COPY RIGHT 以下相关内容的版权为 Sibsankar Haldar 所有,仅供学习研究只用,未获得原始作者的授权时不可有任何侵权行为;
第一章 计算机系统概论
第二章 SQLite概述
学术目标
- SQLite数据库系统及其功能
- SQLite支持哪些显著特性
- SQLite如何将表存储在数据库文件中
- 如何编写、编译和执行SQLite应用程序
- 一些最常用的SQLite API
- 模块化的SQLite体系结构
- SQLite的限制
章节概要
SQLite是一个小型的、零配置的、定制的、可嵌入的、线程安全的、易于维护的、面向事务的、基于SOL的关系数据库管理系统。它将整个数据库存储在包含所有表和索引的单个文件中。它将所有表组织成单独的B+树,并将索引组织成B树。它支持核心事务属性,即原子性、一致性、隔离性和持久性。它使用基于锁的并发控制方案和基于日志的恢复方案。
SQLite 支持 ANSI SOL-92 功能的较大子集和许多 SQLite 特定命令。此外,它提供了一个良好的框架,您可以在其中定义定制的 SOL函数、聚合器和排序序列。它还支持基于 Unicode 文本的 UTF-8和 UTF-16 标准的编码。
本章几乎涵盖了SQLite的所有功能。它提供了一个高层次的概述,介绍SOLite如何与SOL应用程序一起工作。通过展示一些简单的应用程序,它认您熟悉一些SOLiteAPI,这些API用于SOLite和数据库应用程序之间的正常交互。它还展示了SQLite源代码的结构和组织。总的来说,本章是SQLite的简短介绍。
2.1 SOLite简介
在过去的几十年里,许多数据库管理系统(DBMS)已经被开发出来。Informix、Ingres、MySOL、甲骨文、PostgreSOL、SOLServer、Sybase是这里要提到的个商业上成功的企业数据库应用程序。成功的嵌入式数据库系统包括SybaseiAnywhere、系统间缓存、微软Jet。SQLite[22]SQLite是关系数据库管理系统(RDBMS)家族中的一个新成员,也是一个非常成功的嵌入式数据库系统。1SQLite 于2000年5月29日首次公开发布,作为Alpha代码的初始公开发布,其功能集非常有限。SQLite1.0于2000年8月17日发布。自那时以来,它已经走过了漫长的旅程。SOLite2.0.0于2001年9月20日发布,SOLite3.0.0于2004年6月18日发布。截至 2011年9月19日,最新的版本是SQLite3.7.8。本书基于这个特定的版本。SOLite 开发团队继续发布新版本。您可以通过访问 SOLite 主页http://www.sqlite.org获取最新版本。您可以在 http://www.sqlite.org/changes.html网页上找到功能开发的时序事件。(当这本书在你手中时,SOLite肯定会有不同的更新版本。但是,核心功能和处理数据的方式预计不会变化太大。在这里学到的知识将帮助你理解新功能。通过阅读这本书,你一定会对设计和开发嵌入式数据库系统所需的内容有感觉。我鼓励你自己开发一个。
2.1.1显著的SQLite特性
SQLite完全使用ANSIC程序设计语言开发。它是一个易于维护、相对快速基于SQL的RDBMS。它具有以下优良、差异化和值得称道的特点。
- 零配置:在使用SQLite数据库管理软件之前,您不需要执行任何单独的安装或设置步骤来初始化它。没有特定的步骤来启动SOLite。没有配置文件来控制不同的行为。数据库不需要任何管理。您可以从其主页 http://www.sqlite.org/download.html,使用您喜欢的C编译器将其编译为可执行库,并开始将库作为数据库应用程序的一部分使用。对于有限数量的平台,您可以从那里获取库。
- 可嵌入:您不需要单独的服务器进程专门用于 SOLite。SOLite库可以嵌入到您自己的应用程序中。应用程序不需要包含任何进程间通信方案来与SOLite 交互。
- 应用程序接口:SOLite为C应用程序提供了一个SOL环境来操作数据库。它为动态SOL提供了一组调用级应用程序编程接口(API)函数;您可以动态组装SQL陈述并将其传递到接口进行执行。此外,您还可以使用许多回调功能。应用程序没有特殊的预处理和编译要求;普通的C编译器可以完成这项工作。
- 事务支持:SQLite支持核心事务属性,即原子性、一致性、隔离性和持久性(ACID)。在系统崩溃或电源故障时,数据库用户或管理员无需采取任何操作即可恢复数据库。当SQLite读取数据库时,它会自动以用户透明的方式对数据库执行必要的恢复操作。
- 线程安全:SOLite是一个线程安全的库,应用程序中的多个线程可以同时访问相同或不同的数据库。SOLite 处理数据库级别的线程并发。
- 轻量级:在启用所有 SQLite功能时,SQLite库的占用空间约为 324KB(在Linux上使用 gcc-0s时为 331835 字节)。如果从源代码构建库时禁用所有言级功能,占用空间可以减少到约 190KB。
- 可定制性:SOLite提供了一个良好的框架,您可以在其中定义和使用定制的SQL函数、聚合函数和整理序列。
- Unicode:SOLite支持基干UTF-8和UTF-16标准的Unicode文本编码。 UTF16 同时支持小单位和大单位形式。
- 防止内存泄漏:如果应用程序严格遵循推荐的与SQLite库交互的协议,则该库声称从不泄漏内存。
- 内存需求:虽然SOLite可以使用无限量的堆栈和堆空间,但可以设置最小的堆栈空间为4KB和大约100KB的堆。这个特性对于受内存限制的小型设备(如手机)非常有效。主内存量很小。但是,可用内存越多,SOLite性能越好。
- 多平台:SOLite运行在Linux、Windows、MacOSX、0S/2、0penBSD和其他一些操作系统上。它也运行在嵌入式操作系统上,如Android、Symbian、Palm、VxWroks. 单个数据库文件:每个数据库完全存储在单个本地文件中;用户数据和元数据存储在同一个文件中。单文件方法简化了将数据库从一个地方移动/复制到另一个地方的过程。(SQLite在操作数据库时会使用许多临时文件。)
- 跨平台:SQLite 允许您在平台之间移动数据库文件。例如,您可以在Linuxx86机器上创建一个数据库,并在ARM、Windows或MAC平台上使用相同的数据库(通过复制)而无需任何更改。数据库在所有支持的平台上都具有相同的行为。您可以在 32位和 64 位机器之间或在大小端系统之间使用相同的数据库而没有任何问题。
- 向后兼容性:SOLite3具有向后兼容性。这意味着任何较新的库版本都可以与较早库版本创建的数据库一起工作。SQLite 开发团队努力保持库的向后兼容性。但是,版本3的库无法与版本2的数据库一起工作。
2.1.2使用简单
与大多数现代 SOL数据库管理系统不同,SOLite的首要设计目标是简单。SQLite 开发团队信奉 KISS 哲学:保持简单和卓越。他们努力保持 SOLite的简单性,即使这会导致某些功能的低效实现。本质上,SOLite是
-
易于管理。
-
操作简单。
-
简单地嵌入到C应用程序中。
-
易于维护。
-
易于定制。
-
实现了 ACID 要求。
简单性: 简单的软件更容易实现、测试、维护、增强、集成、文档等。SQLite满足这些标准 为了实现简单性,SQLite开发团队选择牺牲许多数据库用户认为有用的DBMS特性,如高事务并发、细粒度访问控制、许多内置函数、存储过程-些SQL语言特性(如对象关系)、太字节或拍字节的可扩展性等。 可靠性:SQLite非常可靠。这种可靠性似乎是其简单性的结果。
2.1.3 SQL特性和SQLite命令
SOLite支持ASIC SOL-92数据定义和数据操作功能的大子集,以及一些SQLite特定的命令。(这些命令类似于SOL陈述,但它们本身不会操纵用户数据。)您可以使用标准数据定义SOL结构创建表、索引、触发器和视图。您可以使用SYS、SYS、GROUP和SEN SOL结构来操作存储的信息。以下是自SOLite3.7.8版本起支持的SOL功能列表。(未来的每个新版本都可能具有其他功能。可从SOLite网页http:/www.sqlite.org/lang.html获取最新的受支持功能集。 1.数据定义语言DDL:
-
创建表、索引、视图和触发器;
-
删除表、索引、视图和触发器;
-
部分支持ALTERTABLE(重命名表和添加列):
-
唯一,非空,并检查约束条件;
-
掭轆顶足縲衍键约束;
-
自动增量,整理列;
-
解决冲突。
2.数据操作语言DML:
-
插入、删除、更新和选择;
-
子查询,包括相关子查询;
-
按组别、按顺序、抵消限额、整理;
-
内接头,左外接头,自然接头;
-
联合,联合所有,相互作用,除外:
-
命名参数和参数绑定;
-
每行触发器。
3.事务性命令:
-
开始;
-
承诺;
-
滚动;
-
保存点;
-
滚动返回;
-
释放。
4.SQLite命令:
-
reindex;
-
附着,拆卸;
-
解释;
-
pragma.
SQL标准规定了大量的关键字,这些关键字不能用作表、视图、索引、列、约束或数据库的名称。SQLite放宽了这一限制,允许您使用关键字作为标识符,方法是在它们周围使用反引号或单引号或双引号或'【和"】‘对。此外,SOLite提供了一个良好的框架,您可以在其中定义和使用自定义SOL函数聚合函数和排序序列。宏是特殊的SOLite命令,用于更改SOLite库的行为或查询库的内部(非表)元数据。SOLiteattach命令可帮助事务同时在多个数据库工作。此类事务也符合ACID要求。
在SQLite3.7.8发行版中,尚未支持以下ANSISOL-92特性(有关当前列表,请参阅http://www.sqlite.org/omitted.html网页)。
- 许多ALTERTABLE特性,例如重命名或删除列,添加或删除约束;
- 对于每个语句触发器;
- 右侧和完全外部接头;
- 更新视图;
- 授予和撤销。
2.1.4数据库存储
SQLite将整个数据库存储在单个的普通本地文件中,文件可以位于本地文件系统目录中的任何位置。我们经常说文件与数据库是同义词,因为没有其他文件存储有关数据库本身的信息。具有读取文件权限的用户可以从数据库中读取任何内容。具有写入文件和容器目录权限的用户可以更改数据库中的任何内容。只要本地操作系统/文件系统允许文件增长,数据库就可以增长。SOLite在Linux系统上支持非常大的文件(>2GBytes)选项,如果这些系统有此选项。它将所有表和索引分别组织为单独的B+树和B树。它使用单独的日志文件来保存事务恢复信息,这些信息在发生事务中断或系统故障时使用。
2.1.5有限的并发性
SQLite允许多个应用程序同时访问同一个数据库。然而,它只支持有限形式的并发事务。它允许在数据库上进行任意数量的并发读取事务,但只允许个独占的写入事务。它没有支持更精细数据粒度(如表、页、行、列或单元格)并发的能力。
2.1.6 usage
QLite是一个非常成功的嵌入式RDBMS。它已被广泛用于低到中等层次的数据库应用程序,如Web服务、手机、掌上电脑、机顶盒、独立设备。你甚至可以在初学者数据库课程中使用它来教授关系数据库和SOL语言。你也可以在高级数据库管理课程中使用它,或者在数据库项目中作为参考技术使用,它是免费提供的,而且由于它处于公共领域,所以没有许可证的复杂性。(虽然有一些可选的专有部件,如用于智能卡的SQLite,以及需要从SQLite的拥有者Hwaci订购的加密解决方案。课程学生可能不担心这些专有组件擰攥饕*鯀峱)砑 Web服务器:基于SQLite的Web服务器工作良好,每天平均分配的点击量可达100,000次;SQLite开发团队已经证明SQLite甚至可以承受每天1,000,000次的点击量。
SOLite是开源的,并且可以在公共领域使用(有关开源的更多信息,请访问http://opensource.org)。您可以从网页http://www.sqlite.org/download.html下载SOLite源代码,使用您喜欢的C编译器将其编译为可执行库,并使用数据库应用程序开始使用该库。SOLite在Linux、Windows、MACOSX、0S/2、Solaris、OpenBSD和其他一些操作系统上运行。在这本书中,我仅限于SQLite3.7.8的Linux版本,这是截至9月19.2011年的最新版本。
2.2 示例SQLite应用程序
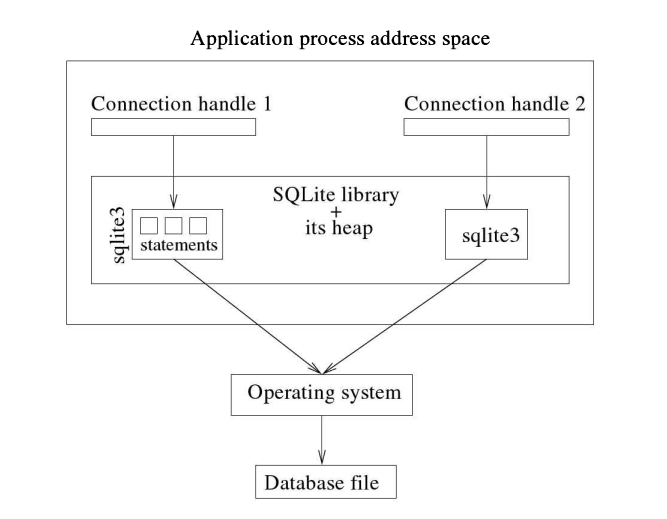
在本节中,我将向您介绍一些简单的数据库应用程序,这些应用程序展示了SQLite 的各种核心功能。您将熟悉一些最重要和最常用的 SOLite API函数和 API常量。除了第 2.2.2 节讨论一些 API外,应用程序将在以下小节中介绍。您可能记得,SQLite是一个嵌入式库,它被嵌入到应用程序进程地址空间中。图 2.1展示了 SOLite 应用程序的一般架构。如图所示,SOLite库被嵌入到应用程序进程中,进程堆空间的一部分用于存储 SQLite 的运行时数据。当然,当SQLite的API函数被调用时,它会使用堆。

2.2.1一个简单的应用程序
让我们通过研究一个非常简单的应用程序来开始对SQLite领域的探索。图22展示了一个典型的SOLite应用程序。这是一个典型的C程序,它调用SOLiteAPI函数来处理单个SOLite数据库。它演示了使用SOLite通过执行SOL查询来访问数据库的简单方法。
#include <stdio.h>
#include "sqlite3.h"
int main(void)
{
sqlite3*db=0;/*connection handle */
sqlite3_stmt*stmt=0;/*statement handle */
int retcode;
retcode = sqlite3_open("MyDB”, &db); /* Open a database named MyDB */
if (retcode !- SQLITE_OK){
sqlite3_close(db);
fprintf(stderr,"Could not open the MyDB database\n” );
return retcode;
}
retcode=sqlite3_prepare(db,"select SID from Students order by SID",-1,&stmt, 0)
if (retcode != SQLITE_OK) {
sqlite3_close(db):
fprintf(stderr,"Could not compile a select statement\n");
return retcode;
}
while(sqlite3_step(stmt)=-SQLITE_ROW) {
int i = sqlite3_column_int(stmt, 0);
printf("SID = %d\n", i);
}
sqlite3 finalize(stmt);
sqlite3_close(db);
return SQLITE_OK:
}
您可以编译上述示例应用程序并执行它。本文件中显示的示例输出是在Linux 机器上生成的,但这些示例将在 SOLite 运行的其他平台上工作。
注: 这些示例假定您已经准备了sqlite3可执行文件、libsqlite3.so(Windows上为 sqlite3.dll,Mac OSX上为 libsqlite3.dylib)共享库和 sqlite3.h接囗定义文件。您可以从 http://www.sqlite.org 以源代码或二进制形式获取这些文件。(二进制文件仅适用于 Linux、MACOSX和Windows。)如果您将所有三个文件(sqlite3、共享库和 sqlite3。
例如,假设你正在Linux系统上,并将示例程序保存为app1.c,与libsqlite3.so、sqlite3和sqlite3.h位于同一目录中
gcc app1.c -o./app1 -lsqlite3 -L.
它将在当前工作目录下生成一个名为appl的二进制文件。您可能执行该应用程序以查看输出。要在Linux系统上拉取SQLite库,您可能需要将工作目录名称包含在LD.LIBRARY PATH环境变量中。是的,您运行了app1,但它没有产生任何输出;这是因为您当前工作目录中缺少应用程序所需的“MyDB”数据库。
注意: SQLite源代码和应用程序必须使用相同的编译器进行编译。如果您已将SQLite作为软件包安装,或者您的操作系统发行版预装了SQLite,则可能需要使用不同的编译器参数。例如,在Ubuntu上,您可以使用命令sudoaptitudeinstall sqlite3 libsqlite3-dev安装SOLite,并使用命令cc appl.c-o./app11sqlite3编译示例应用程序。由于SQLite包含在MacOSX的较新版本中,因此相同的编译命令也适用干Mac OSX。
该应用程序在当前工作目录中打开MyDB数据库文件。该数据库至少需要个名为Students的表;该表必须至少有一个名为SID的整数列。在下一个示例应用程序中,您将学习如何在数据库中创建新表,以及如何插入表中的行,但就目前而言,您可以使用sqlite3实用程序通过这些命令创建和填充表: ./sqlite3 MyDB"创建学生表(SID整数) ./sqlite3 MyDB"插入学生值(200)" ./sqlite3 MyDB"插入学生值(100)1 ./sqlite3 MyDB"插入学生值(300) 如果您现在运行 app1,您将看到以下输出: SID =100 SID =200 SID =300
注意: 在Linux、Unix和Mac 0SX上,在命令提示符下键入app1名称时,可能需要将它前缀为./,如:./app1 打开数据库后,应用程序app1首先准备SQL语句:selectSIDfromStudentsorder bySID。然后,它遍历由该语句生成的结果行集,逐个获取SID值,并打印这些值。最后,它关闭准备好的语句和数据库。
SQLite 是一个调用级接口库,在运行时嵌入到应用程序进程的地址空间中。该库将所有 SQLite API实现为C函数。所有 API函数名都以sqlite3开头(API常量以 SQLITE_开头),它们的签名在 sqlite3.h中声明。其中几个函数在 app1应用程序中使用,即 sqlite3 open、sqlite3_prepare、sqlite3_step、sqlite3column int、sqlite3 finalize和sqlite3 close. 该应用程序还使用了一些助记API常量,即SOLITEOK和SOLITE.ROW,用于比较API函数返回的值。在介绍其他SOLite应用程序之前,下一节将讨论一些关键的SOLite APl.
