-
Oerview
-
这一篇文章,我们会从学习以下几个部分。
-
- P4 的基本数据类型
- P4 的基本语法
- Parser
- 小结
- P4 的基本数据类型
-
P4 的基本数据类型
-
和很多静态的语言类似,P4 最基本的数据类型放在了下面,P4 不支持的数据类型有 float(浮点)和 string(字符串)。
-
bool // Boolean value bit<W> // Bit-string of width W int<W> // Signed integer of width W varbit<W> // Bit-string of dynamic length <= W match_kind // Describes ways to match table keys error // Used to signal errors void // No values, used in few restricted circumstances -
类似于 C 语言的 packed struct,P4 里也可以定义一个复杂的数据结构,称为 header,也就是对应我们 packet 的 header,比如一个最简单的 Ethernet header,可以定义成下面这样:
-
header Ethernet_h { bit<48> dstAddr; // Destination address bit<48> srcAddr; // Source address bit<16> etherType; // EtherType field } Ethernet_h ethernetHeader; // Declaration -
这个 P4 的 header 和 c 的 struct 有一个主要的区别,就是 header 还有一个隐藏的 field 叫做 validity。比如说我们收到了一个 packet,要把它的 Ethernet header 解析出来,就可以这么写:
-
packet.extract(ethernetHeader); -
如果解析成功的话,validity 就会被自动设置为 true,等于自动帮我们确定 header 的格式是不是正确的。这一点,在这篇文章最后计算 checksum 的例子里会进一步解释。
-
当然,在有了 header 的基础上,我们还可以定义 header stack,比如对于 MPLS 来说我们可能有很多 label,就可以这样定义:
-
header Mpls_h { bit<20> label; bit<3> tc; bit bos; bit<8> ttl; } Mpls_h[10] mols; // 一列 10 个 MPLS headers -
同时也有 union 的格式,记作 header_union,比如 IP header 要么是 v4,要么是 v6,我们就可以这么定义:
-
// 只用其中的一种 header_union IP_h { IPv4_h v4; IPv6_h v6; } -
如果想要单纯的定义一个类似于 python 里的字典(dictionary)的数据结构的话,P4 提供了一个数据结构叫 struct。这里的命名会比较特别,为了防止混淆,还是要做一个区分:
-
P4 | 对比 header | c 语言里的 packed struct, 比如:struct __attribute__((__packed__)) mystruct {...}; struct | python 里的 dictionary -
P4 里面最常用的 struct 之一就是下面这个,用来改写每一个收到的 packet 要从哪一个 port 发出去:
-
// reference: https://github.com/p4lang/behavioral-model/blob/master/docs/simple_switch.md struct standard_metadata_t { bit<9> ingress_port; // 收到 packet 的 port number,只读 bit<9> egress_spec; // 准备发出 packet 的 port number,也可以设置成 drop bit<9> egress_port; // 准备发出 packet 的 port number, 只读 ... } -
还有一些其他的数据类型,比如 tuple:
-
