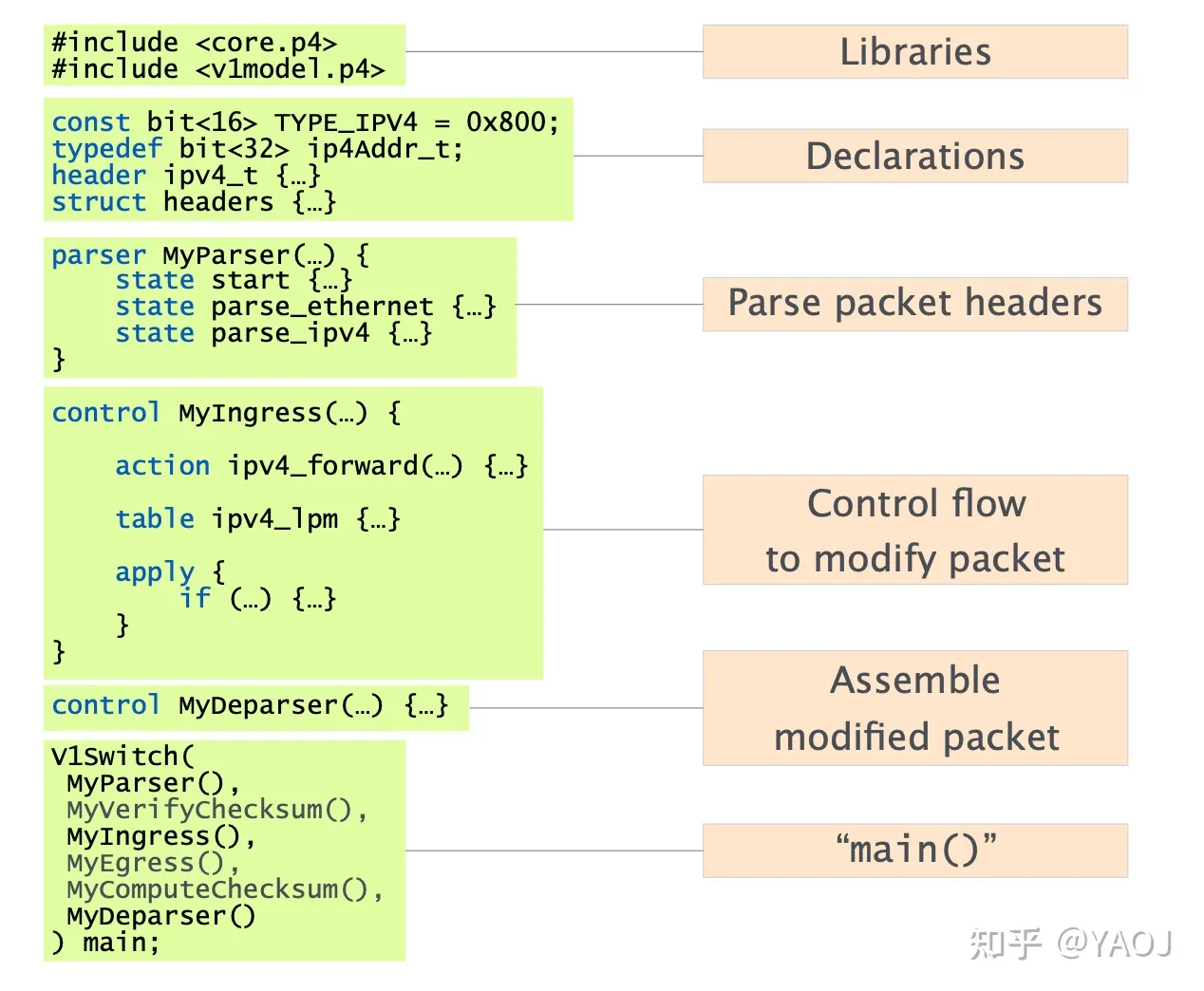
Source: github.com/nsg-ethz/p4-learning
-
Libraries:一开始要 include 一些库文件,省的造轮子;
-
Declarations:定义一下基本的数据结构,也支持 typedef;
-
Parse packet headers:这个 Parser 的地方会放一些解析 headers 的代码;
-
Control flow:这个地方基本是最重要的逻辑部分了,这里会通过我们定义的 Match-Action functions 按照修改网络包里的内容(这里只写了 Ingress 这一步,其实还会有 Egress,等到下面 main 的时候会提到);
-
Assemble:然后就是在 Deparser 的地方会把我们前面改好的部分重新组装成为一个新的 packet,转发出去;
-
main():这就是我们的 main 函数了,这里其实就是把我们刚刚写的所有的部分,按照正确的顺序排列好,一个一个的调用,所有的步骤都已经罗列出来了:
-
- 大体的结构可以分成三段式:Parser -> Match-Action Pipeline -> Deparser
- 是不是和 PISA 的结构很像?
- 大体的结构可以分成三段式:Parser -> Match-Action Pipeline -> Deparser

P4 的工作流
小结
这一篇简单介绍了一下 P4 的背景,和基本的架构,它所做的,就是把计算机网络里最基本的 packet forwarding 进行了高度的抽象,变成 Parser, Match-Action Pipeline (Ingress & Egress), Deparser 等一系列过程,更方便大家在不那么“灵活”的硬件上编写自己设计的“灵活”的 protocol。
这一篇就先说这么多,如果有同学看到的话,希望这篇文章能让你对 P4 有了一个大概的认识。
如果大家有兴趣,欢迎去看P4 学习笔记(二)- 语法基础和 Parser。我会继续讲 P4 的基本数据结构和语法,然后学习一下上面工作流那个图里面的第一个 Parser 的部分。
参考
- ^ETHz Networking Systems Group: P4-Learning https://github.com/nsg-ethz/p4-learning
- ^1 https://dl.acm.org/citation.cfm?id=1355746
- ^Maglev: A Fast and Reliable Software Network Load Balancer https://www.usenix.org/conference/nsdi16/technical-sessions/presentation/eisenbud
- ^P4: Programming Protocol-Independent Packet Processors https://dl.acm.org/doi/abs/10.1145/2656877.2656890