2.2.2 SQLite APIs
SQLite接口定义了一组API(一组C函数和一组命名常量)。API函数是应用程序和SQLite库之间正常通信的唯一手段。(SOLite还使用回调C函数,这些函数驻留在应用程序空间中。)我在上一节中概述了一些API函数。这里我介绍一组基本的API函数,它们在SOLite应用程序中最为常用。这些和其他API函数的详细讨论可以在SOLite网页http://www.sqlite.org/capi3refhtml中找到。大约有185个API函数。所有API函数和常量的列表可以在http://www.sqlite.org/c3ref/funclist.html双页上找到。
- sqlite3 open:这个函数有两个参数,一个输入,另一个输出。输入是-个数据库文件名。通过执行open函数,应用程序与SQLite库建立一个新的连接或会话,以访问给定的数据库文件。在这本书中,我将其称为库连接。(应用程序可能有其他打开的库连接来访问相同或不同的数据库。SQLite对这些库连接进行区分处理,在SQLite的范围内它们是相互独立的。)在库连接内部,函数打开数据库文件。如果文件不存在,该函数会自动创建数据库文件;默认文件权限为0644。如果数据库成功打开(或创建),则该函数将SQLITE OK返回给应用程序。否则,应用程序将获得错误代码。
懒散的文件打开: 在打开或创建数据库文件时,SQLite遵循一种懒散的方法-一实际的打开或创建被推迟到文件被读取时。如果数据库文件确实存在,SQLite会自动恢复数据库到一个一致的状态,如果需要的话。懒散的文件创建给你一个机会,使用pragma命令(这些设置参数将在第3章中讨论)来(重新)定义各种数据库设置参数。
open 函数通过输出参数(在前面的示例中为 db)返回一个连接句柄(指向sqlite3 类型对象的指针),该句柄用于对库连接(对于此打开的 SQLite 会话)执行进一步操作。该句柄表示此库连接的完整状态。
图2.3显示了一个典型的场景,其中应用程序已经打开了两个到SQLite库的连接,以访问同一个数据库文件。库连接是相互独立的,它们分别由单独的sqlite3对象表示。-个单独的sqlite3库中的对象表示和管理单个库连接。如图所示,理语句,而另一个连接没有。我接下来讨论预处理语句。
 **较新的APIs:**最近,SQLite开发团队不鼓励使用这个open函数;他们推荐使用sqlite3_open_v2函数。还有其他许多_V2 API函数。为了保持应用程序呈现的简洁性,我避免在本书中使用这些较新的API函数。
**较新的APIs:**最近,SQLite开发团队不鼓励使用这个open函数;他们推荐使用sqlite3_open_v2函数。还有其他许多_V2 API函数。为了保持应用程序呈现的简洁性,我避免在本书中使用这些较新的API函数。 - sqlite3_prepare:此函数编译一个SQL语句,并生成一个等效的内部对象(类型为sqlite3 stmt)。在数据库文献中,此对象通常被称为预置语句,并在SOLite中以字节码程序实现。字节码程序是数据库引警执行的SOL语包的抽象表示。我将在175页的7.2节中讨论字节码程序设计语言。在本书中,我可以互换使用字节码、程序和准备语句来表示相同的意思。该函数在成功时返回SQLITEOK,在失败时返回适当的错误代码。 prepare 函数通过一个形式参数(如前面的示例中的 stmt)返回一个语句句柄(一个sqlite3 stmt类型的对象的指针),该句柄用于对准备好的语句执行进一步的操作。在前面的示例程序中,我将从Students 表中选择 SID 的语句作为语句句柄。该句柄类似于一个打开的游标,用于获取选择语句产生的结果行集,一次一行。游标通过执行sqlite3 step APl函数向前移动,我将在下面讨论该函数。
- sqlite3 step: 在使用 sqlite3 prepare 函数准备 SOL语句后,必须调用sqlite3_step 函数一次或多次来执行准备好的语句。每次调用 step 函数都会执行字节码程序,直到遇到断点(因为它产生了新的输出行)或直到没有更多行为止。在前一种情况下,该函数返回调用者SQLITE.ROW,在后一种情况下返回 SQLITE DONE。在前一种情况下,应用程序可以使用适当的 sqlite3 column*AP|函数读取行的列值。(参见列表中的下一个项目。)再次调用步骤函数以检索下一行。步骤函数移动 SELECT语分结果的游标位置。最初,游标指向输出行集的第一行之前。每次执行步骤函数时,游标指针都会移动到行集中的下一行。游标只能向前移动。对于不返回行的 SOL语句(如UPDATE、INSERT、DELETE、CREATE 和DROP),由于没有行需要处理,步骤函数始终返回SOLITE DONE。最终,step 函数返回 SOLITE DONE。(如果没有先调用 sqlite3 reset函数将程序执行重置回初始状态,则不应再次调用此语句句柄上的 step 函数。我稍后将讨论重置函数。) 如果在执行步骤函数时出现错误,返回代码为SOLITE BUSY、SOLITEERROR或SOLITE.MISUSE。SOLITE.BUSY表示引擎尝试访问一个繁忙(即锁定)的数据库,并且没有注册回调函数来解决这种情况,或者回调函数已决定中断执行。应用程序可以稍后再次调用步骤函数以重试预编译语句的执行。SOLITE ERROR表示发生运行时错误(如约束违反);不应再次在语句句柄上调用步骤函数。SOLITE MISUSE表示步骤函数调用不当。可能在已完成的预处理语句(即已关闭的语句)或先前返回SQLITEERROR或SOLITE DONE的语句上调用该语句。
- sqlite3 column :如果sqlite step函数返回SQLITE ROW,您可以通过执行sqlite3 columnAPI函数之一来检索该行中每个列的值。SOL/SOLite和C语言之间的数据类型不匹配由引擎自动处理:列函数将数据从一种语言转换为另一种语言,并从存储类型转换为请求的类型。(例如,如果值的内部表示是FLOAT,而应用程序请求文本输出值,则SOLite在内部使用sprintf()进行值转换。) 以下五个列AP|函数可用:sqlite3 column int,sqlite3 col int64,sqlite3 column double、sqlite3 column text和sqlite3 column blob 用于从列中读取数据。每个函数名称的最后一个部分指示应用程序可以从SQLite 库中期望哪种值。在上面的示例应用程序中,每个输出行都是一个整数值,我们通过执行sqlite3 column int函数来读取 SID 列的值,该函数返回整数值。(如果语句句柄当前未指向有效行,或者如果列索引超出范围,则这些函数产生的输出是未定义的。最左边的列的索引是0,下一个是1,下 2,等等。您可以使用 sqlite3 column countAPl函数获取列的总数量。对干非选择语句,它返回0。)Blob和文本值需要应用程序知道它们的大小。SOLite有sqlite3 column bytes函数,该函数返回列值的大小,单位为字节。
- sqlite3 finalize:此函数关闭并销毁一个语句句柄和相关联的预处理语句。也就是说它会擦除字节码程序,并释放分配给语句句柄的所有资源。语句句柄变为无效,不能再次使用。 如果语句执行成功或根本没有执行,则finalize 函数返回 SQLITE OK如果先前执行的语句失败,则该函数返回错误代码。finalize函数可以在执行预处理语句的任何时间点调用。如果引擎在执行此例程时尚未完成语句执行,则就像在执行过程中遇到错误或中断一样。不完整的更新将被回滚,执行将被中断,返回的结果代码将是 SOLITE ABORT。
- sqlite3 close:此函数关闭库连接,并释放分配给该连接的所有资源。连接句柄变为无效。如果成功,此函数返回SOLITEOK,如果失败,则返回其他错误代码。如果存在尚未完成的预处理语句,则返回SQLITEBUSY,连接保持打开状态。
- 其他有用的函数:上面讨论的六个(类别)API函数是SQLite库的核心,它处理两个主要数据结构,即sqlite3和sqlite3 stmt。其他广泛使用的API函数是sqlite3 bind *和sqlite3 reset. 在SOL语句字符串(传递给sqlite3 prepare函数的输入)中,您可以使用SQL位置参数标记’?'(或编号或命名的参数?NNN,:AAA,@AAA或SAAA,其中NNN是整数,AAA是字母数字标识符)替换一个或多个字面值。它们成为预处理语句的输入参数。对于无编号/无命名参数,最左边的参数具有索引1。对于编号参数,索引是数字。对于命名参数,索引可以通过以下方式获得调用 sqlite3 bind parameter index AP|函数。这些参数的值可以使用绑定函数设置。(如果在多个地方使用命名或编号参数,则对所有地方使用相同的绑定值。)如果未将值绑定到参数,则使用 SOLNULL值。以下七个绑定AP|函数可用:sqlite3 bind null、sqlite3 bind int、sqlite3 bind int64、sqlite3 bind double、sqlite3 bind text.sqlite3 bind blob和 sqlite3 bind value。每个函数名称的最后一个部分指示可以使用该函数将哪种值绑定到参数。(sqlite3 bindvalue函数帮助绑定泛型值。) 重置API函数将语句句柄(即预编译语句)重置为其初始状态,但有一个例外:所有已绑定值的参数保留其值。语句变得准备好由应用程序重新执行,并在重新执行时重用这些绑定值。但是,在开始重新执行之前,应用程序可以通过再次执行绑定函数来替换这些值的一部分或全部。或者,可以通过执行sqlite3 clear bindings APl函数来删除所有绑定值。 重置功能对于重复查询非常有用。
- 返回值:所有API函数都返回零整数或正整数值。SOLite开发团队强烈建议使用记忆术检查返回值,而不是硬编码整数值。返回值SOLTEOK表示成功;SQLITE ROW表示sqlite3step函数在SE-LECT语句返回的行集中找到了新行;SOLITE·DONE表示语句执行完成。截至SOLite3.7.8发行版,共有28个主要的和一些扩展的成功和错误代码。由于返回代码是SQLite接口的一部分,它们的值不会从一个小版本到另一个版本发生变化。
总之,应用程序准备SOL语句,如果需要,则将值绑定到准备好的语句多次执行准备好的语句,然后重置准备好的语句以便再次执行具有相同或不同绑定值的语句。应用程序最终确定语句以销毁准备好的语句。 Unicode AP1:上述API函数处理UTF-8编码的输入文本。还有单独的API函数只处理UTF-16编码的文本。
2.2.3 SOL直接执行
图2.42展示了另一个可以从命令行运行的SQLite应用程序,用于交互式地操作数据库。该命令有两个参数:第一个参数是数据库文件名,第二个是 SQL语句。它首先打开数据库文件,然后通过执行sqlite3execAPI函数将语句应用于数据库,最后关闭数据库文件。exec函数直接执行SQL语句,而不需要应用程序像之前的示例应用程序那样手动执行prepare、step 和 finalize AP|函数。如果语句产生输出,则 exec函数为每个输出行执行回调函数,并允许应用程序进一步处理该行。您必须对给定的数据库文件拥有读取权限,并且根据查询类型,您可能需要对文件及其包含的目录拥有写入权限。
#include <stdio.h>
include "sqlite3.h"
static int callback(void *unused, int argc, char **argv, char **colName)
{
int i;
for(i= 0;i< argc; i++) {//Loop over each column in the current row
printf("%s=%s\n",colNamel[i],argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
int main(int argc, char **argv){
sqlite3*db=0;
char*errMsg=0:
int rc;
if (argc != 3){
fprintf(stderr, "Usage: %S DATABASE-NAME SQL-STATEMENT\n", argv0]);
return -l;
}
rc= sqlite3_open(argv1,&db)
if (re != SQLITE_OK) {
fprintf(stderr,"Can't open database %s: %s\n",argv1,sqlite3_errmsg(db));
sqlite3_close(db);
return -2;
}
rc=sqlite3_exec(db,argv2,callback,0,&errMsg);
if (re != SQLITE_OK) {
fprintf(stderr,"SQL execution error:%s\n",errMsg)
}
sqlite3_close(db);
return rc;
}
sqlite3 exec: 此函数直接执行一个或多个 SOL语句。(两个连续的 SOL语句由分号分隔。)在内部,它按输入的左到右顺序依次编译和执行语句。如果任何语句执行结果导致错误,则不执行剩余的语句。如果语句有SOL参数标记,则使用 SOLNULL值。如果语句产生输出,则exec函数为每个输出行调用用户指定的回调函数。回调函数的签名可以在图2.4中找到。(column)和finalize函数的方exec 函数是prepare、蓙淫闰Ⓜ笙step',便包装器。然而,SQLite开发团队不鼓励使用该函数,因为他们可能会在未来的版本中删除它。
sqlite3 errmsg: 在API函数执行过程中发生错误时,可以通过调用此函数获取有关错误的更多信息。该函数返回在库连接上发生的最后一个错误。消息基本上是错误的一种英语描述。 您可以将应用程序代码编译成可执行文件,例如app2。现在,您可以发出对数据库操作的SQL语句。假设您在当前工作目录中处理同一个MyDB数据库。通过执行以下命令行,您可以在Students表中插入新行:
/app2 MyDB "insert into Students values(100)"
/app2 MyDB "insert into Students values(10)"
/app2 MyDB "insert into Students values(1000)"
如果您现在运行上一个应用程序(app1),您将看到以下输出: SID = 10 SID = 100 SID = 100 SID = 200 SID = 300 SID = 1000 你也可以在数据库中创建新表;例如,./app2MyDBExtn"create table Coursesname varchar,SlDinteger)“在当前工作目录中的新MyDBExtn数据库中创建Courses表。 注意: SQLite有一个前面提到的交互式命令行实用程序(sqlite3),您可以使用它来发出SOL命令。您可以从SOLite下载网页下载预编译的二进制版本,或者从源代码中编译。这个app2示例本质上是 sqlite3的基本实现。
2.2.4 多线程应用程序
SQLite 可以在单线程或多线程模式下使用。对于后者,一个进程中的多个线程可以通过相同的库连接同时访问相同或不同的数据库。但是,为了使它成为一个线程安全的库,它必须以稍微不同的方式构建。
线程模式: 线程模式由SQLITE.THREADSAFE预处理器宏控制。为了线程安全,SQLite源代码必须在宏设置为1(用于序列化和2(用于正常多线程)时编译。如果宏设置为0,则库处于单线程模式。这意味着单个进程中的多个线程可以使用相同的SQLite库,但由单个线程创建的SQLite(连接和语句)无法安全地由另一个线程使用;同时使用多个线程同时使用SQLite也是不安全的。在前两种情况下,这种限制被放宽,并且该库被称为“fthread-safe”。在正常的多线程模式(安全值2)下,虽然多个线程可以使用相同的库连接,但它们不能同时使用;它们可以相互排他地使用连接:它们可以同时使用不同的连接。在列化的多线程模式下没有这样的限制。默认是序列化模式。您可以通过调用sqlite3 threadsafe API函数来找出您使用的SQLite库是否线程安全。如果编译时选项是多线程或席列化的,则可以在库启动时或运行时使用sqlite3 open v2或sqlite3 configAPl函数更改此选项。
图2.5展示了一个非常简单的多线程应用程序。该应用程序创建了10个线程,每个线程都尝试在同一MyDB数据库的Students表中插入一行。SOLite实现了一种基于锁的并发方案,因此由于锁冲突,一些INSERT语句可能会失败。应用程序不需要担心并发控制和数据库一致性问题;它不会破坏数据库。SOLite会处理并发控制和一致性问题。但是,您需要检查失败情况,并在代码中适当地处理它们(例如,您可以重试失败的语句,或者通知用户失败并让她3决定下一步做什么)。
#include <stdio.h>
#include <pthread.h>
#include "sqlite3.h"
void* myInsert(void* arg)
{
sqlite3* db =0;
sqlite3_stmt*stmt=0;
int val=(int)arg;
int SQL[100];
int rc;
rc=sqlite3_open("MyDB",&db);/* Open a database named MyDB */
if(rc != SQLITE_OK){
fprintf(stderr,"Thread%d fails to open the MyDB database\n", val);
goto errorRet:
}
sprintf(SQL, "insert into Students values(%d)", val);/* Dynamically compose a SQL*/
rc=sqlite3_prepare(db, SQL,-1,&stmt, 0);/* Prepare the insert statement */
if (rc != SOLITE OK){
fprintf(stderr, "Thread %d fails to prepare SQL: %s; return code %d\n", val, $QL, rc)
goto errorRet;
}
rc= sqlite3_step(stmt);
if(rc != SOLITE DONE) {
fprintf(stderr,"Thread %d fails to execute SQL: %s; return code %d\n", val. SOL,rc)
} else {
printf(”Thread[%dsuccessfully executes $QL: %s\n”, val, SQL);
}
sqlite3_fnalize(stmt),
errorRet:
sqlte3_close(db)
return(void*)rc;
}
int main(void)
{
pthread_t t[10];
int i;
for(i=0:i < 10; i++) {
pthread_create(&ti,0,myInsert,(void*)i);/* pass the value of i */
}
for (i=0;i< 10; i++) {
pthread_join(&ti,0); /* wait for all threads to finish */
}
return 0;
}
警告! 此应用程序可能无法在Windows和MacOSX上“直接”运行。您可能需要重新编译带有线程支持的SOLite,并/或获取pthread库以使该应用程序在这些平台上运行。MacOSX包含pthread,您可以在http://sourceware.org/pthreads-win32/上获取Windows的pthread库
在示例应用程序中,每个线程都打开自己的连接到相同的数据库,并在连接柄上工作。这在早期的SOLite版本中是工作模式。对于这些版本,SQLite开发团队不建议在跨线程中使用任何SQLite句柄。尽管SQLiteAPI可能在跨线程使用句柄时工作,但其正确性无法保证。实际上,在某些版本的Linux中,SOLite库可能会崩溃并产生核心转储。
在 SOLite 3.3.1及后续版本中,对线程间共享库连接的上述限制有所放宽。线程可以在互斥(在正常多线程模式下)中安全地使用库连接。这意味着,只要前一个线程没有在连接上持有任何本地文件锁定,你就可以将连接从一个线程切换到另一个线程。如果线程没有未决事务,并且已经重置或完成了连接上的所有语句,则可以安全地假设没有持有任何锁定。在序列化模式下,没有这样的限制。 Fork Warning! 在Unix/Linux系统中,您不能通过fork系统调用将打开的SOLite数据库传递给子进程。如果您这样做,可能会出现数据库损坏或应用程序崩溃等问题。
2.2.5使用多个数据库
图2.6显示了一个在两个数据库上工作的典型SQLite应用程序。(我简化了代码,没有包括函数调用的错误检查。)应用程序首先打开MyDB数据库,然后将MyDBExtn数据库附加到当前库连接。在完成附加命令的执行后,单个库连接具有两个数据库连接,应用程序现在可以通过相同的库连接访问两个数据库中的所有表。我假设MyDB数据库有一个Students(SID)表,MyDBExtn数据库有一个Courses(name,SID)表。应用程序执行SQL选择语句,访问两个数据库中的两个表。
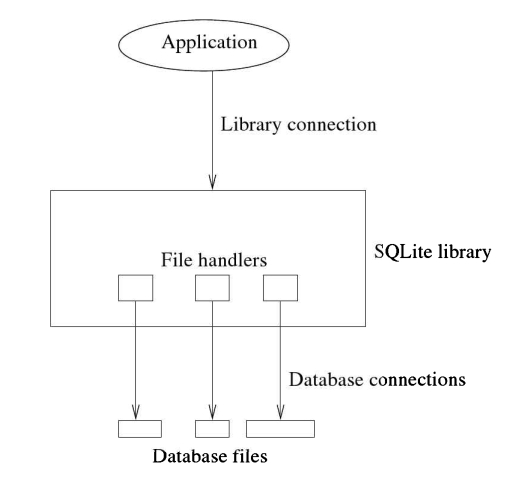
Library Connection vs,Database Connection Confusion: 与SOLite库的连接可以关联多个数据库。参见图2.7。在图中,单个库连接具有三个数据库连接,每个连接都指向不同的数据库文件。应用程序可以通过相同的库连接访问所有数据库虽然应用程序只看到一个库连接,但在内部,SQLite会打开多个数据库连接,每个数据库一个。如果一个库连接只有一个数据库,
#include <stdio.h>
#include "sqlite3.h"
int main(void)
{
sqlite3* db=0;
sqlite3_open("MyDB",&db);/* Open a database named MyDB */
sqlite3_exec(db,"attach database MyDBExtn as DB1",0, 0, 0);
sqlite3_exec(db,"select* from Students S,Courses C where S.sid= C.sid", callback, 0. 0);sqlite3_close(db);
return 0;
}
我们天真地把它也称为数据库连接。你已经被警告过连接混乱
2.2.6处理交易
图2.8显示了一个使用事务的典型SOLite应用程序。该应用程序通过执行begin命令来打开事务,在事务内部将一行插入到学生表中,另一行插入到课程表中,最后通过执行commit命令提交事务。INSERT语句不需要回调函数,因此,在示例应用程序中的sqlite3exec调用中,我将0作为回调参数传递。如果第二个插入失败,您可以执行回滚命令而不是提交命令,第一个插入将被撤销。我将在第63页第2.3节中更多地谈论交易。
注意: SOLite允许在单个exec API调用中包含多个SOL语句;图2.8中的同一批命令可以通过在单个exec调用中传递此语句序列来执行:
#include <stdio.h>
#include "sqlite3.h"
int main(void)
{
sqlite3*db=0;
sqlite3_open("MyDB",&db);/*Open a database named MyDB */
sqlite3_exec(db,"attach database MyDBExtn as DB1",0, 0, 0);
sqlite3_exec(db,"begin",0,0,0);
sqlite3_exec(db,"insert into Students values(2000)",0,0,0);
sqlite3_exec(db,"commit",0.0,0);
sqlite3_exec(db,"insert into Courses values('SQLite Database’, 2000)",0,0. 0);
sqlite3_close(db);
return O;
}
2.2.7 使用目录
数据库系统还存储有关用户信息的信息(元)信息。元信息也被表示为称为目录或系统表的表格,以区别于用户表。实质上,目录是由SOLite本身创建和维护的表格,它存储有关数据库的一些元信息。在每个数据库中,SOLite维护一个名为sqlite master的主目录。主目录存储有关表、索引、触发器和视图的架构信息。您可以查询主目录(例如,select*fromsqlitemaster),但您不能手动删除或直接修改目录。还有其他可选的目录表。所有目录表名称都以 sqlite 的前缀开始,这些名称是 SQLite 开发团队为内部使用而保留的。(你不能以大写、小写或混合大小写的方式创建具有这些名称的数据库对象,如表、视图、索引和触发器。)在第 67 页的第 2.4节中,我将更详细地讨论目录。
2.2.8 使用 sqlite3 可执行文件
上述示例应用程序使用 SOLite 库形式。您可以将 SOLite 构建为独立实用程序应用程序:它通常被称为 sqlite3。(这与用作连接句柄的 sqlite3 对象不同。)此实用程序允许您手动执行 SOL语句。它还支持 SOLite特定的点命令:这些命令以点"开头。例如,sqlite3.help 将为您提供该实用程序支持的所有点命令的列表。点命令是方便的实用函数,用于获取有关模式、导入/导出数据、设置各种显示选项等信息。例如,sqlite3 MyDB.dump将整个数据库输出到标准输出。在本书中,我不讨论 sqlite3 实用程序。您可以访问 SOLite 网页 http://www.sqlite.org/sqlite.htm! 以了解点命令。
2.3 Transactional Support
SQLite 为数据库用户提供了一个轻松开发和运行数据库应用程序(C程序)的环境。它处理动态 SQL语句,这些语句可以在运行时组装,并确保语句执行的 ACID 属性。默认情况下,SOLite 在自动提交模式下运行。在这种模式下,它执行每个 SQL语句,每个SOL语句都是一个独立的事务:对于SQL查询语句是读取事务,对于其他语句是写入事务。对于每个SQL语句,它都会创建一个新的事务,并在语句执行结束时关闭(即提交或取消)该事务。也就是说,对于每个SOL语句,一旦语句执行成功完成或失败,数据库中的所有更改都将立即提交或撤销。这些事务对应用程序是透明的。也就是说,应用程序不需要包含处理这些事务的代码,应用程序逻辑也不依赖于这些事务的管理。
警告! 在SOLite文档中,他们通常指写事务。在这本书中,当需要时,我区分读事务和写事务。读事务在SQLite中是隐含的。因此,存在一些混淆的范畴。你已经得到了警告!