tuple<bit<32>, bool> x; x = {10, false}; -
还有 enum(优先级从前到后由高到低)、typedef、extern、parser、control、package,之后有机会再在具体例子里面解释说明他们的用法(挖个坑…)。
-
P4 的基本语法
-
P4 支持的操作类型如下:
-
-
算术运算(arithmetic operations):+, -, *
-
逻辑运算(logical operations):~, &, |, ^, », «
-
特殊运算(non-standard operations):
-
- 数列的切割(bit slicing):[m;l]
- 比特的叠加(bit concatenation):++
- 数列的切割(bit slicing):[m;l]
-
-
-
P4 不支持除法(division)和取余(modulo)运算,但是可以被近似(之后如果遇到了例子会说明,再挖个坑…)。
-
P4 对于变量(variables)和常量(constants)的声明和实例化和 c 语言基本一致,比如下面这个例子:
-
/* variable */ bit<8> x = 123; typedef bit<8> MyType; MyType x; x = 123; /* constant */ const bit<8> x = 123; typedef bit<8> MyType; const MyType x = 123; -
这些变量只能用于暂时存储数据,不能用来记录状态,他们不是 stateful 的结构。比如一个 普通的 TCP 的 network flow,我们通常用它的 5-tuple(srcAddr, dstAddr, srcPort, distort, protocolNum)的 hash 计算它的 ID,然后就可以把这个 flow 的信息存起来,比如已经收到 SYN packet 了,或者已经三次握手结束了,用来跟踪这个 flow 的”状态“。
-
如果想要进行类似的 stateful 的操作,需要用到 tables 或者 extern objects,这两个数据结构我们之后再说(继续挖坑…)。
-
P4 的逻辑方面就很简单了,只有 if-else 和 switch 语句,且不能在解析(parser)的过程使用,只能在逻辑控制的部分使用,稍后我们会说到。基本的样子如下:
-
if (x == 123) {...} else {...} switch (t.apply().action_run) { action1: {...} action2: {...} } -
最后要说的就是 P4 支持两个等级的终止命令,一个是 return,一个是 exit,和 python 一样,return 就终止当前运行的部分,exit 则终止所有运行的模块。
-
Parser
-
看了这么多语法,是时候结合 P4 具体的实现方式举个例子了。借着这个例子,我们来顺便说一下 P4 的 workflow 中第一部分—— Parser。
-

-
P4 的工作流
-
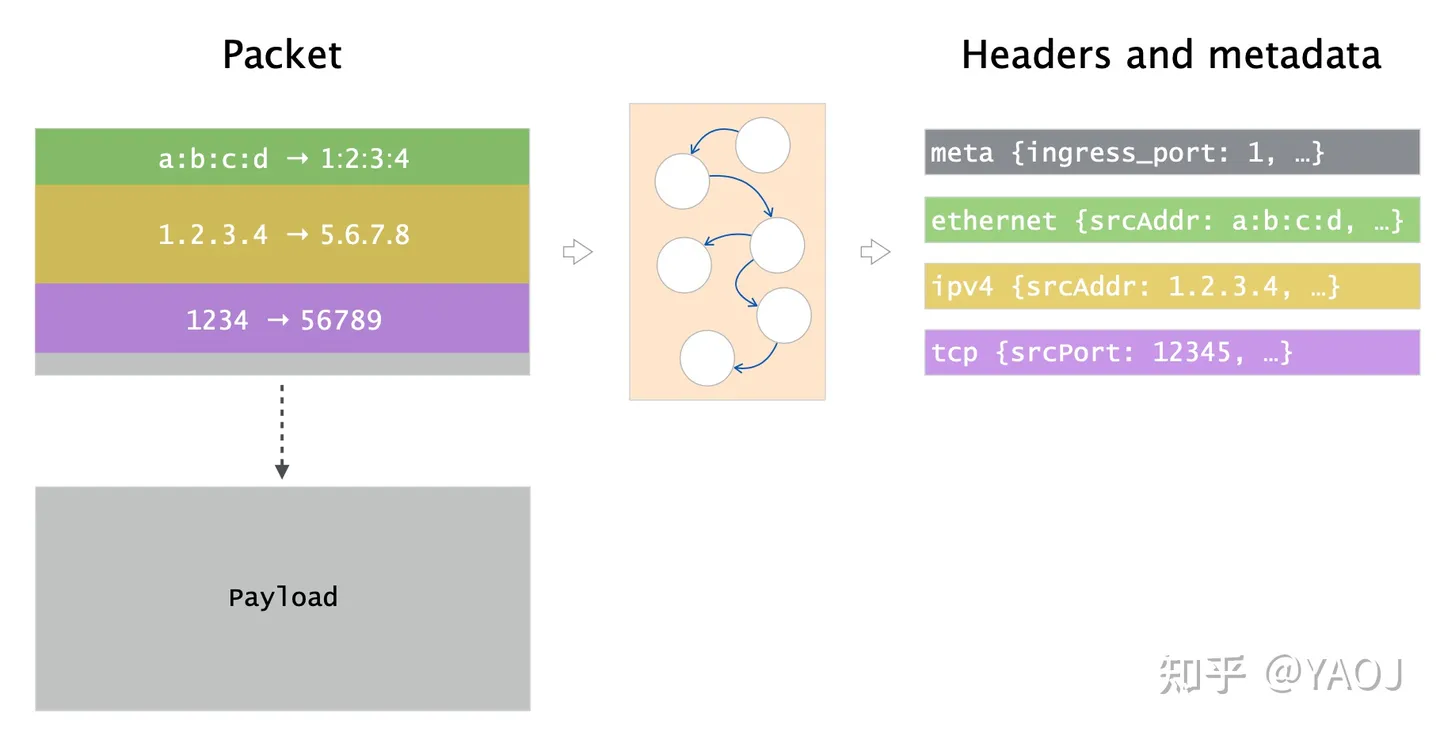
Parser 的角色很重要,但也很简单,就是把一个网络包 headers 里面的信息都解析出来。就像下面这幅图中,一个 packet 可能有很多层 header 包含了不同的信息,Layer-2 的 MAC 地址信息、Layer-3 的 IP 地址信息、Layer-4 的 Port 信息等等。Parser 的任务,就是把这些信息都解析出来,存储为 P4 能理解的数据结构,比如我们之前讲的 struct 和 header。 而 P4 的实现方式,就是靠状态机。
-
-
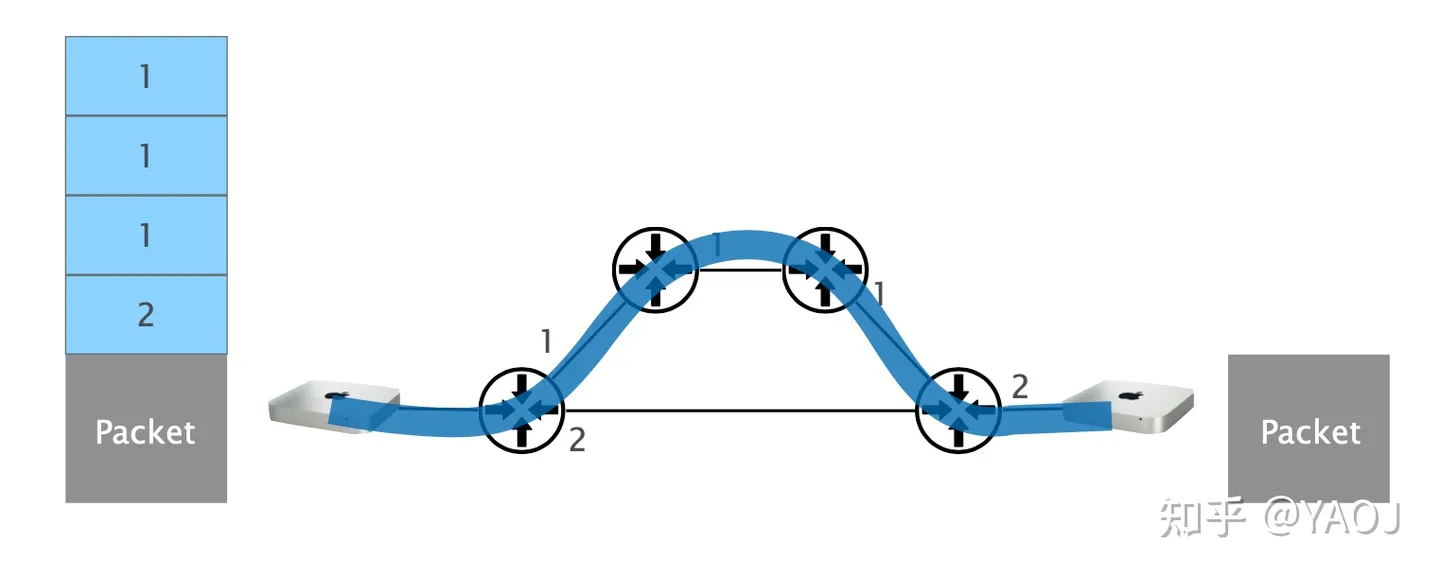
我们看下面一段关于 Source Routing (SR,注意这个 SR 不是 Segment Routing[1] 的 SR,虽然大同小异) header 解析部分的代码。SR 一个简单的例子就是,我们想要把一个 packet 从下面这一幅图中的蓝色的路径从左边发到右边,为了做到这一点,我们在 packet 的头部加四个 header,到了第一个 switch 的时候我们把最上面那个 header 拿下来,并且走里面写好的 port 1,从 port 1 到达第二个 switch 的时候,我们再把现在最上面那个 header (也就是图里第二个 header)拿下来,然后从里面写的 port 1 出发,到第三个 switch,以此类推,到了最后一个 switch 的时候,packet 只剩下最后一个 header 了,我们再给拿下来,然后从 header 里写好的 port 2 转发到我们的目的地,这个时候,packet 就不剩 header 了。