默认的自动提交模式可能对某些应用程序非常昂贵,并且对性能有害,特别是对于高写入密集型的应用程序。这是因为SQLite需要为每个SQL插入、删除和更新语句重新打开、写入和关闭日志文件。此外,由于应用程序需要为每个SQL语句执行重新获取和释放数据库文件上的锁,因此还存在并发控制开销。这些开销可能会导致显著的性能损失(特别是对于大型应用程序。开销只能通过围绕许多 SQL语句打开一个“用户级”事务来减少。应用程序可以在“BEGINTRANSACTION”命令和“COMMITTRANSACTION或“ROLLBACKTRANSACTION”命令中包含一系列SOL语句。(关键字 TRANSACTION 是可选的。)我在第62页的图2.8中展示了一个这样的应用程序。除了少数例外,您可以将任何 SOL语句放入用户事务中。
BEGIN 命令使 SQLite 退出自动提交模式,我们说系统处于手动提交模式。连续SQL语句的影响成为用户事务的一部分。执行COMMIT/ROLLBACK命令会关闭用户事务,SQLite 返回自动提交模式。COMMIT命令实际上工作得有些不同。它可能不会立即完成整个事务。如果有未完成的更新操作,则提交失败,事务保持打开状态。否则,它将事务中的所有更改提交到数据库,然后启用默认的自动提交模式。(您可以确信,在提交结束时,事务中执行的所有 SOL语句的所有更改都将生效并永久化。)这提交写事务,但如果有正在进行的查询语句执行,则事务在自动提交模式下转换为读事务。然后,在读事务内所有挂起的选择陈述执行(如果有)结束时,常规自动提交逻辑接管并导致读事务的实际提交。ROLLBACK命令还通过打开自动提交返回来操作,但它还设置了一个标志,告诉自动提交逻辑回滚而不是提交用户事务。然而,ROLLBACK命令可以终止部分或所有挂起的选择执行。(The从写事务修改的表中读取的选择执行将被取消。它们各自下次调用sqlite3step API函数时将得到SQLITE ABORT错误代码。
总之,一个典型的应用程序通过执行“BEGINTRANSACTION”命令来启动用户事务。所有后续的SQL语句都在事务内执行。在某个时间之后,应用程序执行“ROLLBACKTRANSACTION”命令来中断事务或“COMMITTRANSACTION”命令来使更新持久化。无论哪种情况,事务都会结束,SQLite都会恢复到自动提交模式。要启动新的用户事务,应用程序需要再次执行“BEGIN TRANSACTION”命令。如果应用程序未在用户事务中显式执行“COMMITTRANSACTION”或“ROLL-BACKTRANSACTION”命令,则SQLite将在应用程序关闭数据库连接时回滚事务。
图2.9展示了另一个使用用户事务能力的应用程序。该应用程序打开一个用户级事务,然后在事务中插入四行,最后提交事务。如果在到达提交语句之前发生任何错误,它将关闭数据库连接。因此,在下一个数据库关闭API调用期间,SOLite会自动回滚事务。
SQLite支持标准的平面事务模型:事务中的所有操作要么一起成功,要么全部回滚。无法提交或回滚事务的一部分。SOLite不支持歌套事务。因此在事务中执行“BEGIN TRANSACTION”命令没有任何效果,实际上,SOLite不会处理该语句,而是返回错误代码给应用程序。由于应用程序一次不能在打开的库连接上打开多个用户事务,因此在SQLite中事务管理大大简化。如果语句执行失败,SOLite不会强行中止容器事务(除非冲突解决程序指示回滚)。如果在事务中通过多个API调用拆分SOL语句,则您的应用程序必须处理这些调用中的每个失败,因为否则应用程序的行为可能会异常。如果确实发生失败,SQLite会自动中止相应的SOL语句,但不会中止整个用户事务。在最终提交或中止之前,事务可以继续执行其他新的SQL语句。SQLite还支持设置手动保存点,应用程序可以通过回滚某些最近的SOL语句执行的效果来稍后回滚。Savepoint允许事务恢复到先前建立的数据库状态。
int main(void)
{
sqlite3*db=NULL;
int retcode;
retcode= sqlite3_open("MyDB", &db);//Open a database named MyDB */
if (retcode != SQLITE_OK) goto errorRet;
retcode= sqlite3_exec(db,"begin transaction",NULL,NULL, NULL;
if (retcode != SQLITE_OK) goto errorRet;
retcode= sqlite3_exec(db,"insert into Students values(1001,'Sibsankar’Sunnyvale, California’)",NULL,NULL,NULL);
if(retcode != SQLITE_OK) goto errorRet;
retcode= sqlite3_exec(db,"insert into Students values(1002, 'Richard'.Charlotte,North Carolina’",NULL,NUL,NULL);
if (retcode != SQLITE_OK) goto errorRet;
retcode= sqlite3_exec(db,"insert into Students values(1003, 'Richard’.Sunnyvale,California'",NULL,NULL,NULL);
if(retcode != SQLITE OK) goto errorRet;
retcode=sqlite3_exec(db,"insert into Students values(1004,'Sibsankar’
Charlotte,North Carolina’)",NULL,NULL,NULL);
if (retcode != SQLITE OK) goto errorRet;
retcode = sqlite3_exec(db,"commit transaction”,NULL,NULL, NULL):errorRet:
sqlite3_close(db)";
return retcode
}
下两个小节将讨论事务管理的两大支柱,即并发控制和故障恢复。
2.3.1并发控制
SQLite将整个数据库存储在单个本地文件中。它实现了一个简单的数据库级(而不是表、行、列或单元格级)锁定框架,在支持的本地操作系统文件锁定原语之上,以协调事务对数据库的访问。它允许许多并发读取事务,但数据库上只能有一个写入事务。这意味着如果任何事务正在从数据库的任何部分读取,则所有其他事务(在本进程和其他进程中)都被阻止写入数据库的任何其他部分。同样,如果任何事务向数据库的任何部分写入,则所有其他事务都禁止读取或写入数据库的任何其他部分。SOLite遵循严格的两阶段锁定(即在事务终止时释放锁),从而确保并发事务的可串行执行。
2.3.2数据库恢复
SQLite为每个数据库文件使用一个单独的日志文件,以便在应用程序决定中止事务时提供回滚写事务的能力。(没有回滚日志用于读事务。)回滚日志总是创建在与数据库文件相同的目录中,具有相同的名称,但未尾添加”-journal'。(例如,MyDB数据库将具有’MyDB-journal’文件,用于存储恢复信息。)日志文件以日志记录的形式存储与事务执行期间对数据库文件所做的所有更改相关的信息。该日志是一个按条目顺序排列的文件,并将日志记录存储在当前事务产生的相同顺序中。SQLite使用物理或值日志进行撤销。SOLite日志效率低下:即使事务只修改了页面中的一个字节,每个日志记录都包含整个数据库页面的图像。这样做是为了使恢复逻辑尽可能简单,并控制SQLite库的大小。
日志文件保留: 您可能会注意到,在 SQLite 中,日志是默认操作模式下的临时文件。SQLite为每个写事务创建日志文件,并在事务完成时删除该文件。实际上,在提交的情况下,日志文件的删除是事务提交点。有选项可以避免删除日志文件将其截断为零,或在事务提交/取消时无效化。(无效化选项也可能将文件截断为预先定义的大小。)这些选项在文件创建和删除成本较高的平台上将非常有益。在后续中,我使用“日志最终化”一词来指代这四个选项中的任何一个。在SQLite 3.7.0版本中,他们引入了一种新的日志记录方案,称为WAL,其中使用“wal”日志文件代替“-journa!”文件,并在事务提交/取消后保留。我将在第249页的10.17节中讨论WAL日志记录。
在用户事务中,SOLite以单独的方式执行每个(非选择性)SOL语句子事务。您可能会注意到,在用户事务中最多只能有一个子事务打开。也就是说,事务中不能有并发更新。(但是,可以与子事务执行并发执行的SELECT语句执行可以有任意数量。我在后面的章节中详细讨论。)当前子事务的失败不会自动中止容器事务(或并发SELECT语句执行)。每个子事务使用一个单独的临时文件作为语句日志,用于仅存储语句级恢复的信息。 SQLite允许应用程序在单个用户事务中操作多个数据库。在这种情况下对图书馆连接的事务显式为每个数据库连接上的单独事务。SOLite使用各自的回滚日志文件,并另外使用一个主日志文件。主日志仅记录单个回滚日志文件的名字。我将在第4和第5章中更详细地讨论日志。
2.4 SOLite目录
大多数DBMS将有关所有用户表和不同表中索引的元信息保存在称为目录的不同表中。在RDBMS中,目录本身是表(通常称为系统表)。RDBMS通常以与用户表在数据库中存储相同的方式存储它们。例如,式描述(SQL创建语句)作为行存储在目录中。通常,会有不同的目录用于不同的目的。我们可能有一个目录用于存储所有表名;另一个用于表属性名称、它们的类型和任何默认值;另一个用于完整性约束。 我们还可能有一个用于查看名称及其定义的目录,另一个用于索引信息的目录,以此类推。 不同的RDBMS维护不同的目录数量。SOLite简化了目录的使用,并仅维护一个目录。它在一个名为sqlite master的单个目录中存储有关表、索引、触发器和视图的架构信息。4 主表存储在数据库文件本身的一个特定位置。主表的结构如下,使用等效的SQL创建表语句表示。
create table sqlite_master(
text.type
text.name
tbl_name text,
rootpage integer,
text
);
4尽管还有其他可选的目录。主目录是唯一始终存在于数据库中的目录。所有目录名称都以sqlite_的前缀开始,这些名称是 SQLite 开发团队为内部使用而保留的。您不能创建具有此类名称的数据库对象(表、视图、索引和触发器)(大写、小写或混合大小写)。
当数据库初始化时,主表被创建并初始化为空。当你执行新的架构定义(一个创建 SOL语句)时,主表会添加一行。这行描述了刚刚创建的新对象。类型列指定该对象是表、视图、索引还是触发器,其值分别为“table“view”或“trigger”。名称列指定该对象的名称。(“in煺拌dex”对于自动创建的索引,名称是“sqlite autoindex TABLE N”,其中TABLE是索引所在的表名,N是一个从1开始的整数。)tblname列指定该对象关联的表或视图名称。(对于表和视图,其值与名称列的值相同。)rootpage列指定对象(B树或B+树)的根所在的数据库页号。5sq1列指定创建此类对象的SQL语句。(在sql列中,SQLite将关键字转换为大写,删除冗余空格等。对于SOLite为唯一约束创建的索引,sql列将为NULL。)SOLite数据库中的每个对象(除sqlitemaster表外)在sqlitemaster表中都有一个条目。当 SQLite 打开并读取数据库文件时,它会首先扫描整个主表,预处理每一行的 sql列,并生成许多内存中的目录对象,这些对象实际上相当于许多 DBMS 中使用的不同的持久目录表。这些内存中的目录对象共同定义了一个模式缓存。
还有一个名为sqlite_temp_master的目录表,它在运行时可用,并存储有关所有临时对象(表、索引、触发器和视图)的架构信息。您可能会注意到,对于每个打开的库连接,SQLite维护一个并行、用户透明、临时数据库,该数据库存储在库连接上创建的所有临时对象。(这意味着每个库连接至少建立两个数据库连接,其中一个用于临时数据库。)例如,您可以通过在库连接上执行createtemp table templ(ainteger primary key,bvarchar)语句在临时数据库中创建一个临时表temp 1。临时数据库存储在本地文件系统默认临时文件目录中的-个临时文件中。该文件对其他由相同或不同进程打开的与SQLite库的连接是不可见的。当应用程序关闭库连接时,临时文件会被SQLite删除。temp目录的逻辑结构与以下SOL语句创建的表等效:createtemptablesqlite temp master(type text, name text,tbl _name text,rootpage integer,sqltext)。这些列与sqlite_master架构中相同。
如果rootpage值为0,表示该对象物理上不存在。表和索引非零,视图和触发器为零。
您可以通过执行SELECT语句来查询这两个主表,就像它们是任何其他用户表一样。但是,您不允许直接使用INSERT、DELETE或UPDATE语句更改这两个表。您也不能在这些表上创建索引。SQLite也不会在这些表上创建索引。更改主表必须使用用户对象(如表、索引)的CREATE、ALTER和DROP语句,因为当添加或删除表和索引时,SOLite也需要更新其内部内存目录对象。 SQLite引擎会自动执行这些操作。您可能会注意到,通过主表SOLite跟踪数据库中所有其他表和索引树,因此,它是SOLite数据库中最珍贵的对象。
没有其他与创建语句相关的目录。有可选目录。例如,SOLite可以根据需要创建另一个名为sqlite sequence的目录。如果任何用户表具有“整数主键自动递增”列,则SQLite将为用户表在序列目录中维护一行。目录结构与以下SQL语句创建的表等效:createtablesqlite sequence(nametext,seqinteger)。name列指定表名称。seq是迄今为止为自动递增列分配的最大值。(您可能会注意到,表最多只能有一个自动递增列,这就是为什么列名不会出现在序列目录中。)序列目录是在您尝试在具有整数主键自动递增列的任何用户表中插入一行时创建的。一旦创建,该表将永远不会被删除。SOLite还使用其他可选目录,我稍后会讨论一些。
2.5 SOLite的限制
在前面的章节中,您已经看到了 SQLite 的强大之处,但它也有一些缺点。SQLite 与大多数其他现代 SQL数据库不同,其主要设计目标是简单。SOLite 开发团队牢记这一目标,为DBMS添加新功能,即使这会导致某些功能的低效实现。以下是 SOLite 的缺点列表:
-
SQL-92功能:如前所述,SQLite不支持许多企业数据库系统中可用的某些ANSI SQL-92功能。您可以从http://www.sqlite.org/omitted.html网页获取最新信息。
-
没有嵌套:SQLite只支持Hat事务;它不具有一般的嵌套能力(嵌套意味着在事务中具有完整的子事务的能力)。后者为前者提供了一个执行环境。
-
低并发:SQLite无法确保高度的事务并发。它使用文件级锁来实现并发控制,即在数据库文件的粒度上检测访问冲突。它允许多个并发读取事务,但单个数据库文件上只能有一个独占写入事务。这一限制意味着如果任何事务正在从数据库文件的任何部分读取,则所有其他事务将被阻止写入文件中的任何部分。同样,如果任何事务正在向数据库文件的任何部分写入,则所有其他事务将被阻止读取或写入文件中的任何部分。
-
应用程序限制:由于其有限的并发事务,SQLite仅适用于小型事务,其中每个事务都能快速完成数据库工作,因此没有事务会占用数据库超过几毫秒。但是,有些应用程序,特别是写密集型应用程序,需要更精细的并发粒度(表或行级锁定,而不是数据库级锁定),您可能更愿意为这些应用程序使用不同的DBMS解决方案。SQLite不是用来取代企业级DBMS的。在数据库实现、维护和管理的简单性比企业DBMS提供的复杂功能更重要的情况下,这是一个很好的选择。
-
NFS问题:SQLite使用原生操作系统支持的锁原语进行并发控制。当数据库文件位于网络分区时,这可能会导致一些问题。许多NFS实现(在Unix和Windows上)在文件锁定逻辑中已知存在错误。如果文件锁定没有按SOLite预期的方式工作,则可能同时由两个或多个事务修改同一数据库;这可能会导致数据库损坏。由于此问题源于底层文件系统实现的错误,因此SOLite开发团队无法找到解决方案来防止它。 另一个淘气的事情是,由于大多数NFS的高延迟,数据库性能可能不好。在这样的环境中,数据库文件必须通过网络访问,实现客户机-服务器模式的DBMS可能比SOLite更有效。
-
数据库对象的数量和类型:表或索引最多限制为264-1个条目。(当然由于247字节的数据库大小限制,您不能有这么多条目;我在第84页的3.2.1节中讨论了此限制。)在SQLite的当前实现中,单个条目最多可以存储231-1(=2,147,483,647)字节的数据。(底层文件格式支持最多约262字节的数据大小。同样,字符串或BLOB数据的最大数据大小为2311;默认值为10亿。):在打开数据库文件时,SOLite会读取并预处理主目录表中的所有条目。创建许多内存中的目录对象。因此,为了获得最佳性能,最好保持表索引、视图和触发器的数量。同样,表、索引、视图、选择的结果集更新的集合列表、分组/排序的术语数量、插入的值数量都有限制。默认值为2000,但可以高达32,767。但是,索引的前63个列是某些优化的候选项。SQL语句的长度、连接中的表数量(最大为64)等也有其他限制。
您可以使用 sqlite3_limit APl函数按限制类别更改各种参数(对于库连接)的极限值。限制类别为:(1)字符串、BLOB 或表行的长度,(2)SOL语句的长度,(3)表定义、选择结果列、索引、orderby、groupby的列数,4)任何表达式上的解析树深度,(5)复合选择语句中的术语数,(6)SOL函数中的参数数,(7)附加数据库数,(8)LIKE或 GLOB 中模式参数的字符串长度,(9)具有有限值的 SQL语句中的参数数,(10)触发器的递归深度,(11)连接中的表数,(12)数据库文件中的页数。每个类别都有硬上界,您的应用程序不能跨越。看见http://www.sqlite.org/limits.html.
-
主机变量引用:在某些嵌入式数据库管理系统中,SOL语句可以直接引用主机变量(即来自应用程序空间的变量)。在SQLite中这是不可能的。相反,SOLite允许使用sqlite3 bind*API函数将主机变量绑定到SQL语句作为输入参数,而不是输出值。这种方法通常比直接访问方法更好,因为后者需要一个特殊的预处理程序将SOL语句转换为特殊的API调用。
-
存储过程:许多数据库管理系统都有创建和存储存储过程的能力。存储过程是一组SQL语句,形成一个逻辑工作单元并执行特定任务。SQL查询可以使用这些过程。SOLite没有这种能力。
2.6 SOLite体系结构
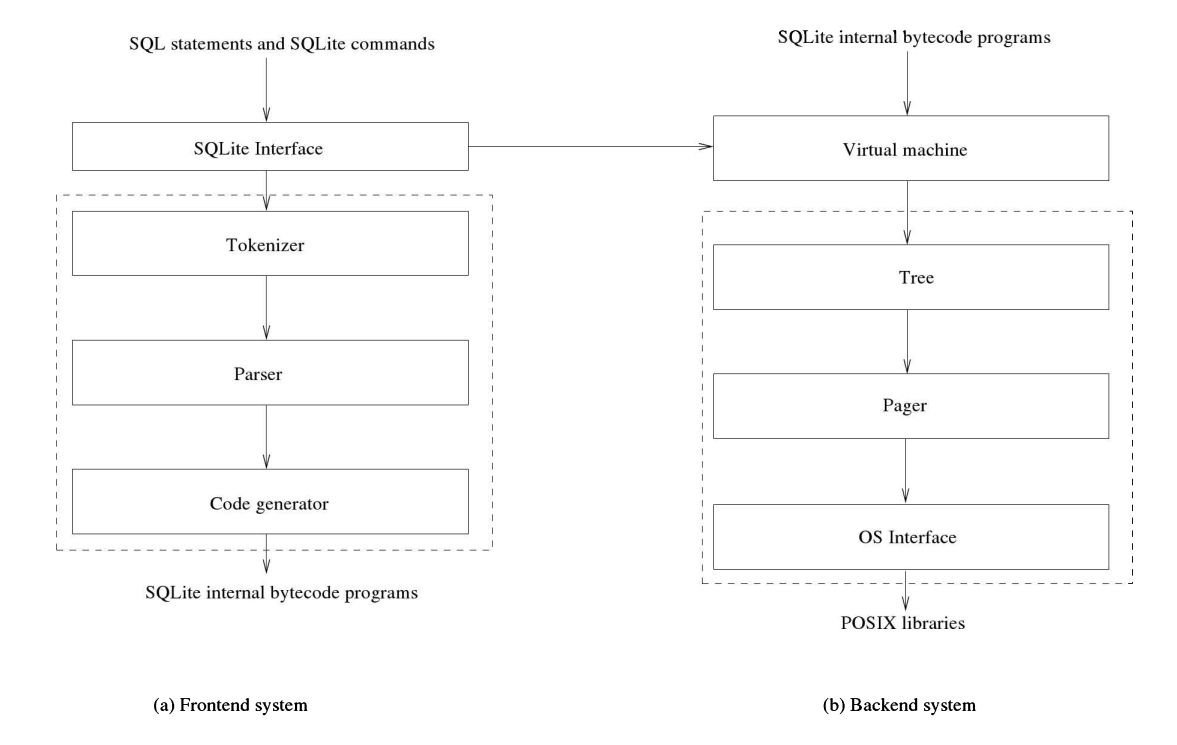
SQLite开发团队宣称采用非常模块化的架构。该架构由七个主要组件子系统(也称为模块)组成,分为两个部分:前端解析系统和后端引擎。前端编译每个SOL语句,后端执行编译后的语句。图2.10中给出了两个方块图,显示了组件子系统及其相互关系。每个方块图都是一堆模块。
 架构: 系统的架构提供了一种模型,说明系统如何被划分为子系统,以及这些子系统如何相互通信。换句话说,子系统的排列及其关系就是架构。
架构: 系统的架构提供了一种模型,说明系统如何被划分为子系统,以及这些子系统如何相互通信。换句话说,子系统的排列及其关系就是架构。
2.6.1前端
前端预处理由应用程序作为输入发送到它的SOL语句和SQLite命令。它解析这些语句(和命令),优化它们,并生成后端可以执行的等值SQLite内部字节码程序。前端划分由三个模块组成:记号赋予器、解析器和代码生成器。
- 令牌器:它将输入的SQL语句分成令牌。
- 解析器:它通过分析分词器产生的标记来分析 SQL语句的结构,并从标记生成解析树。解析器还包括一个优化器,该优化器重新构建解析树,并找到等效的解析树,该解析树将产生高效的字节码程序。
- 代码生成器:它遍历解析树,生成一个等价的字节码程序,当后端执行时,将产生SQL语句的效果。
前端实现sqlite3_prepare APl函数。在函数执行过程中,解析和代码生成步骤交织在一起。
2.6.2后端
后端是执行由前端生成的字节码程序的引擎。引擎执行实际的数据库处理工作。后端部分由四个模块组成:虚拟机、树、分页器和操作系统接口。
- 虚拟机(VM):它执行字节码程序以执行相应的SQL语句和SQLite命令。它是来自数据库的最终数据操纵者。它将数据库视为表和索引的集合,其中表或索引是一组元组或记录。
- tree: 它将每个元组集组织成一个有序的树数据结构;表和索引分别存储在单独的B+-树和B-树中。它帮助虚拟机在树中搜索、插入、删除和更新元组。它还帮助虚拟机创建新树并删除旧树。
- pager: 它在原生字节导向文件的基础上实现了一个面向页的数据库文件抽象。它管理一个内存中的缓存(数据库页),树块使用这个缓存,此外,它还管理锁定和页面日志记录,以实现事务性的ACID属性。它是SQLite中的数据、锁定、日志和交易管理器。 *操作系统界面: 它为不同的原生操作系统提供了统一的界面。这是一个非常薄的层,它使SOLite应用程序独立于原生操作系统。它实现了文件I0、线程互斥、休眠、定时、随机数生成等例程。 后端实现了sqlite3 bind *、sqlite3 step、sqlite 3column *、SQLite3 reset和sqlite3 finalize APl函数。
2.6.3界面
应用程序不能直接访问前端或后端(内部)API。前者需要通过顶层的SQLite接口层将请求转发给后者。这是数据库应用程序与SQLite库交互的唯一方式。接口将请求路由到前端或后端。
2.7 SQLite源组织
SOLite的源代码被组织成单个主目录(名为sqlite)和七个主要子目录:artcontrib、doc、ext、src、test和tool。art子目录包含许多与SOLite徽标相关的GIF文件。contrib子目录包含一个TCL/TK控制台小部件。doc子目录包含关于Lemon解析器生成器的程序员文档。ext子目录包含可加载的版本扩展,如异步I/0、rtree、fts(全文本搜索)和icu(用于Unicode的国际化组件)。src 子目录包含构建 SOLite库和 sqlite3 可执行文件的源代码。它大约有 94个C代码和头文件(73个.c和15个.h;在编译过程中生成6 个)。还有 11个文件用于 FTS3和 RTREE 扩展。截至 SQLite 3.7.8发布版本,这些文件中大约有 114K行文本(68K代码和46K注释)。测试子目录包含许多旨在验证 SQLite 库可靠性的回归测试。工具子目录包含代码生成器的源代码。它包含了Lemon解析器生成器的源代码:lemon.c和lempar.c,以及由词法分析器使用的关键字哈希表生成器的源代码:mkkeywordhash.c。顶层sqlite目录包含几个控制文件。(1)makefiles和实用程序用于从src目录构建SOLite库和sqlite3可执行文件。(2)VERSION文件包含发布6的版本号。(3)configure、configure.ac、Makefile.in和其他文件由GNUautoconf使用。(4)为Linux、vxworksarm 和 main.mk提供的替代 Makefile提供了更多的控制,并用于交叉编译。风(5)publish.sh 是一个 shell 脚本,为 SOLite 网站构建一个发布版本。
在以下小节中,我将讨论如何从src目录中的源文件中构建SQLite组件子系统/模块。模块(参见第72页上的图2.10)以自上而下的方式呈现。大多数模块都导出自己的接口。除了以sqlite3 开头的接口外,SOLite应用程序不得使用这些接
2.7.1 SQLite APIs
许多面向 SQLite 库的公共 API都在 main.c、legacy.c和 vdbeapi.c源文件中实现-些 API在其他源文件中实现,这些文件可以访问fle 范围内的本地定义的数据结构。例如,sqlite3 mprintf函数在 printf.c中实现,TCL接口在 tclsqlite.c中实现。有关 SOLite AP|的更多信息,请参见 SOLite 网页 http://www.sqlite.org/capi3ref.html。所有 SQLite API函数名称都以sqlite3 开头,API常量名称以SQLITE 开头。
6版本字符串的格式为“X.Y.Z
版本字符串的格式是” X.Y,。Z<尾随字符串>“,其中X为主要版本号,Y为次要版本号,2为发行号,尾随字符串通常为” alpha “或” beta";exampl“3.3.0beta”。在非常特殊的情况下,版本字符串可以是四种顺序,例如3.6.23.1。
2.7.2 Tokenizer
当应用程序将SOL语句或SQLite命令字符串发送到SQLite接口进行编译或执行时,会将该字符串传递给令牌器。令牌器将原始输入字符串分解为单个令牌,并将这些令牌逐个提供给解析器。记号赋予器代码在记号赋予器.c源文件中定义。 注:在SQLite中,词法分析器调用解析器。熟悉YACC和/或BISON的人习惯于相反的方式,即解析器调用词法分析器。SQLite的架构师和主要开发者理查德·希普(Richard Hipp)尝试了两种方式,发现词法分析器调用解析器效果更好。
2.7.3 解析器
解析器根据使用上下文为令牌生成者生成的令牌赋予意义。SQLite解析器是使用Lemon LALR(1)解析器生成器生成的。Lemon所做的工作与更熟悉的YACC/BISON所做的工作相同。它生成的解析器具有伸缩性、线程安全和防止内存泄漏。驱动Lemon的源文件可以在parse.y中找到。此文件定义 SOLite 实现的 SOL语法它还定义了 SOLite 特定的命令。Lemon生成parse.c和parse.h文件。parse.h包含所有令牌类型的数值代码,而parse.c实现SOLite分析器。 注意: lemon解析器生成程序通常不会在开发机器上找到。柠檬的完整源代码(仅个C文件,lemon.c)包含在工具子目录中。关于柠的文档在doc子目录中。
2.7.4 代码生成器
解析器从记号赋予器接收并组装SQL语句的所有记号后,它调用代码生成器生成字节码程序,当虚拟机执行该字节码程序时,将生成SOL语句所请求的结果。代码生成工作涉及许多文件:attach.c、auth.c、build.c、delete.c、expr.c、insert.c、pragma.c、select.c、trigger.c、update.c、vacuum.c和where.c。这些文件是大多数SQLite算法和逻辑所在的文件。expr.c文件处理表达式的代码生成,以及SELECT、UPDATE和DELETE语句中的WHERE子句的where.c代码生成。文件attach.c、delete.c、insert.c、select.c、trigger.c、update.c和vacuum.c处理具有相同名称的 SQL/SQLite 语句的代码生成。(这些文件中的每一个都在必要时调用 expr.c和 where.c中的例程。)所有其他 SQL语句都从 build.c中编码出来auth.c文件实现 sqlite3_set_authorizer Pl函数的功能。
2.7.5虚拟机
由代码生成器生成的字节码程序由虚拟机(VM)执行。字节码程序很像机一个线性的字节码指令序列。每个字节码指令包含一个操作器语言程序一码和最多五个操作数。VM一次读取、解码和执行字节码指令,从而实现一个专门设计用于操作数据库和处理事务的抽象计算机器。
虚拟机本身完全包含在 vdbe.c源文件中。(Vdbe 代表虚拟数据库引擎在本书中,VM和 VDBE是同义词。)VM也有自己的头文件:vdbe.h定义了 VM 和 SOLite 库其余部分之间的接口,而 vdbelnt.h 定义了 VM 私有的各种数据结构。vdbeaux.c文件包含 VM 使用的辅助函数,以及库其余部分使用的接口模块,用于构建字节码程序。vdbeapi.c文件包含对VM的外部接口,如 sqlite3 bind*家族API函数。单个值(字符串、整数、浮点数和BLOB)存储在名为“Mem”的内部对象中,该对象在vdbemem.c中实现。
SOLite 使用回调函数实现 SOL函数,甚至内置的 SOL函数也是这种方式实现的。大多数内置 SQL函数(例如 coalesce、count、substr等)可以在 func.c文件中找到。日期和时间转换函数可以在 date.c文件中找到。
内存分配和不区分大小写的字符串比较例程可在util.c文件中找到。哈希函数在hash.c中定义。c源文件包含UTF8和UTF16文本之间的Unicode转换子例程。SQLite在printf.c源文件中有自己的printf函数私有实现(带有一些扩展),在random.c文件中有自己的随机数生成器。
2.7.6 The tree
在btree.c源文件中定义了处理分别为B-树和B+-树的所有索引和表的代码。为每个表单维护一个单独的B+树,为每个索引维护一个B树。到树模块的接口在btree.h源文件中声明。
2.7.7 The Pager
树模块以固定大小的块(称为数据库页面或简单地说为页面)从数据库文件中请求信息。页面管理器负责读取、写入和缓存数据库页面。它还提供回滚和原子提交并协调事务并发性.树模块向寻呼器请求特定页面,并在希望修改这些页面或提交/回滚更改时通知寻呼器。寻呼器处理所有必要的细节,以确保请求得到快速、安全和效的处理。它充当典型DBMS的数据管理器、事务管理器、日志管理器和锁管理器。实现分页器的代码在pager.c源文件中定义。分页模块的接口是在pager.h源文件中声明的。
2.7.8操作系统界面
为了在POSIX、Windows和其他操作环境之间提供可移植性,SOLite使用一个抽象的接口层来与各种操作系统交互。它是一层很薄的膜。操作系统象层的接口是在os.h源文件中声明的;它被称为VFSadapter。SQLite通过适配器从平台获取服务。每个受支持的操作系统都有自己的实现:osunix.c用于Unix(以及Linux和MACOSX),oswin.c用于Windows(Win32和WinCE),os操作系统2.c用于OS/2。对于Unix,osunix.c文件包含锁定代码。构建过程会在库编译过程中获取适当的代码。
SOLite使用的Linux原语: SOLite使用本地操作系统和文件系统的一小部分原语来获得它们的服务。这个子集包括open、read、write、close、fcntl、fsync、fdatasync、malloc、free、unlink、access和一些pthread APl。 可以从Linuxmanpages中获取有关这些原语的信息。SOLite还使用Linux标准的临时文件目录来创建临时文件。这些临时文件的名称以etilgs 开头,后面跟着16个随机的字母数字字符,没有任何文件扩展名。 在本书中我没有谈到操作系统界面,你可能会认为这个层提供了诸如打开、读取、写入、同步、锁定、关闭、删除等功能,这些功能可以应用在文件上。
2.8 Sqlite 构建过程
构建过程如图2.11所示。构建过程包括以下六个连续的步骤:(1)构建sqlite3.h接口文件,(2)构建SOL解析器,(3)构建VM指令码,(4)构建指令码名称,(5)构建 SOL关键字,(6)构建库。
在构建过程中,生成六个C文件,用于构建最终库。两个中间C程序(lemon.c和mkkeywordhash.c)被编译以在构建机器上运行,以生成三个C文件:keywordhash.h、parse.h和parse.c。keywordhash.h文件中包含一个SOL/SOLite关键字的静态哈希表。柠檬程序生成解析器代码。Linux实用程序 awk和sed用于生成其他三个C文件:sqlite3.h、opcodes.h和opcodes.c。sqlite3.h文件包含SOLiteAPI函数和常量声明。(SOLite应用程序只需要这个文件和SOLite库。)opcodes.c文件包含用于字节码编程的opcode的文本名称。awk脚本扫描vdbe.c源文件以创建opcodes.h文件,该文件为操作符分配数值
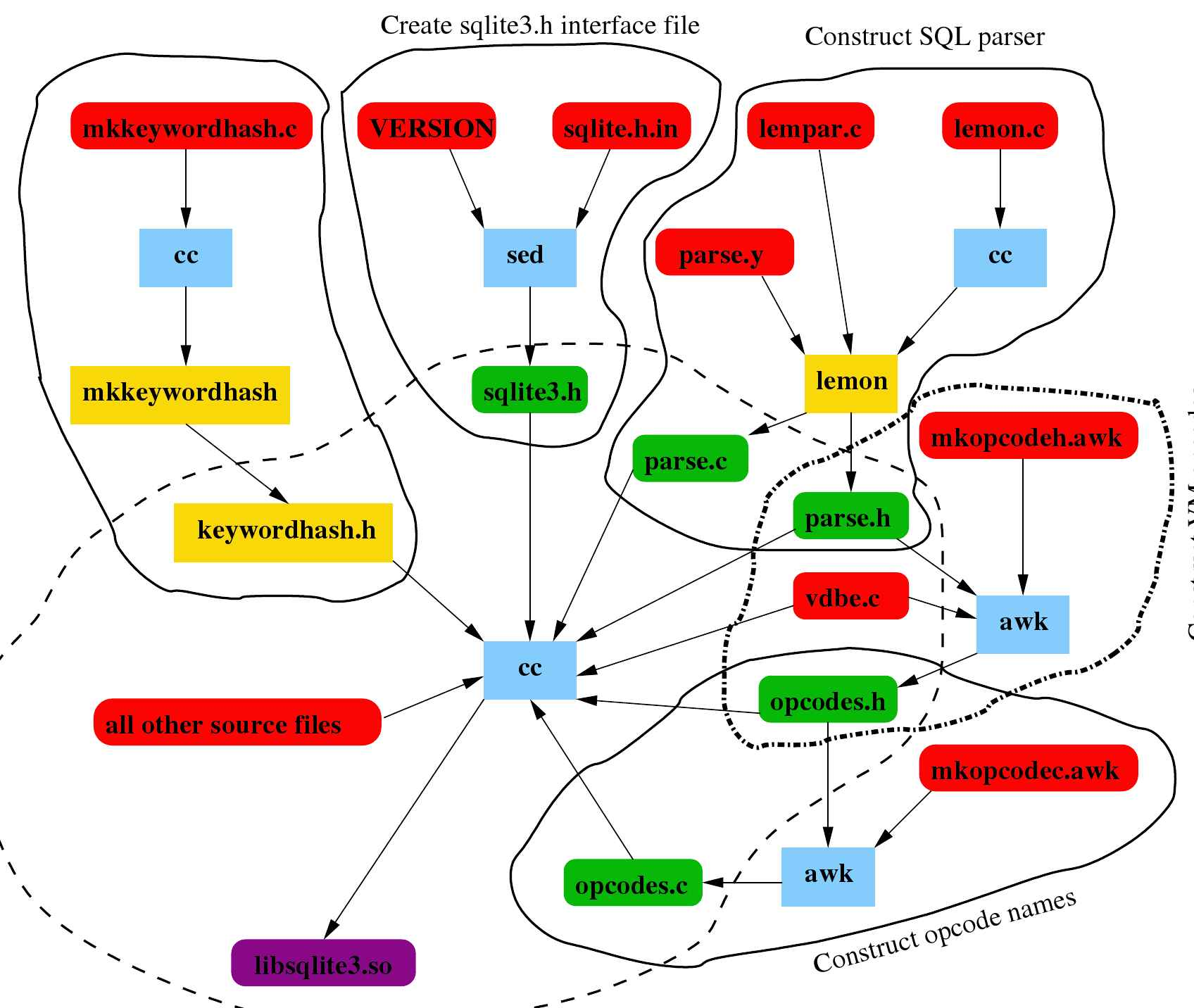 您可以从其主页下载 SQLite 源代码[22]并尝试构建过程。在配置下载的源代码时,将在根sqlite目录中生成一个Makefile。maketarget source命令执行所有源代码生成和预处理,并将最终编译的C文件放入新创建的tsrc子目录中。make命令除了构建库之外,还执行所有操作。要构建库,您需要编译tsrc子目录
您可以从其主页下载 SQLite 源代码[22]并尝试构建过程。在配置下载的源代码时,将在根sqlite目录中生成一个Makefile。maketarget source命令执行所有源代码生成和预处理,并将最终编译的C文件放入新创建的tsrc子目录中。make命令除了构建库之外,还执行所有操作。要构建库,您需要编译tsrc子目录
最近,SQLite开发团队提供了一个熟的合并文件(sqlite3.c)和相应的sqlite3.h文件,您可以使用它来构建库。(在最开始sqlite3.c文件还包含sqlite3.h文件的副本。)合并文件具有各种SQLite编译时间选项的默认设置值。已经发现,由合并文件生成的库效率提高了5-10%,因为C编译器可以进行更多的代码优化。您还可以将sqlite3.c文件与其他.c文件一起编译,使sqlite成为应用程序的一部分。SOLite开发团队强烈建议使用合并文件。如果希望使用命令行实用程序sqlite3,还需要shell.c源文件。(更多细节请参见 http://www.sqlite.org/howtocompile.html页面。)
SQLite允许自定义构建,其中某些SQLite功能可以使用各种编译标志关闭。我在第252页的10.18节中讨论了这些标志。
总结
SOLite是一个基干SOL-92规范的嵌入式关系数据库管理系统,用于用C语言编写的数据库应用程序;整个SQLite代码库是用ANSI开发的C.SOLite 的第一个版本于 2000年5月29 日发布。自那时以来,它已经取得了长足的发展。它在数据库应用程序中易于使用。它具有零配置、定制、嵌入式、线程安全、易于维护、面向事务等值得称赞的特性。
本章介绍了一些简单的单线程和多线程SOLite应用程序,展示了如何使用一些常用的SOLiteAPl函数,如sqlite3 open、sqlite3 close、sqlite3_prepare、sqlite3 step、sqlite3 finalize、sqlite3 exec、sqlite3 reset、sqlite3 bind *.sqlite3 column *等。这些应用程序展示了使用SQLite操作数据库是多么容易。
本章概述了 SQLite 处理事务的方式。每个 SQL语句都在事务中执行。当应用程序不通过执行 begin 命令手动打开事务时,SOLite会自动创建事务。在前一种情况下,我们说系统处于自动提交模式,SOLite在SOL语句执行结束时关闭(提交或回滚)事务。在后一种情况下,应用程序必须通过行commit或 rollback命令手动关闭事务。在那之前,所有SOL语句的执行都成为事务的一部分。SQLite确保事务的执行是可序列化的,为了实现ACID属性,它使用数据库级别的锁定方案和基于日志的故障恢复方案。