-
-
实现解析这样的 header 的代码,就像下面这样写:
-
// source routing 的 header 结构 header srcRoute_t { bit<1> bos; bit<15> port; } // 定义所有 header 的结构 struct headers { ethernet_t ethernet; srcRoute_t[MAX_HOPS] srcRoutes; ipv4_t ipv4; } parser MyParser(...) { state start { transition parse_ethernet; // 0: 直接跳转到 parse_ethernet } state parse_ethernet { packet.extract(hdr.ethernet); transition select(hdr.ethernet.etherType) { // 1: 下一个跳转的分支取决于 EtherType 的值 TYPE_SRCROUTING: parse_srcRouting; 0x800: parse_ipv4; default: accept; } } state parse_srcRouting { packet.extract(hdr.srcRoutes.next); transition select(hdr.srcRoutes.last.bos) { 1: parse_ipv4; // 如果是最后一个 source routing 的 header,去解析 ipv4 default: parse_srcRouting; // 否则继续解析 source routing 的下一个 header } } state parse_ipv4 { packet.extract(hdr.ipv4); transition select(hdr.ipv4.protocol) { 6: parse_tcp; 17: parse_udp; default: accept; } state parse_tcp { packet.extract(hdr.tcp); transition: accept; } state parse_udp { packet.extract(hdr.udp); transition accept; } } -
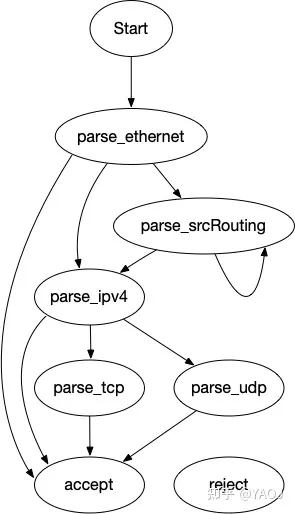
这部分代码相对来说应该比较容易理解,实现的其实就是一个下面这个状态机:
-
-
从 start 这个 state 开始,第一步先去解析 Ethernet 的 header(即 parse_ethernet)。如果 EtherType 对应的值是 0x800(也就是 IPv4 对应的值),那么我们就知道这个 packet 是个 IP packet,下一步跳转到解析 IPv4 的状态(即 parse_ipv4),否则就直接接受这个 packet。对于 IP packet,相似的,如果 header 里面的 protocol 对应是 TCP,就继续跳转到解析 TCP 的状态(即 parse*_*tcp),当然 UDP 也一样。如果 EtherType 对应的是 source routing 的值(我们定义一个 TYPE_SRCROUTING)的话,那就先跳转到解析 source routing 的状态(即 parse_srcRouting),这个状态里,可能会停留在原地不动,直到我们解析了最后一个 source routing 的 header,然后再跳转到 IPv4 的状态。一个简单的 Parser 实例如下:
-