每个SOLite数据库都存储在单个本地文件中。该文件至少有一个目录(也称为系统表),即sqlite master;对于临时数据库,它被称为sqlitetemp master。当数据库本身初始化时,主表被创建和初始化。该表包含每个表、视图、索引和触发器定义(除主表外)的一行。该表有五个列:类型名称、表名、根页和sql。行被添加和从table 中,因为用户会分别创建和删除 database 对象。表是整个数据库的锚点。 SOLite 根据需要使用其他可选目录,例如sqlite sequence。
SQLite DBMS具有非常简单的模块化软件架构。有两个部分:前端解析系统和后端引擎。前端由三个模块组成:记号赋予器、解析器和代码生成器。后端是虚拟机,它从树和寻呼模块获取存储支持。最低级别的模块是操作系统接口,使SQLite可移植到多个操作系统。前端部门将SQL语句编译为后端引擎执行的内部字节码程序。
SOLite是开源的,并且可以在公共领域使用。可以从http://www.sqlite.org/download.html网页下载源代码和二进制文件,并且可以用于任何目的,而无需担心任何许可问题。
本章对SQLite领域进行了非常简短的介绍。本章中介绍的所有概念以及新引入的概念将在后续章节中详细讨论。在下一章中,我将讨论数据库和志文件的存储结构。
第三章 储存组织
学术目标
阅读本章后,你应该能够解释/描述
- 单个SOLite数据库的组织
- 数据库和各种日志文件的格式
- SOLite上下文中页面的概念和各种页面的目的
- 如何使数据库独立于平台
章节概要
本章讨论了SOLite在最低级别上如何组织数据库和日志文件的内容。它定义了这些文件的格式。整个数据库文件被划分为固定大小的页面,用于存储B/B+-树页面、自由列表页面和其他页面。在默认的日志模式中,日志文件将数据库页面的前图像内容作为日志记录存储:但在WAL日志模式中,日志文件将存储数据库页面的后图像内容。本章讨论了这些文件的命名方式及其内部组织。
3.1 数据库命名约定
数据库被完整地存储在单个文件中,称为数据库文件。(数据库与文件是同义词.因为没有其他文件存储有关数据库的任何信息。)当应用程序通过调用sqlite3open API函数尝试连接到数据库时,它会将数据库文件的名称作为参数传递给该数。文件名可以是相对于当前工作目录的相对路径名或从系统文件树的根开始。任何被本地文件系统接受的常规文件名都是好的。然而,有两个显著的例外。
-
如果给定的文件名是C语言的NULL指针(即0)或空字符串(“”)或包含所有空格字符的字符串,则SQLite会创建并打开一个新的临时文件。(但是,SOLite会尽量将尽可能多的数据存储在内存中。)这种情况的不同实例将具有不同的临时文件。当通过附加命令打开空或空格字符串时也会发生这种情况。
-
如果给定的文件名是“:memory:,SOLite将创建一个内存数据库。这个数据库不使用任何文件。如果应用程序两次或多次打开“:memory:”数据库,那么在进程地址空间中将存在许多独立的内存数据库副本,而不是一个副本!通过附加命令打开“:memory:”数据库时也是如此。
在这两种特殊情况下(通过 sqlite3 open 显式打开或通过 attach 命令打开),数据库是临时的,即非持久的,当应用程序关闭数据库连接时,数据库会消失,即被SQLite 自动删除。
数据库文件名惯例: 建议选择以.db扩展名结尾的文件名。这样你就能知道➆饪蕥П谣些是数据库文件。
URI文件名: 从SOLite 3.7.7开始,SQLite 支持 URI(统一资源标识符)文件名URI以文件:前缀开始。URI可以包含 vfs、模式、缓存等查询字符串参数-值对。要启用此功能,必须使用 SQLITE_USE.URI编译时标志编译 SQLite 库。有关此功能的更多信息,请参见 http://www.sqlite.org/uri.html。
临时文件的使用: 除了上述项目(1)中提到的临时文件使用外,SQLite还将其用于其他许多目的,如回滚日志、语句日志、多数据库主日志、临时索引、真空命令使用的临时数据库、视图的物化以及子查询。
临时数据库文件名: SQLite 随机选择所有临时文件名。文件名以 etilgs为前缀,后跟 16 个随机字母数字字符,没有文件扩展名。您可以使用 SOLITE TEMPFILE_PREFIX 编译宏将前缀更改为不同的单词。文件存储在标准的本地临时文件目录中。SOLite按以下顺序尝试目录(1)/var/tmp、(2)/usr/tmp和(3)/tmp。但是,您可以通过设置TMPDIR环境变量来使用不同的临时目录。当应用程序关闭临时文件时,它们会自动被删除。但是,如果应用程序或系统在关闭它们之前崩溃,这些文件会保留。
在上述任何一种打开数据库的方式(持久文件、临时数据库或内存数据库)中,由SQLite创建和/或打开的数据库在内部命名为主要数据库。SOLite为应用程序通过sqlite3 open API函数打开的每个库连接维护一个独立的临时数据库;数据库名为临时数据库。参见图3.1,其中应用程序通过两个不同的库连接两次打开同一个主数据库;每个打开实例都有自己的(不同的)临时文件。临时数据库存储临时对象,如表及其索引。(应用程序可以在查询中使用这两个名称,即主和临时。)例如,selectfrom temp.tablel返回 temp 数据库中 tablel 表中的所有行,而不是主数据库中的行。temp数据库的目录名为sqlite temp master。临时对象仅在同一库连接中可见(在其他库连接中不可见,即使它们在同一线程、进程或其他进程中打开相同的主数据库文件)。如图所示,SQLite将temp数据库存储在单独的一个临时文件中,该文件与主数据库文件不同。当应用程序在库连接上执行第一个create temporarytabletablel…语句时,实际上会创建该文件。当应用程序关闭库连接时,SOLite会删除临时文件。主数据库和临时数据库的结构是相同的。除了通过SQLite之外,用户不得自行篡改这些临时文件(无论是修改、删除还是重命名),否则数据库可能会损坏。
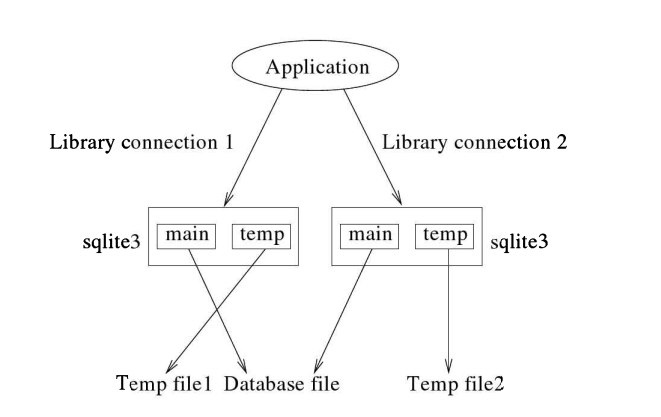
您可能会注意到,在内部,数据库文件名不是数据库名称。它们是SQLite中的两个不同但相关的概念。通过使用SOLite附加命令,可以将任何数据库文件与库连接关联为不同的数据库名称(除了主、临时和已在库连接中使用的那些之外)。您可以通过这些数据库名称对附加的数据库文件执行操作。例如,SOLite命令attach/home/sibsankar/MyDBasDB1使MyDB数据库文件对库库连接可用;附加的数据库在内部命名为DB1。从DB1.table1中选择*返回 DB1数据库中 tablel表的所有行,即 MyDB表没有固有的附加临时参数。附件的数据库文件。可以通过执行detach命令(例如detachDB1)从库连接中释放数据库(主数据库和临时数据库除外)。
连接混淆: 即使 sqlite3 open API函数接受数据库文件名,它也会打开一个库连接。这个库连接将与主数据库和临时数据库建立连接。在后文中,这些数据库连接被称为数据库连接。主数据库连接是到给定文件的连接。attach命令将新的数据库连接添加到库连接中,而 detach 命令可以将前者从后者中移除。当没有附加的数据库时,库连接和主数据库连接是同义词。
3.2数据库文件结构
除了内存数据库,SQLite将整个(持久或临时)数据库存储在单个数据库文件中。在其生命周期中,数据库文件会增长和缩小。(只要本地操作系统1文件系统允许文件增长,数据库文件就可以增长。)本地文件系统将数据库文件视为普通文件。它不解释文件的内容;它将文件视为简单的字节串。它实现读写原语,以从任何偏移位置读取/写入文件中的任意字节数。它还支持对 fles 进行同步(又名 flush)操作。在本节的其余部分,我将讨论如何将数据库文件构建为(逻辑)页面,以及这些页面是如何组织的。
3.2.1页面抽象
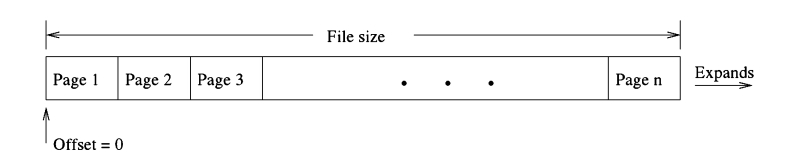
为了便于空间管理和从数据库文件中读写数据,SQLite将每个数据库文件(包括内存中的数据库)划分为固定大小的区域,称为数据库页或简单地说为页。因此,数据库文件的大小总是页的倍数。页按1开始线性编号。第一页称为页1,第二页为页2,以此类推。页面0被视为空页或“非页面”-页面在物理上不存在。从页1开始,页面一个接一个地线性存储到数据库文件中,从文件偏移量0开始,如图所示。3.2.您可以将数据库文件视为固定大小页面的可变大小数组,页面编号用作数组中的索引以访问页面。(实际上,页面模块在原生文件系统之上创建了这种抽象。)
3.2.2页面大小
默认页大小为1024字节,但它是一个编译时可自定义的参数。当从源代码编译SQLite库时,可以更改该值。页面大小必须为2,范围从512(=29)到65,536(=216),均包括在内。后一个约束是由于在代码和外部存储的不同地方需要将页面大小存储在2字节无符号整数变量中而施加的限制。一个数据库文件最多可以有2,147,483,647页(=231-1);这个数字在pager.c源文件的PAGER MAXPGNO宏中被硬编码。因此,一个数据库的大小可以达到大约140太字节(≈216x231=247)字节,当然,也要受到原生文件系统所施加的限制。 更改页面大小: 一旦数据库文件被创建,SQLite使用编译时的默认页面大小,但您可以通过在创建数据库中的第一个表之前使用page size pragma命令来更改大小。SQLite将大小值存储为文件元数据的一部分(参见第3.2.4节)。它将使用此页面大小值而不是默认值。即使您稍后使用不同的SOLite库,该库针对不同的默认页面大小进行了定制,数据库也将完美运行。
3.2.3页面类型
SOLite 会跟踪分配给数据库文件的页面,无论这些页面当前是否正在使用中。它会将跟踪信息保存在文件本身中。它计算所有页面,没有悬空的页面需要垃圾回收。(SOLite 中没有垃圾回收方案。)根据使用情况,页面被分为四种类型:空闲、树、指针映射(用于自动真空和增量真空功能,见第10.8节,第235 页)和锁字节(见第4.2.6节,第105页)。树页被细分为叶子页、内部页和溢出页。空闲页是未使用的(即当前未使用的)页;其他是活动页,它们属于B-或B+树,除了指针映射和锁字节页。B+树内部页包含用于搜索树的导航信息。(B-树内部页既包含搜索信息又包含数据)。叶子页在B+树中存储实际数据(例如,表行)。如果一行的数据太大而无法容纳在单个页中,则部分数据存储在树页中,其余部分存储在一个或多个溢出页中。
3.2.4数据库元数据
SQLite可以为任何页面类型使用任何数据库页面。第1页是惟一的例外,它总是一个B+树内部页面,存储sqlite master或sqlite temp master的根结点。该页还包含一个100字节的文件头记录,该记录从文件偏移量0开始存储。见图。3.3.
SQLite开发团队在2000年运行了许多基准测试应用程序后,通过试错方法决定了默认值。

文件头信息描述了数据库文件的结构。它定义了各种数据库设置参数的各种值,即元数据。SOLite在创建文件时初始化头信息。它使用第1页(包括文件头和B+-树)作为稳定的锚点,以跟踪文件中的其他页面。文件头格式如图3.4所示。图中的前两列是字节。

下面是对每个元数据元素(又称数据库设置参数)的描述
-
标题字符串:这是16字节的字符串:“SOLite格式3”,以UTF-8格式表示。在编译时,您可以通过定义SOLITE FILE HEADER编译宏来选择不同的16字节字符串,包括空终止符。)
-
页面大小:这是此数据库中每个页面的大小。值必须在512和32.768(包括两者)之间的2的幂次,或1表示65.536。如上所述,SOLite在操作文件时使用此页面大小。(相同的SOLite库可以同时处理具有不同页面大小的数据库文件。
-
文件格式:偏移量18和19处的两个字节用于指示文件格式版本。在当前版本的SQLite中,它们都必须是1或2,否则会出现错误,无法访问数据库。值1用于遗留的回滚日志记录(在SOLite 3.7.0发布之前),值2用于SOLite 3.7.0中弓入的WAL日志记录。如果读取或写入的值大于2,则分别无法读取或写入数据库。如果将来文件格式再次更改,这些数字将增加到指示新的文件格式版本号。
-
保留空间:SOLite 可以在每个页面的未尾保留少量固定空间(<=255 字节)以用于其自身目的,并且该值存储在偏移量20处;默认值为 0。当数据库使用SQLite 的内置(专有)加密技术时,它是非零的。每个页面末尾的额外字节存储该页面的加密算法使用的 nonce。页面的第一部分(页面大小减去保留大小)是存储数据库内容的可用空间。此空间必须至少为 480 字节。
-
嵌入式载荷:最大嵌入式载荷部分值(在偏移量21处)是标准B/B+-树内部节点的单个条目(称为单元格或记录)可以消耗的页面总可用空间量。值为255表示100%。该值必须为64(即25%):该值用于限制最大单元格大小,以便至少四个单元格适合一个节点。如果单元格的载荷大于最大值,则部分载荷溢出到溢出页中。一旦SQLite分配了一个溢出页,它会将尽可能多的字节移动到溢出页中,而不会让单元格大小下降到最小嵌入式载荷部分值(在偏移22处)以下。值必须为32,即12.5%。 min leaf payload fraction值(在偏移量23处)与min embedded payloadfraction类似,但仅适用干B+-树叶子页。该值必须为32,即12.5%。叶子节点的最大payload fraction值始终为100%(或255),因此在头文件中未指定。(B树中没有特殊用途的叶子节点。) 这三个领域的最初目的最近没有得到支持。
-
文件更改计数器:文件更改计数器(在偏移量24处)被事务使用。计数器初始化为0。每个成功写入数据库的写事务都会递增计数器的值。该值用于指示数据库何时已更改,以便页面可以清除其页面缓存。(当文件格式指示使用WAL日志时,此计数器不适用。)
-
数据库大小:数据库当前保存的页数以偏移量28存储。
-
自由列表:未使用页面的自由列表源自偏移量为32的文件头。空闲页面的总数存储在偏移量为36处。有关自由列表组织的更多信息,请参见下一节。
-
数据库模式Cookie:在偏移量40处存储一个4字节的整数,初始值为0。每当数据库模式更改时,其值会增加1,并用于预处理语句的自身有效性测试。
-
其他元变量:在偏移量44处,有14个4字节的整数值,这些值被保留用于树和VM模块。它们代表许多元变量的值,包括偏移量44处的模式格式编号、48处的(建议的)页面缓存大小、52处的自动真空相关信息(0表示没有自动真空,否则为数据库中最近根页面的页号)、56处的文本编码(值1表示UTF-8,2表示UTF-16LE,3表示UTF-16 BE)、60处的用户版本号(SOLite不使用,但用户使用)、64处的增量真空模式(0表示没有真空,其他值表示真空)以及偏移量92和96处的版本号;3其余字节被保留用于未来使用,必须清零。您可以在SQLite源文件(特别是btree.c)中找到有关这些变量的更多信息。
增量真空 vs.自动真空: 如果文件偏移量 52的4字节整数是 0,那么偏移量 60 的4 字节值必须为 0;数据库文件将不会执行自动真空。但是,用户可以通过执行真空命令来执行手动真空。如果文件偏移量 52 处的4字节整数不为零且偏移量 60处的4字节值为零,则自动真空正在运行;否则,自动真空关闭,增量真空正在运行。
跨平台使用: SQLite将所有多字节整数值存储在big-endian(最显著的字节在前)顺序中。这使得您可以将数据库文件安全地从一个平台移动到另一个平台。例如,您可以在x-86机器上创建一个数据库,并在ARM平台上使用相同的数据库(通过进行盲复制)而无需任何更改。数据库在新的平台上按预期工作。
向后兼容性: 数据库文件格式向后兼容到版本3.0.0。这意味着任何后续版本的 SOLite 都可以读取和写入最初由版本 3.0.0创建的数据库文件。这在其他方向上也基本成立–版本 3.0.0的 SOLite 通常可以读取和写入由该库华后续版本创建的任何 SOLite 数据库。然而,后续版本的 SOLite引入了一版本 3.0.0不理解的新功能,如果数据库包含这些可选的新功能,则较旧版本的库将无法读取和理解它。
不同的SQLite主版本可能使用不同的内部文件格式。此元信息用于检测数据库与库的不匹配,其值为1.2.3。或者43
最近修改数据库文件的SQLite库的版本号存储在olset 96。当这个值被改变时,从ofisset 24开始的瞬时改变计数器的值被保存在偏移量92处
如前所述,文件头之后是第1页上的B+树内部节点。该节点是主目录表的根节点,对于常规(即,主或附加)数据库,分别命名为sqlitemaster或sqlite tempmaster。如第67页第2.4节所述,该表存储同一数据库中所有其他树的根页编号。因此,第1页帮助SOLite跟踪其他树和溢出页。它是最珍贵的页面。
3.2.5自由名单的结构
未使用页的列表起源于偏移量为32的文件头。未使用页的总数量存储在偏移量为36处。未使用页列表以根树干的形式组织,如图3.5所示。未使用页分为两种子类型:树干页和叶子页。文件头指向链接的树干页列表中的第-个。每个树干页指向多个叶子页。,(叶子页的内容未指定,可以是垃圾o
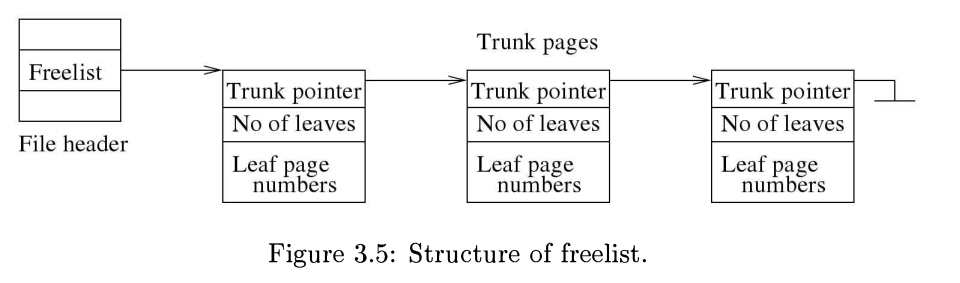
一个 trunk页的格式如下所示,从页的底部(也称为较低偏移量)开始:(1)下一个 trunk页的4字节页号(如果没有下一页则为 0);(2)一个4字节的整数值,表示存储在此页上的leaf指针的数量;(3)零个或多个4字节的leaf页页窍。 注意:由于3.6.0之前的版本存在一个错误,所以SOLite不会在主干页面上写 入最后6个条目。
当一个页面变得不活动时,SOLite将其添加到自由列表中,但不会将其释放到本地文件系统。当您在数据库中添加新信息时,SQLite从自由列表中取出空闲页面以存储信息。(因此,新信息可能存储在数据库文件中的任何位置。)如果自由列表为空,则SQLite从本地文件系统中获取新页面,并将它们附加到数据库文件的末尾。
在某些情况下,当自由页的数量变得过高时,你可能会感到担忧。你可以运行VACUUM命令来清除自由列表,缩小数据库文件,并将未使用的页面释放回文件系统。在“自动真空”模式下创建的数据库将在每个事务提交时自动缩小数据库。自由列表在事务之间保持空,尽管事务可以在提交之前建立自由列表。
自由列表清理:当您通过执行真空命令来清理自由列表时,该命令将数据库的副本复制到一个临时文件中。然后,它将在事务的保护下用临时副本覆盖原始数据库。
3.3期刊文件结构
SQLite使用三种日志文件,即回滚日志、语句日志和主日志。(这些被称为遗留日志。在SQLite3.7.0版本中,SQLite开发团队引入了WAL日志记录方案。数据库文件可以处于遗留日志记录独占或WAL日志记录模式。)它们的结构以及遗留日志记录的记录结构在下面的三个小节中介绍。我在第249页的第10.17节中讨论WAL日志记录。
3.3.1 回溯日记
对于每个数据库,SOLite 维护一个单一的回滚日志文件。(内存数据库不使用日志文件。它们使用主内存来存储日志信息。)回滚日志始终与原(主、临时或附加)数据库文件位于同一目录下。日志文件名与数据库文件名相同,后缀为-journal。您可能会注意到,在默认操作模式下,日志是临时的。SQLite为每个写事务创建日志文件,并在事务完成时删除该文件。
SQLite 将每个回滚日志文件分割成可变大小的日志段,如图3.6所示。每个日志段以段头记录开始,后面跟着一个或多个日志记录。这些将在接下来的两个子小节中讨论。

3.3.1.1分段头结构
段头文件的格式如图3.7所示。头文件以以下八个魔术字节的顺序开始(在较低的偏移量处):0xD9,0xD5,0x05,0xF9,0x20,0xA1,0x63,0xD7。序列将在后续中称为魔术数字。该数字被随机选择一次,仅用于sanitycheck,没有其他特殊意义。记录数(nRec,简称)组件指定此日志段中有多少个有效的日志记录。对于异步事务,nRec值最初为-1(作为带符号的值为0xFFFFFFFF),对于同步事务,nRec值为0。随机数组件的值用于计算单个日志记录的“校验和”。初始数据库页计数组件记录了当前日志记录开始时原始数据库文件中有多少页,扇区大小是数据库文件所在磁盘扇区的大小,段头占用整个磁盘扇区。也就是说,报头大小等于报头本身指定的扇区大小。页面大小是数据库页面的大小。标题中未使用的空间作为填充符保留在那里。所有的整数都以大端字节格式存储。

**扇区大小确定:**SOLite询问底层文件系统以获取扇区大小。(如果文件系统没有此信息则默认扇区大小为512字节。)SOLite假定文件系统不允许就地更改扇区中的单个字节。我们需要逐扇区地从文件系统写入或读取扇区。
回滚日志文件通常包含一个日志段。但是,在某些情况下,它是一个多段文件,SOLite会在文件中多次写入段头记录。(我将在第140页的5.4.13节中讨论此类场景。)每次写入段头记录时,它都会写入扇区边界。在多段日志文件中,任何段头中的nRec字段不能为-1(即0XFFFFFFFF)。
日志文件保留: 在默认操作模式下,SQLite会在事务提交/回滚时删除日志文件。但是,您可以通过使用pragmajournalmode命令来持久化日志(头被清零/无效或文件被截断)来改变这种行为。也就是说,日志式是DELETE、PERSIST或TRUNCATE;默认是DELETE。我将在本书后面介绍其他日志模式。如果应用程序使用排他锁定模式(pragmalockingmode-exclusive)。SOLite创建回滚日志该日志在应用程序移出排他锁定模式之前一直存在。在这种情况下,跨事务,日志文件被截断或其头被清零。
日志维护: 如果回滚日志在偏移量为0的位置包含有效的段头,则该日志有效。如果文件大小为0或包含无效的段头,则该日志不用于事务回滚。
异步事务: SOLite支持异步事务,其速度比同步(同步)事务更快,异步事务在任何时候都不会刷新日志文件或数据库文件。日志文件将只有一个日志段。nRec的值始终为-1,实际值由文件大小得出。SOLite不建议使用异步事务,但可以通过执行一个pragma命令来设置异步模式。这种模式通常在应用程序开发阶段使用,以减少开发时间。这种模式也适用于测试一些不需要测试从失败中恢复的应用程序。
3.3.1.2日志记录结构
当前写事务中的非SELECT语句会产生日志记录。SQLite在页面级别使用旧值日志技术。在首次更改任何页面之前,该页面的原始内容(连同其页面编号)被写入日志中的新日志记录。图3.8显示了单个日志记录的结构。该记录还包含32位校验和。校验和包括页面编号和页面图像。在日志段头中出现的32位随机值(参见图中的第三个组件)。3.7)作为校验码密钥。随机数很重要,因为出现在日志未尾的垃圾数据很可能是曾经存在于其他文件中但现在已被删除的数据。如果垃圾数据来自过时的日志文件,则检查总数可能是正确的。但是,通过将校验和初始化为对不同日志文件不同的随机值,SOLite可以最小化这种风险。

校验和位置: 您可能会注意到页码存储在日志记录的起始处,而校验和存储在未尾这种设置很重要。SQLite开发团队假定文件中的数据是以字节串线性写入的。因0此,如果由于电源故障导致日志损坏,最有可能的情况是记录的一端或另一端会损坏。日志记录的两端都正确而中间损坏的情况非常不可能发生。因此,尽管这种校验和方案快速且简单,但它能够捕捉到最有可能的损坏类型。
3.3.2 Statement journal
在用户的交易过程中,SQLite会为最新的INSERT、UPDATE或DELETESQL语句执行维护一个语句子日志,这些语句可能修改多行,并可能在触发器中导致约束违反或引发异常。子日志用于从语句执行失败中恢复数据库。语句日志是一个单独的、普通的回滚日志文件。它是一个任意命名的临时文件前缀为etilgs );它位于临时文件的本机目录中。崩溃恢复操作不需要日志文件;它仅用于语句中止。当语句执行完成时,SQLite会删除文件。日志中没有段头记录。nRec(日志记录数)值保存在内存数据结构中,数据库文件大小也保存在内存数据结构中,直到语句开始执行。这些日志记录没有任何校验和信息。
语句日志保留: 语句日志文件在语句执行结束时被删除。但是,为了实施SAVEPOINTS,SQLite 会保留语句日志,直到保存点被释放或用户事务提交。
3.3.3多数据库事务日志、主日志
你可能记得,应用程序可以通过执行ATTACH命令将附加数据库附加到已打开的库连接。在此场景中,SQLite允许用户事务读取和修改多个数据库。(参见第62页的图2.8。)如果事务修改多个数据库,则每个数据库都有自己的回滚日志。它们是独立回滚日志,彼此不知道。这样的事务在每个它更新的数据库中单独提交。因此,事务可能不是全局原子的。为了使(多数据库)事务具有全局原子性,SQLite还维护一个单独的聚合日志,称为主日志。4日志不包含任何用于回滚目的的日志记录,而是包含参与事务的所有个人回滚日志的UTF8格式名称。(在这种情况下,回滚日志称为子日志)子日志名称是全路径名称,由主日志文件中的空字符分隔。主日志总是与主数据库文件位于同一目录中,并且具有相同的名称,后缀为'-mi',接着是八个随机选择的4位十六进制数字。它是一个临时的文件;当事务尝试提交时创建,并在提交处理完成后删除。事务中断不会创建主日志文件。
每个子日志还包含主日志的(完整路径)名称,如图3.9所示。(如果没有附加数据库,或者如果没有附加数据库参与当前事务的更新,则不会创建主日志,子日志不包含任何有关主日志的信息。)如图所示,主日志记录是在事务提交时附加到子日志文件中的最后一个条目。该记录在磁盘扇区边界对齐。 校验和字段存储主日志名的校验和。长度字段指定主日志名的长度。主日志名总是以UTF8格式的文本存储,不包括终止的空字符。禁止的页号是包含锁定偏移字节的页的编号(见第4章):SQLite从不写入锁定字节页;它被保留用于解决Windows/POSIX不兼容问题。
4-如果主数据库是内存数据库,则不使用主日志。

总结
SQLite将所有(用户和元)信息存储在单个本地文件中,该文件名与数据库名同义。SOLite还支持临时和内存数据库。这些数据库在应用程序打开它们时创建和初始化,并在应用程序关闭它们时删除。
每个数据库文件都是固定大小的页的倍数。从逻辑上讲,数据库是一组页,并且该数组可以扩展和收缩。默认页面大小为1024,但可以设置为512和65,536之间的值,但值必须是2的幂。数据库文件可以有多达231-2页。有四种类型的页:空闲、树、锁定字节和指针映射。树页被细分为内部、叶和溢出。
第一页(从文件偏移量0开始)是锚点页。前100个字节存储数据库元数据,如头字符串、页面大小、文件格式等,页面上剩余的空间存储 sqlite 主目录或sqlite temp 主目录的根。所有空闲页面都组织在一个有根的树干树中。
SOLite使用三种类型的日志文件进行(默认)遗留日志记录方案:回滚日志语句日志和主日志。回滚日志和主日志与主数据库位于同一位置,但语句日志位于临时目录中,如/tmp。回滚日志存储可变大小的日志段,每个日志段以头信息开始,后面跟着一个或多个日志记录。日志记录由页号、页的旧映像和校验和组成主日志记录单个多数据库事务中涉及的所有回滚日志的名称。语句日志存储单次插入/更新/删除语句执行的日志。
第四章 Transaction Vanagement
学术目标 阅读本章后,你应该能够解释/描述
- SQLite如何实现ACID属性中
- 管理各种锁及其与本地文件锁和锁转换映射的SOLite方法
- SQLite如何避免死锁
- SOLite如何实现日志协议
- SOLite如何在用户事务中管理保存点
章节概要 数据库管理系统(DBMS)的主要职责是帮助用户执行对数据库的操作,以处理存储在数据库中的数据。此外,DBMS保护数据库免受多个并发用户的影响,并在发生应用程序、系统或电源故障时恢复数据库到可接受的连贯状态。为了这些目的,DBMS在事务的抽象中执行数据库操作。管理事务对于维护数据库一致性至关重要。DBMS实现ACID事务属性以确保数据库一致性SQLite 依赖于原生的锁机制和页面日志记录来实现 ACID 属性。你可能记得,SQLite 只支持平面事务;它没有嵌套能力。本章讨论了SQLite如何为可能更新单个或多个数据库的事务实现 ACID 属性。在下一章中,我将解释 SQLite 事务管理器 pager 的内部工作原理。
4.1交易类型
几乎所有的数据库管理系统都使用锁定机制进行并发控制,并使用日志来保存恢复信息。在事务修改数据库项之前,数据库管理系统会在日志中写入一些包含恢复信息(例如,项的旧值和新值)的日志记录。数据库管理系统确保在原始数据库中的项被更改之前,日志记录到达稳定存储。在事务取消或其他故障发生时,数据库管理系统在日志中拥有足够的信息,可以将数据库恢复到可接受的一致状态,该状态包含所有已提交事务的更新,并且不受其他(取消或失败的)事务的影响。在恢复数据库时,DBMS会撤销数据库中已放弃/失败事务的影响,并重做已提交事务对数据库的影响。在SQLite中,锁定和日志活动取决于我在此部分中讨论的事务类型。它们的管理将在以下两个部分中讨论。
4.1.1系统交易
SOLite 在事务中执行每个SOL语句。它同时支持读事务和写事务。(在SOLite 文档中,术语“事务”的使用有点抽象。事务可能仅指读事务或写事务。有时它不止于此:它包括写事务和一次或多次读事务。在本书中,每当需要时,我都会详细说明事务的类型。)应用程序只能在读事务或写事务中从数据库中读取任何数据,并且只能在写事务中写入任何数据。它们不需要明确告知SQLite在(适当的)事务中执行单个SQL语句。SOLite会自动执行此操作:这是默认行为,系统处于自动提交模式。这些事务称为系统或自动或隐含事务。对于SELECT语句,SOLite创建一个读取事务来执行该语句。对于非SELECT语句,SQLite首先创建一个读取事务,然后将其转换为写入事务。每个(读取或写入)事务都会在语句执行结束时自动提交(或取消)。应用程序不知道系统事务。它们没有处理系统事务的程序片段。它们将 SOL语句提交给 SOLite,在 ACID 属性方面由 SOLite 处理其余部分。应用程序从 SOLite 接收到 SOL语句执行的结果。
应用程序可以在同一数据库连接上启动(相同或不同的)SELECT语句(也称为读事务)的并发执行,但只能在该数据库连接上启动一个非SELECT(也称为写事务)。这意味着在数据库连接上不能有两个并发写事务,但可以并发一个写事务和多个读事务;它们通常被合起来想象为单个事务。如何在数据库上执行这些事务将在下一段中解释。
非选择性语句以原子方式执行;SOLite在启动非选择性语句处理时使用互斥锁,仅在语句执行完成后释放互斥锁。另一方面,选择性语句不是以原子方式从头到尾执行的;它在开始时使用互斥锁,但会为每一行结果暂停并释放互斥锁。因此,一个选择性语句的执行可以运行到其第一行,然后另一个选择性语句的执行可以运行,然后另一个,以此类推。因此,在任何时候,您可以在执行的不同阶段执行许多不同的选择语句。您也可以在暂停期间执行非选择语句。虽然读取和写入事务对于由此线程、进程或其他进程启动到同一数据库的其他连接的事务是不可分割的,但稍后我将向您解释,读取事务和写入事务不能同时操作同一表。因此,读取事务与并发写入事务是隔离的。
4.1.2用户交易
对于某些应用程序,特别是那些高写密集的应用程序,默认的自动提交模式可能代价高昂,因为SOLite需要为每个非选择语句执行重新打开、写入和关闭日志文件。此外,还有并发控制开销,因为应用程序需要为每个SQL语句执行重新获取和释放数据库文件上的锁。这种开销可能会导致显著的性能损失(特别是对于大型应用程序),并且只能通过围绕多个SQL语句打开用户级事务来减少。该应用程序包含在“BEGINTRANSACTION”和COMMIT【或ROLLBACK】TRANSACTION”命令中的SOL语句序列。(关键字TRANSACTION是可选的。)begin-commit或begin-rollback对可以包含任意数量的SELECT和非SELECT语句。
应用程序可以通过显式执行 BEGIN命令手动在库连接上启动新事务。该事务称为用户级或显式事务(或简单称为用户事务)。这实际上是在库连接上打开一个单独的用户事务。当完成此操作时,SOLite 会离开默认的自动提交模式;它不会在每个SOL语句执行结束时调用提交或取消。在库连接(任何数据库连接)上连续执行非选择SOL语句成为用户事务的一部分:但选择语句的执行被视为单独的读取事务。(你可以想象用户事务是唯一的写事务。)当应用程序在库连接上执行COMMIT(或ROLLBACK)命令时,SOLite会提交(或回滚)用户事务。如果用户事务提交,则写事务被提交,但是所有当前读事务都保持活动状态。如果用户事务被中止,写事务将被回滚,并且一些读取了由写事务更新的表的读事务也会被中止。在写事务完成时,SQLite会恢复到自动提交模式。(剩余的读事务在各自的SELECT语句执行结束时独立提交。)
注意: SQLite仅支持平面事务。它没有嵌套事务的能力。在用户事务中执行begin命令是错误的。应用程序不能在库连接上同时打开多个用户事务。
4.1.3保存点
SQLite支持用户事务的保存点功能。应用程序可以在用户事务内部或外部执行保存点命令。对于后者,SOLite首先打开一个用户事务,然后执行保存点命令,并在应用程序释放保存点时提交事务。保存点是事务执行中的个点,由应用程序建立。它建立了一个它认为良好的数据库状态。事务可以设置多个保存点。稍后,它可能会回滚到其中一个保存点,并重新建立保存点开始时的数据库状态。
4.1.4报表子交易
用户事务比简单事务稍复杂一些。所有连续的非选择语句执行都放在该事务中。如前所述,选择语句单独处理。)事务中的每个非选择语句都在单独的语句级子事务中执行。在任何时间点,用户事务中最多只能有一个子事务。SOLite实际上使用隐式(也称为匿名)保存点来在子事务的未尾执行它,并在释放保存点时释放子事务。这个过程会一直持续,直到应用程序执行COMMIT或ABORT命令。1如果当前语句执行失败,SQLite不会中止包含的用户事务,除非冲突解决程序指示回滚(见本节未尾)。相反,它将数据库恢复到语句执行开始前的状态(通过恢复匿名保存点);用户事务从那里继续。失败的语句不会改变其他先前执行的SQL语句或新语句的结果,除非主用户事务自行中止。让我们在这里研究一个创建用户事务的简单SOLite应用程序。
BEGIN TRANSACTION:
INSERT INTO table1 values(100);
INSERT INTO table2 values(20,100);
UPDATE table1 SET x=x+1 WHERE y> 10:
INSERT INTO table3 VALUES(1,2,3);
COMMI TRANSACTION;
假设数据库有三个表,即表1、表2和表3。应用程序通过执行begintransaction命令来打开用户事务。这四个语句中的每一个都在单独的子事务中执行,按上述顺序依次执行。例如,如果在UPDATE语句执行过程中发生约束违反错误,则更新执行之前修改的所有行将被恢复,但来自三个INSERT(在UPDATE周围)的更改将在应用程序执行提交事务命令时提交。