header IPv4_no_options_h { ... bit<32> srcAddr; // 固定长度 bit<32> dstAddr; } header IPv4_options_h { varbit<320> options; // 可变长度 } ... parser MyParser(...) { ... state parse_ipv4 { packet.extract(headers.ipv4); transition select (headers.ipv4.ihl) { 5: dispatch_on_protocol; // 如果 ihl==5,那么没有 options,直接按照对应的 protocol 解析 default: parse_ipv4_options; // 否则解析 options } } state parse_ipv4_options { packet.extract(headers.ipv4options, (headers.ipv4.ihl - 5) << 2); // ihl 决定了 options 的长度 transition dispatch_on_protocol; } } -
另外值得一提的是,这个 Parser 的部分是 P4 里唯一一个可能的循环操作,别的地方 P4 都没有支持循环的操作。一个需要循环的例子就是 TCP options 的解析,比如下面这一段代码实现:
-
parser Tcp_option_parser(packet_in b, in bit<4> tcp_hdr_data_offset, out Tcp_option_stack vec, out Tcp_option_padding_h padding) { bit<7> tcp_hdr_bytes_left; state start { // RFC 793 - the Data Offset field is the length of the TCP // header in units of 32-bit words. It must be at least 5 for // the minimum length TCP header, and since it is 4 bits in // size, can be at most 15, for a maximum TCP header length of // 15*4 = 60 bytes. verify(tcp_hdr_data_offset >= 5, error.TcpDataOffsetTooSmall); tcp_hdr_bytes_left = 4 * (bit<7>) (tcp_hdr_data_offset - 5); // always true here: 0 <= tcp_hdr_bytes_left <= 40 transition next_option; } state next_option { transition select(tcp_hdr_bytes_left) { 0 : accept; // no TCP header bytes left default : next_option_part2; } } state next_option_part2 { // precondition: tcp_hdr_bytes_left >= 1 transition select(b.lookahead<bit<8>>()) { 0: parse_tcp_option_end; 1: parse_tcp_option_nop; 2: parse_tcp_option_ss; 3: parse_tcp_option_s; 5: parse_tcp_option_sack; } } state parse_tcp_option_end { b.extract(vec.next.end); // TBD: This code is an example demonstrating why it would be // useful to have sizeof(vec.next.end) instead of having to // put in a hard-coded length for each TCP option. tcp_hdr_bytes_left = tcp_hdr_bytes_left - 1; transition consume_remaining_tcp_hdr_and_accept; } state consume_remaining_tcp_hdr_and_accept { // A more picky sub-parser implementation would verify that // all of the remaining bytes are 0, as specified in RFC 793, // setting an