冲突解决: 在插入或更新过程中发生约束违反时,语句有五种方式来解决冲突。回滚:与当前语句子事务一起中止包含事务。中止:取消当前语句子事务的更改并止它;包含事务保持活动状态。这是默认的解决方式。失败:接受当前语句子事务已做的更改,但停止其进一步进展;包含事务保持活动状态。忽略:导致约束违反的特定行不会被更改或插入;子事务保持活动状态并继续进行。替换:导致约束违反的行被删除;子事务保持活动状态并进一步发展。
4.2锁管理
一个允许多个并发(冲突)事务的系统需要同步机制来隔离一个事务对其他事务的影响。文献中经常使用的与隔离相关的术语是并发控制、序列化和锁定。它们是不同的但密切相关的术语。Gray和Reuter[9]将术语关联如下:并发控制是待解决的问题,序列化是可处理问题属性的理论,而锁定是解决该问题的机制。通用术语是isolation,即ACID的“”。事务隔离有很多概念:已提交的读取、游标稳定、可重读取、可序列化。参见[9]对于这些术语的定义。序列化是最严格的隔离级别,SOLite实现了它。
为了产生可序列化的事务执行,SOLite使用锁定机制来管理事务对数据库的访问请求。它不使用并发进程之间的共享内存。因此,它不能在用户空间中协调事务并发。相反,使用本机操作系统(实际上是文件系统)支持的文件锁定原语来实现此目的。
SQLite通过严格限制事务并行的程度,简化了锁定逻辑的复杂性。它允许任意数量的读事务读取同一数据库,但最多允许一个写事务独占访问数据库。(你可能记得在同一数据库连接中,写事务和一次或多次读事务可以共存。)SQLite的锁定管理非常简单。目前,SQLite执行数据库级锁定,但不进行行级、页级或表级锁定:它对整个数据库文件设置锁定,而不是对文件中的特定数据项设置锁定。此外,为了生成可序列化的事务执行,它遵循严格的二阶段锁定协议,即在事务完成时释放锁定。在本节剩余部分中,我将讨论 SQLite 如何管理各种锁定以及在Linux 系统中的细微差别。注意:一个子事务通过容器用户事务获取锁定。无论子事务的结果如何,所有锁定都由用户事务持有,直到它提交或取消。
4.2.1锁类型及其兼容性
从单个事务的角度来看,数据库文件可以处于以下五种锁定状态之一。您可能会注意到这些是 SOLite锁,而不是原生操作系统支持的锁。(我将在第105 页的 4.2.6 节中讨论 SOLite 锁和原生锁之间的映射。)
- NOLOCK:事务对数据库文件没有锁定任何类型。它既不能读取也不能写入数据库文件。其他事务可以读取或写入数据库,只要它们的锁定状态允许。Nolock是事务在数据库文件上启动时的默认状态。
- 共享锁:此锁仅允许从数据库文件读取。任何数量的事务可以同时持有文件上的共享锁,因此可以有多个同时的读取事务。当有一个或多个事务持有文件上的共享锁时,不允许任何事务写入数据库文件。
- 独家:这是唯一允许写入(和读取)数据库文件的锁定。文件上只允许一个排他性锁定,并且不允许任何其他类型的锁定与排他性锁定共存。
- 保留锁:这种锁允许从数据库文件中读取。但是,它比共享锁稍微复杂-些。保留锁通知其他事务,锁持有者计划将来写入数据库文件,但现在只是读取文件。文件上最多可以有一个保留锁,但锁可以与任意数量的共享锁共存。其他事务可以获取文件上的新共享锁,但不能获取任何其他类型的锁。
- PENDING:此锁定允许从数据库文件中读取。一个待处理锁定意味着事务想要立即写入数据库。它是获取排他锁定过程中的中间锁定。事务正在等待当前所有共享锁的清除,然后才能获取排他锁。文件上最多只能有一个待处理锁定,但该锁定可以与任意数量的共享锁定共存,但有一个区别:其他事务可以保留其现有的共享锁定,但不能获取新的(共享或其他)锁定。(此锁类型是锁管理器内部的,客户端看不到。)
SQLite锁之间的兼容性矩阵如图4.1所示。行是事务持有的数据库上的现有锁模式,列是来自另一个事务的新请求。每个矩阵单元格标识两个锁之间的兼容性:Y表示新请求可以授予;N表示不能。
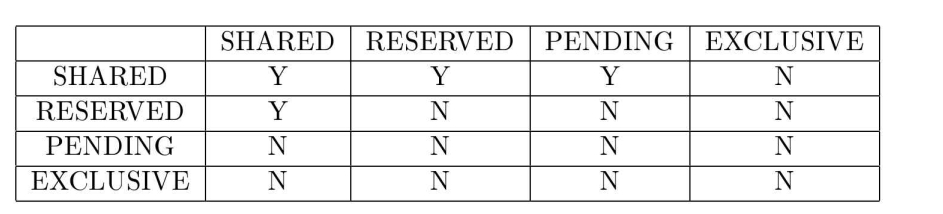
讨*论: 像SQLite这样的数据库系统至少需要排他锁;其他锁模式仅用于增加事务并发。仅使用排他锁时,系统将串行执行所有(读和写)事务。使用共享和排他锁时系统可以并发执行许多读事务。在实践中,事务在共享锁下从数据库文件中读取数据项,本地修改该数据项,然后请求排他锁将(修改后的)数据项写回文件。如果两个事务同时这样做,就有可能形成死锁(见第104页4.2.4节),在这种情况下,事务的执行无法取得进展。SOLite开发团队设计了保留和未决锁,以最大限度地减少这种死锁的形成。这两种锁还有助于提高并发性和减少众所周知的写者饥饿问题(读事务永远超过写事务)。这些锁与现有的共享锁兼容,但新的共享锁与未决锁不兼容。 Unix和Window实现提供了所有这五种锁定状态。
4.2.2锁获取协议
在从数据库文件读取或写入页面之前,事务(实际上是寻呼模块)获取对数据库文件的适当锁定,以确保两个事务不会以冲突的方式访问文件。当事务尝试访问文件时,获取适当类型的锁定是寻呼模块的责任。
事务以非锁定状态开始。在从数据库文件读取第一个(任何)页面之前,事务获取共享锁,以表示其他事务打算从该文件中读取页面。我们说它已成为一个读取事务,它可以读取数据库文件中的任何页面。在对数据库(任何页面)进行任何更改之前,事务获取保留锁,以表示它打算在不久的将来写入。我们说它已成为(半)写事务,但其效果对其他事务(在事务的数据库连接之外)是不可见的。(与共享锁的其他事务可以继续读取文件,但其他事务不能获得文件的新保留锁、挂起锁或独占锁。这意味着系统可以有任意数量的读取事务,但数据库文件上没有其他半写或全写事务。)在数据库文件上保留锁后,一个(半写)事务可以对“在缓存”页面进行更改。在将修改后的页面写回数据库之前,它需要获得数据库文件的独占锁。此时它将成为一个完整的写事务,一旦开始写入文件,其效果将可见于数据库文件中。
锁定状态转移图如图所示。4.2.(如前所述,待决锁是中间的内部锁,在锁管理器子系统之外不可见。)寻呼器不能要求锁管理器获取待决锁;锁管理器也不接受此类请求。悬而未决的锁总是通往专属锁的临时垫脚石。寻呼器总是请求专用锁,但锁管理器可以授予待定锁。待决锁定将通过后续的专属锁定请求升级为专属锁。
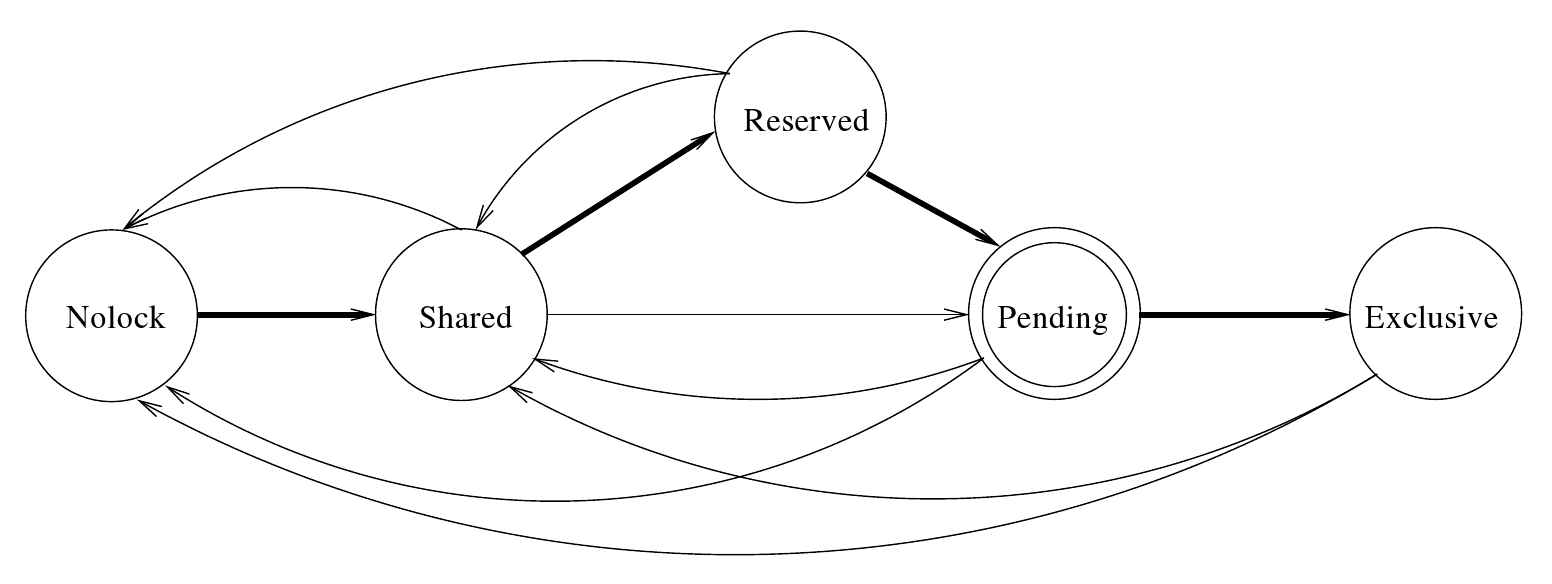
对于读事务,正常的锁转换是从无锁到共享锁,再回到无锁。对于写事务,正常的锁转换是从无琐到共享锁到保留锁到挂起锁到排他锁(如图4.2中的粗箭头所示),再回到无锁。只有在事务读取数据库时需要回滚日志的情况下,才会进行直接共享锁到挂起锁的转换。在这种情况下,没有其他事务可以从共享锁转换到保留锁(我将在第5.4.2.4节中重新讨论这个问题)。
锁管理器实现了两个函数,即sqlite30sLock和sqlite30sUnlock,分别用于获取和释放打开数据库文件上的 SOLite锁。在 os unix.c文件中为 Unix 系统定义这两个函数。sqlite30sLock函数由 pager 调用以获取数据库文件上的新锁或升级现有锁,而 sqlite30sUnlock函数用于释放或降级文件上的锁。因此,通过执行sqlite30sLock函数,pager可以获得共享、保留或排他锁,并通过执行sqlite30sUnlock 可以将锁重置为共享或 nolock。当一个打开的数据库连接被关闭时,寻呼器会释放为数据库连接获得的所有锁。我在第112页的4.2.7节中讨论了这两个函数。
4.2.3显式锁定
锁定在 SOLite 中是隐式的。系统(实际上是分页器模块)单独决定何时锁定数据库文件以及以何种模式锁定。应用程序可以通过执行两种变体的事务开始命令来显式地指示 SQLite 获取锁定。让我们研究一下以下稍微不同的 SQLite 应用程序,它打开了一个用户事务。
BEGIN EXCLUSIVE TRANSACTION;
INSERT INTO table1 values(100);
INSERT INTO table2 values(20,100);
UPDATE tablel $ET x=x+1 WHERE y> 10;
INSERT INTO table3 VALUES(1,2,3);
COMMI TRANSACTION:
通过执行begin exclusive transaction命令,应用程序迫使SOLite立即对所有数据库文件(主文件和附加文件)获取排他性锁,而无需等待数据库文件被使用。这确保了一旦begin exclusive transaction命令执行成功,事务将对数据库文件具有排他性锁,并且在事务的生命周期内不会被其他事务阻塞。在事务完成之前,该线程和任何其他兄弟线程(通过其他数据库连接)或同一进程中的其他线程将不能发起任何对数据库文件的读写操作。
除了独占事务,还有两种替代方案:(1)立即开始;(2)延迟开始。立即开始命令立即启动事务,对所有数据库文件(主文件和附加文件)进行保留锁定,而无需等待数据库文件被使用。成功执行立即开始命令后,可以保证没有其他兄弟线程或对等进程能够写入任何数据库文件或成功执行涉及其中一个数据库文件的立即开始或独占开始命令。然而,其他线程和进程可以继续从数据库中读取数据。begin deferred命令启动一个没有任何数据库文件锁的事务;锁的获取被延迟到文件被实际使用时:当文件被第一次读取时,在文件上获得共享锁,在下一次插入/更新/删除操作时,在文件上获得保留锁。当需要时,SQLite将其升级为排他锁(即,直到它实际写入数据库文件时)。因为锁的获取被推迟到需要时,另一个兄弟线程或对等进程可能会创建一个单独的事务,并在当前线程上引用的开始执行后写入数据库。当这个线程试图在事务中执行一些sql语句时,它可能会得到一个$QLITE BUSY错误代码。应用程序开发人员已经得到警告!如果应用程序执行begin transaction语句,默认的操作模式是‘deferred transaction’。您可能会注意到,延迟事务可能不会锁定所有数据库(主数据库和附加数据库);它会根据需要锁定选择性数据库。
非排他性开始事务命令允许存在至少可以读取数据库的其他事务。因此,尝试提交写事务可能会导致获得 SOLITE.BUSY错误代码。当以这种方式提交失败时,事务保持活动状态,可以在其他事务(即它们已清除共享锁)消失后稍后重试提交。
4.2.4僵局和饥饿
虽然锁定解决了并发控制问题,但它引入了另一个问题。假设两个事务对数据库文件持有共享锁,它们都请求文件上的保留锁。其中一个获得保留锁,另一个等待。一段时间后,持有保留锁的事务请求独占锁,并等待另一个事务清除共享锁。但是,由于持有共享锁的事务正在等待,因此共享锁永远不会被清除。这种情况称为死锁。
死锁是一个棘手的问题。处理死锁问题有两种方法:(1)预防,和(2)检测和中断。SQLite可以防止死锁的形成。它总是在非阻塞模式下获取文件锁–要么锁管理器授予请求的锁,要么返回错误代码而不阻塞请求者。如果代表事务无法获取某些锁,它只会重试有限次数(重试次数可以在运行时由应用程序预置,默认为零,即不重试)。如果所有重试都失败,SQLite将向应用程序返回SQLITE_BUSY错误代码。应用程序可以放弃并稍后重试,或者中止事务。因此,系统中不存在死锁形成的可能性。然而,至少在理论上,存在一种可能性,即事务永远试图获得一些锁而没有成功。
4.2.5 Linux锁原语
SQLite的锁定是通过原生文件锁定实现的。在这一小节中,我回顾了Linux系统支持的锁定机制。POSIX建议的锁定方案是SQLite的默认锁定机制。Linux只实现两种锁定模式,即读和写,用于锁定文件上的连续区域。为了避免术语混淆,我将使用读锁和写锁分别表示原生共享锁和独占锁。写锁排除了所有其他锁,包括读锁和写锁。虽然读锁和写锁可以同时存在于同一文件上,但位于不同的区域。-个进程只能在一个区域上持有一种类型的锁定。如果它对一个已经锁定的区域应用新的锁定,那么现有的锁定将被转换为新的锁定模式。(这种转换可能涉及拆分、缩小或与现有锁定合并,如果新锁定指定的字节范围与现有锁定的范围不完全一致。)
注意: 文件上的锁定不是文件或其他文件的内容。它们只是内核维护的内存数据对象。锁定在系统故障后不会存在。如果应用程序崩溃或退出,内核会清理应用程序持有的所有锁定。
4.2.6 SQLite锁的实现
SOLite通过使用本地操作系统支持的文件锁定函数来实现自己的锁定机制(锁定实现取决于平台。我在本书中使用Linux向您展示SOLite如何锁定现在您知道Linux仅支持两种锁定模式,而SOLite有四种。SQLite使用两种本地Linux锁定模式来实现自己的四种锁定模式,用于不同的文件区域它通过调用fcntl系统调用来设置和释放区域上的本地锁定。本节讨论SOLite锁定和本地锁定之间的映射。
- 通过在数据库文件的特定字节范围内设置读取锁,可以获得数据库文件的共享锁。[-2]
- 通过在指定范围内的所有字节设置写锁,可以获得排他锁。
- 预留锁是通过在文件的单个字节(位于共享字节范围之外)上设置写锁来获得的;它被指定为保留的锁字节。
- 一个PENDING锁是通过在一个指定的字节上设置一个写锁来获得的。保留的锁字节,在共享范围之外。
[-2] 某些版本的Windows只支持写锁。在这种情况下,要获得文件上的共享锁,需要对超出特定字节范围的单个字节进行写锁定。字节是从范围中随机选择的,以便多个读事务可以在那时访问文件,如果两个读事务选择相同的bvte来写锁,则只有一个成功。在这样的系统中,读并发性受到共享字节范围大小的限制。
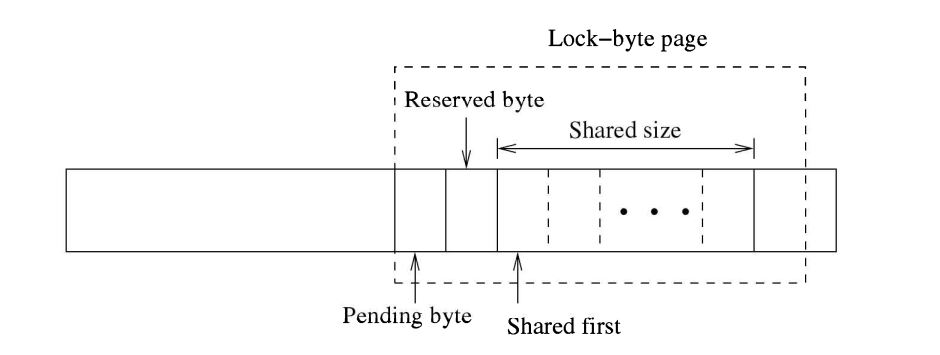
图4.3显示了这种安排。SOLite保留510字节作为共享字节范围,定义为SHARED SIZE宏的值。范围从SHAREDFIRST宏偏移量开始。PENDINGBYTE宏(=0x40000000,超过1GB边界的第一字节定义了锁字节的开始)是设置PENDING锁的默认字节。RESERVEDBYTE宏设置为PENDINGBYTE之后的下一个字节,SHARED FIRST设置为PENDING BYTE之后的第个字节。所有锁字节将适合单个数据库页面,即使最小页面大小为512字节(见第84页上的第3.2节)。这些宏是在os.h源文件中定义的。[-3]获取这些锁的前提条件和步骤如下所示。
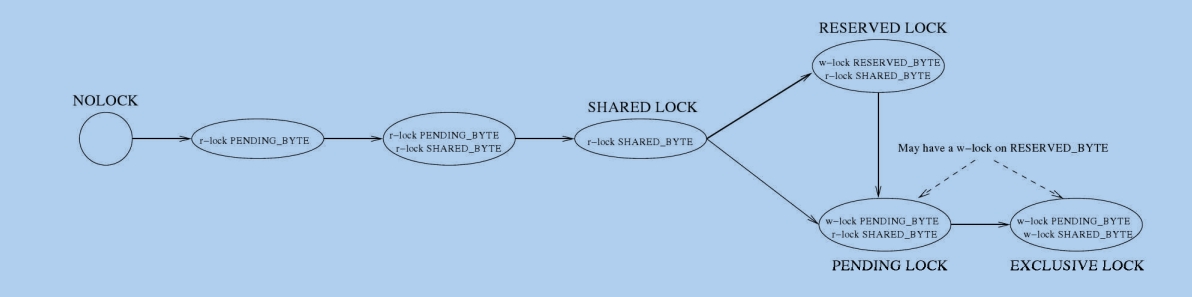
4.2.6.1从SQLite锁到本机文件锁的转换
本小节描述SQLite如何设置数据库文件的锁。
-
为了对数据库文件获取共享锁,一个进程首先在PENDING.BYTE上获取本地读锁,以确保没有其他进程对该文件持有PENDING锁。(您可能还记得第101页图4.1中的锁兼容性矩阵表,其中现有PENDING锁和新共锁是不兼容的。)如果此锁设置成功,则从SHARED FIRST字节开始的SHARED SIZE范围将被读锁,[-4]并最终释放PENDING BYTE上的读锁。
-
进程只有在获得了文件上的共享锁之后才能获得数据库文件上的保留锁。为了获得RESERVED锁,需要在RESERVED锁字节上获得写锁。您可能会注意到,进程不会释放文件上的共享锁。(这确保了另一个进程不能获得文件上的EXCLUSIVE锁。
-
一个进程只有在获得文件上的共享锁后,才能获取数据库文件的PENDING锁。要获取PENDING锁,需要在PENDING BYTE上获取写锁。(这确保了不能在文件上获取新的共享锁,但允许现有共享锁共存。)您可能会注意到,该进程没有释放其在文件上的共享锁。(这确保了另一个进程无法获取文件上的排他锁。
注意: 在获取PENDING锁的过程中,进程不需要获取RESERVED锁。这个属性被SQLite用于在失败后将日志文件回滚。如果进程从共享到保留再到PENDING的路径,那么在设置PENDING锁时不会释放其他两个锁。
-
一个进程只有在获得文件上的挂起锁后才能获得数据库文件的独占锁。要获得独占锁,需要在整个“共享字节范围”上获得写锁。由于所有其他SOLite锁都需要在这个范围内的字节(至少一个)上获得读锁,这确保了当进程获得独占锁时,文件上不存在其他SOLite锁。(使用单个字节而不是“共享字节范围”的原因是因为某些版本的Windows不支持读锁。通过写锁定一个范围中的随机字节,即使使用的本机锁定基元始终是写锁定,也可能存在并发共享锁定。
[-3] 锁定Windows是强制性的;也就是说,对所有进程都强制执行锁,即使它们不是协作进程。锁定空间是由Windows操作系统预留的。由于这个原因,SQLite不能在锁定字节中存储实际数据。因此,分页器永远不会分配涉及锁定的页面。该页面也在其他平台中使用,以实现数据库的一致性和跨平台使用。PENDING BY’E设置得很高,所以除了非常大的数据库之外,SQLite不需要分配未使用的页,在本书中它被称为锁字节页。
[-4]在某些Windows上,SHARED_SIZE范围内的随机字节被写锁定
为了清楚地了解SQLite获取数据库文件原生锁的方式,原生锁状态转换在图4.4中进行了绘制。在图中,r-lock表示原生读锁,w-lock表示原生写锁。该图还揭示了SOLite锁和原生锁之间的关系。PENDING锁和EXCLUSIVE锁的表示有些别扭;根据SQLite设置这些锁的路线,它们可能在RESERVED BYTE上具有写锁或不具有写锁。
4.2.6.2 原生锁的工程问题
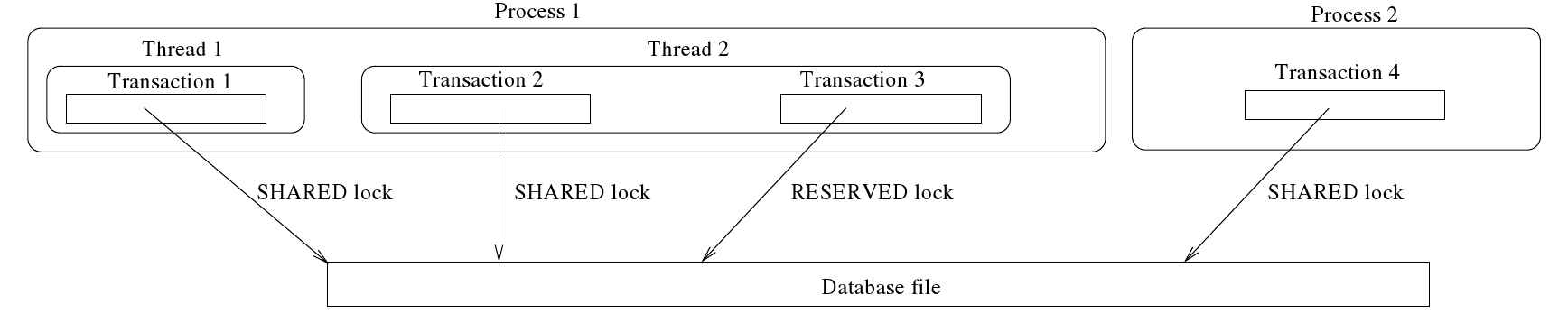