error and rejecting if not. This one skips past // the rest of the TCP header without checking this. // tcp_hdr_bytes_left might be as large as 40, so multiplying // it by 8 it may be up to 320, which requires 9 bits to avoid // losing any information. b.extract(padding, (bit<32>) (8 * (bit<9>) tcp_hdr_bytes_left)); transition accept; } state parse_tcp_option_nop { b.extract(vec.next.nop); tcp_hdr_bytes_left = tcp_hdr_bytes_left - 1; transition next_option; } state parse_tcp_option_ss { verify(tcp_hdr_bytes_left >= 5, error.TcpOptionTooLongForHeader); tcp_hdr_bytes_left = tcp_hdr_bytes_left - 5; b.extract(vec.next.ss); transition next_option; } state parse_tcp_option_s { verify(tcp_hdr_bytes_left >= 4, error.TcpOptionTooLongForHeader); tcp_hdr_bytes_left = tcp_hdr_bytes_left - 4; b.extract(vec.next.s); transition next_option; } state parse_tcp_option_sack { bit<8> n_sack_bytes = b.lookahead<Tcp_option_sack_top>().length; // I do not have global knowledge of all TCP SACK // implementations, but from reading the RFC, it appears that // the only SACK option lengths that are legal are 2+8*n for // n=1, 2, 3, or 4, so set an error if anything else is seen. verify(n_sack_bytes == 10 || n_sack_bytes == 18 || n_sack_bytes == 26 || n_sack_bytes == 34, error.TcpBadSackOptionLength); verify(tcp_hdr_bytes_left >= (bit<7>) n_sack_bytes, error.TcpOptionTooLongForHeader); tcp_hdr_bytes_left = tcp_hdr_bytes_left - (bit<7>) n_sack_bytes; b.extract(vec.next.sack, (bit<32>) (8 * n_sack_bytes - 16)); transition next_option; } } -
如果上面这两个例子看懂了的话,加一个我们自己设计的 protocol 进去就很容易了,好像可以作为一个思考题(手动狗头)?
-
Parser 的部分还有很多更高端的操作,比如 verify、lookahead、sub-parser,有机会看到的话我们再一起学习[2]。
-
小结
-
这篇文章简单的梳理了一遍 P4 基本的语法知识,包括基本数据类型和运算操作。
-
下一篇会结合更多例子来介绍 P4 workflow 里面剩下的部分,也就是 Match-Action Pipeline 和 Deparser 的过程。
-
参考
-
- ^Segment Routing https://www.segment-routing.net/ietf/
- ^P4-16 Spec https://p4.org/p4-spec/docs/P4-16-v1.0.0-spec.html