上述定义的锁定方案中存在两个工程问题。第一个问题是由于Linux锁功能的特殊性引起的。第二个问题是 SOLite 特有的问题。数据库文件的本地锁由进程持有,而 SOLite锁由线程在进程地址空间内运行的事务持有(见4.5)。在图中,进程1有两个线程:线程1有一个事务,线程2通过三个不同的库连接持有同一数据库文件的两个事务。进程2有一个事务。(你可能记得,通过图书馆连接,一个进程可以在数据库上执行一个写事务和多个读事务同时进行。)在四个并发事务中,三个有共享锁,一个对数据库文件有保留锁。你可能注意到,事务对本地操作系统是不可见的,操作系统只看到进程和线程。我们需要一个机制,将事务持有的 SOLite 锁映射到进程持有的本地锁。如果一个进程只打开一次数据库文件,那么该进程和事务是同义词,没有问题(如图4.5中的进程2所示)。当进程打开多个并发事务,这些事务可能通过不同的库连接访问同一数据库文件时,就会出现问题,如图中进程1所示。进程1对数据库文件的三次事务持有哪些本地锁,当一次事务完成时会发生什么?我将在接下来的两个子小节中讨论这两个问题。唯一的好消息是,一个图书馆连接最多只能有一个打开的写事务,并且事务只打开一次数据库文件。(我的意思是,一个进程为了执行事务,会为事务打开一次数据库文件;但是,进程可以为其他事务打开同一个数据库文件
o
4.2.6.3 Linux系统的问题
SQLite使用POSIX建议锁定方案,并通过fcntlAPI函数获取和释放文件锁定。如前所述,锁定是内存中的对象。我想在这里指出的第一点是,Linux系统将锁定与文件inode(表示实际文件)关联,而不是与文件名关联。在Linux系统中,两个或多个文件名可以通过符号链接和硬链接用于相同的inode,这可能会对通过不同文件名设置/释放锁产生一些奇怪的后果。第二件要注意的事情是,尽管锁是由fcntl函数通过打开文件描述符设置和释放的,但它们之间没有关系。如果一个进程(多次打开同一个文件)通过两个打开的文件描述符设置或清除同一个文件区域上的锁,第二个锁操作将不知不觉地覆盖第一个锁操作,因为两个描述符都指向同一个文件索引节点(这两个操作可以来自进程中相同或两个不同的兄弟线程)。
让我们通过一个例子来进一步澄清上述观点。假设文件1和文件2是两个实际上相同的文件(因为一个是另一个的硬链接或符号链接)。假设一个进程以以下方式打开这两个文件进行读写。
int fd1 = open("flel", ..);
int fd2 = open("fle2", ·.·);
假设线程T1首先通过fd1在文件区域上设置一个读锁,然后T1或另一个线程T2尝试通过fd2获取同一文件区域上的写锁。由于两个锁请求都来自同一进程,且位于同一inode上的同一区域,因此线程获得了写锁(覆盖了读锁),这意味着当一个进程两次(同时)打开同一数据库文件,以便在两个不同的事务中执行两个不同的操作时,两个打开的数据库连接上的活动可能会相互干扰,尽管这是无意的,因为一个进程最多只能在一个文件区域上拥有一个本地锁。这意味着我们不能盲目地使用本地锁来控制事务并发。也就是说,虽然我们可以使用本地锁在不同进程之间同步事务并发,但我们不能直接使用本地锁来同步在两个或多个不同库连接(在同一或不同线程中)打开同一数据库文件的进程对同一数据库文件的访问。
因此,为了解决上述问题,SOLite需要在内部跟踪应用程序进程的所有打开的数据库文件描述符,并在实际尝试获取或释放文件区域的本地读写锁之前,在内部管理锁。这在一个抽象层中实现。每当SOLite打开一个数据库文件(对于线程)时,它会找到数据库文件的特定inode(inode由fstat()原生API函数填充的stat结构中的st dev设备号和st inoinode号字段确定),并在内部检查该inode是否已被其所有者进程持有。如何做到这一点将在本分节的其余部分讨论。
当要在数据库文件的索引节点上获取锁时,SQLite查看进程的内部锁记录,以查看它之前是否在同一索引节点上设置了锁。对于每个打开的文件(inode), $QLite维护一条信息(unixInodeInfo类型的对象)来跟踪进程持有的inode上的锁(见图4.6,它描述了第108页图4.5中进程1的锁定状态)。unixInodeInfo对象封装了当前索引节点上的外部锁定状态。在图中,进程在两个线程中打开了三次给定的数据库文件。(将在下一小节中讨论微妙的多线程问题。)它们通过一个unixInodeInfo对象跟踪文件上的锁。一个unixInodeInfo对象表示数据库文件(即inode)上的一个SQLite锁实例。一个进程不能为同一个文件拥有两个或多个unixinodeinfo对象实例(如图4.6所示)。
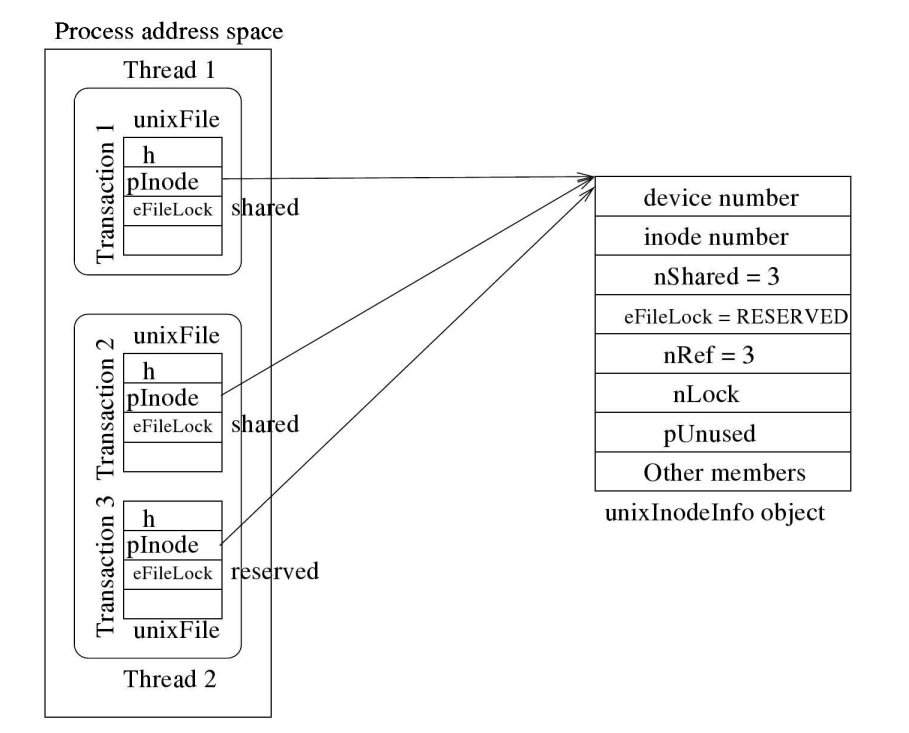
所有 unixInodelnfo 对象(适用于所有文件)都存储在一个双重链接的列表(全局inodeList)中。设备号和inode号组合使用作为搜索关键字来搜索列表。列表最初是空的。对象可按需创建和删除。列表由(全局)线程互斥器保护。
unixInodeInfo对象保存一个引用计数(nRef)来跟踪进程打开了多少次相同的文件,也就是说,有多少数据库连接正在共享这个对象。unixInodeInfo对象的eFileLock成员变量表示进程当前在数据库文件上持有的最高(最强)锁模式:NOLOCK。SHAREDRESERVED、未决或排斥。(进程发起的某些事务持有数据库文件上的这个issqlite锁。)nShared成员变量表示内部锁状态,如果nShared为0,表示文件未被进程锁定;如果nShared大于0,表示文件未被进程锁定。当一个线程试图锁定或解锁一个文件时,SQLite首先检查相应的unixInodeInfo对象。只有当两个SQLite锁模式之间的内部锁状态转换被指示时,才调用fcntl系统调用来设置或释放文件上的本机(读或写)锁。例如,如果进程持有文件上的RESERVED锁,而线程请求文件上的SHARED锁,那么fleSQLite将增加unixInodeInfo对象的nShared成员变量。但是,如果线程请求一个EXCLUSIVE锁,$QLite调用fcntl来获得文件上的写锁。
SOLite维护一个unixFile类型的对象来跟踪数据库文件的一个打开实例的锁定状态。如图4.6所示,每个打开的数据库都有一个unixFile对象。对象是数据库连接的同义词。独立于本机操作系统支持的打开文件描述符的文件打开。(不同的本地操作系统定义了不同的unixfile结构。)对数据库文件的所有操作都使用对象作为句柄来执行。组件为打开的文件存储操作系统创建的文件描述符。h值用作文件上的读写、关闭和设置/重置锁的引用。unixFile对象有一个指向unixInodeInfcob对象的指针,通过该指针获取数据库文件上的SQLite锁。unixFileobject的eFileLock字段表示通过该unixFileobject持有的数据库文件的当前SOLite锁模式,即。对于此连接到数据库文件。由于一个数据库文件连接最多可以有一个打开的(读或写)事务,因此对应的unixFile对象中的eFileLock表示该事务通过该连接在数据库文件上的SQLite锁类型。在同一个数据库上,线程1上的事务1持有一个共享锁,线程2上的事务2持有一个共享锁,线程2上的事务3持有一个保留锁
如果同-inode 被任何线程中的进程打开两次或更多次,那么就会有多个 unixFile 对象,并且所有这些对象都共享同一个 unixInodelnfo 对象。这种情况在图 4.6 中显示为 Thread 2,它有两个事务。如前所述,所有unixInodelnfo 对象都存储在共享列表中。当一个线程尝试锁定或解锁数据库文件时,SOLite 首先检查列表中文件inode的unixInodelnfo 对象是否存在。如果未找到,SQLite在列表中创建一个新的unixInodeInfo 对象此时,nRef成员变量被设置为1。如果找到一个,则nRef变量增加1。当文件不再被进程使用(即,当nRef变为0)时,unixInodelnfo对象将从列表中删除并销毁。
4.2.6.4多线程应用程序
SOLite应用程序的多线程会在支持LinuxThreads的Linux系统中导致一些额外的问题。在LinuxThreads下,一个线程对某个线程的锁操作不会覆盖其他兄弟线程对同一文件的锁。只是,所有者线程可以操纵其锁。因此,LinuxThreads不兼容BOX,由于这个问题,从SOLite3.7.0版本开始,SOLite开发团队就停止支持LinuxThreads。相反,它们支持NPTL(Native Posix线程库),其中兄弟线程可以重写彼此的锁。
在关闭文件时存在一个复杂的问题。当一个文件描述符(对于inode)被关闭时,Linux 系统会释放当前进程拥有的与该inode相关的所有锁,而不管是通过哪个文件描述符获取这些锁的。为了解决这个问题,我们需要跟踪该 inode 上的所有打开的文件描述符,直到最后一个文件描述符被关闭,当一个线程尝试关闭一个 Unix文件时,如果在同-inode 上还有其他正在持有锁的 Unix 文件,那么关闭该文件的调用将被延迟,直到所有锁都被清除。这被称为懒惰文件关闭。懒惰关闭可能会导致有价值的文件描述符资源被保留;但是,SOLite开发团队没有另一种可行的替代方法。unixlnodelnfo对象保持需要关闭的文件描述符(pUnused)的列表。最后关闭文件的线程会关闭所有这些延迟的文件描述符。
注意: 当应用程序再次打开文件时,pUnused中的文件描述符也可以被SOLite回收
4.2.7锁定API
锁管理器实现了两个API函数,即sqlite30sLock和sqlite30sUnlock,分别用于获取或升级和释放或降级数据库上的SQLite锁。在以下两个子小节中,我将它们以算法步骤的形式呈现。
4.2.7.1 sqlite30sLock API
AP|函数的签名如下:intsqlite30sLock(unixFile*id,intlocktype),其中id 是一个 SQLite fle描述符,请求 1ocktype的 SQLite锁。对于Unix,这是在os unix.c源文件中作为unixLock函数实现的。您可能会注意到锁类型值不能是等待的。此功能只能按以下顺序增加锁的强度:无锁、共享、保留、等待和排他。sqlite30sUnlockAPI函数用于降低锁定强度。大致上,以下步骤由salite30sLock函数执行。


4.2.7.2 sqlite30sUnlock APl
API 函数的签名如下:int sqlite30sUnlock(unixFile*id,intlocktype),其中 id 是-个 SOLite fle 描述符,请求 locktype的 SOLite 锁。对于 Unix,这将被转换为os unix.c源文件中的posixUnlock函数。您可能会注意到锁类型只能是无锁或共享锁。为了增加当前锁的强度,我们需要使用sqlite30sLockAPI函数。以下步骤由sqlite30sUnlock函数执行。

日志是恢复信息的存储库,用于在中止事务、事务或语句子事务时恢复数据库,也用于在应用程序、系统或电源故障后恢复数据库。SQLite对每个数据库使用一个日志文件。(它不使用内存数据库的日志文件),它只保证事务的回滚(撤销,而不是重做),日志文件通常被称为回滚日志。日志文件总是与数据库文件位于相同的目录中,并且具有相同的名称,但附加了‘-journal ’。
暂态日志vs日志保留: SOlite一次最多允许一个数据库文件写事务。在默认的操作模式下,它为每个写事务创建日志文件,并在事务完成时删除该文件。您可以通过日志模式pragma更改此行为,以截断,保留(但使标题无效),内存或关闭。使用memoryoption时,日志完全驻留在内存中,使用off选项时,不执行日志记录。我在249页的10.17节中谈到了日志记录。
当前write- transaction中的更新操作(SQL插入、删除和更新)产生的日志记录被写入日志文件。当事务想要更改数据库文件时,SQLite在回滚日志中写入足够的信息,以便在需要时将数据库恢复到事务开始时的状态。数据库社区有许多已知的日志记录方案;它们取决于日志记录中存储的redo/undo信息。$QLite使用了所有已知类型中最简单的,但效率较低的。它在页面级粒度上使用旧的值日志技术,(SOLite在恢复数据库时不实现重做逻辑)。因此,它不会在日志记录中保存新值。)因此,在事务第一次修改数据库文件的任何页面之前,sqlite将整个页面的原始内容及其页码写入回滚日志。作为新稳定日志记录的一部分。(见第92页图3.8)
一旦页面映像被复制到回滚日志中,该页将永远不会出现在新的日志记录中——即使当前事务多次更改该页。这种页面级undo日志的一个很好的特性是,可以通过盲目地将日志文件中的内容复制到数据库文件中来恢复页面,并且撤销操作是幂等的。undo操作的执行不产生任何补偿日志记录。$QLite不会在日志中保存由事务新添加(即追加)到数据库文件的页面,因为该页没有旧值。相反,日志文件在创建日志文件时,会在journalsegment头记录中记录数据库文件的初始大小(参见第91页的图3.7)。如果数据库被事务扩展,则文件可以在回滚时被截断回其原始大小。
Journaled Page Tracking:SQLite 使用内存中的位映射数据结构来跟踪当前事务记录的页面。内存空间开销与事务更新的页面数量成正比。对于小事务,内存开销可以忽略不计。
Log Optimization: 您可能还记得,自由列表“叶子”页面内容被视为垃圾。当重用这样的页面时,不会记录该页的日志,因为它没有任何有用的信息。
如果一个事务处理和修改多个数据库(您可能还记得,通过执行ATTACH命令可以将多个数据库关联到一个库连接),则每个数据库都有自己的回滚日志,它们是独立的回滚日志,并且一个数据库不知道其他数据库。为了弥补这一差距,SQLite还维护了一个单独的aggregatejournal,称为主日志。主日志文件始终与主数据库文件位于相同的目录中,并且具有相同的名称,但在其后面附加‘-mi’。它是一个临时文件,它是由8个随机选择的4位十六进制数字创建的。事务尝试提交,并在提交处理完成时删除。它本身不包含任何用于回滚目的的日志记录。相反,它包含参与事务的所有单个回滚日志的名称,单个回滚日志的Bach还包含主日志的名称(参见第94页的图3.9)。如果没有附加的数据库(或者没有任何附加的数据库参与当前事务进行更新),则不会创建主日志,并且正常的回滚日志不包含有关主日志的任何信息。在本节的其余部分,我将讨论日志和提交协议
No Database Aliasing: 不能对数据库文件使用不同的名称(硬链接或软链接)。如果不同的应用程序使用不同的名称,同一数据库将有不同的日志文件,具有不同的回滚和主日志名称,应用程序将错过彼此的日志文件,导致损坏的数据库文件。此外,您不应该重命名数据库文件而不重命名相应的日志文件。但是,如果日志是从主日志引用的,则仍然存在风险。你太严厉了 警告!
4.3.1 Logging protocol
SOLite遵循写前日志(WAL)协议,以确保在应用程序、系统或电源故障发生时数据库的可恢复性。SOLite实现预图像日志,即它将数据库页(即将被修改)的原始未修改副本首先写入日志文件,然后再更改数据库文件中的页。在日志文件中写入日志记录是懒惰的:SQLite不会立即将它们刷到磁盘表面。但是,在写入数据库文件中的下一页(任何一页)之前,它会强制将所有日志记录写入磁盘。这被称为刷新日志。刷新日志是为了确保已写入日志的所有日志记录实际上都到达了磁盘表面。(如果本地操作系统的刷新操作不以这种方式工作,SQLite最终可能会损坏数据库。)在日志被刷新且日志内容成为持久性之前,就地修改数据库文件是不安全的。如果在日志被刷新之前对数据库进行修改,并且发生电源故障,未刷新的日志记录将丢失,SQLite将无法从数据库中完全回滚事务的影响,从而导致数据库损坏。
4.3.2 Commit protocol
默认的提交逻辑既包括提交时刷新日志,也包括提交时刷新数据库。当应用程序提交事务时,SOLite确保回滚日志中的所有日志记录都在磁盘上。在提交结束时,回滚日志文件被最终化(即,根据操作式删除、截断或无效,事务完成。如果在达到该点之前系统失败,则事务提交失败,当数据库下次读取时将被回滚。然而,在最终确定回滚日志文件之前,所有对数据库文件的更改都会被写入磁盘。这样做是为了确保在日志最终确定之前,数据库已经接收到来自事务的所有更新。这是必要的,因为从SOLite3.7.8开始,在遗留/回滚日志模式中,SOLite没有重做逻辑。
Asynchronous Transaction and Lazy Commit: 默认情况下,事务是同步的。sqlitessection 4.3.1)和提交协议(见Section 4.3.2)来处理这些事务。虽然不推荐使用,但SQLite也允许应用程序以延迟提交模式运行事务。这些被称为异步事务。它可以通过将同步编译变量设置为零来实现(参见第226页第10.1节)。对于异步事务,SQLite不会在提交或其他时间执行日志或数据库刷新。因此,数据库的写和提交都非常快。但是,当然存在风险,一旦发生故障,数据库可能无法恢复到一致状态(因为日志中丢失了日志记录)并损坏。异步事务开发人员已经收到警告!对于临时数据库,默认是异步的,因为我们不需要也不关心这些数据库的故障。
4.4 Subtransaction Management
一个语句子事务通过主用户事务获取锁。所有锁由该事务持有,直到它提交或取消。但是,SOLite使用一个单独的日志文件来存储语句子事务产生的日志记录。语句日志是一个临时文件,对于从事务取消的恢复或应用程序、系统和电源故障都不需要。SQLite在语句日志中写入一些日志记录,同时在主回滚日志中写入一些日志记录。只有当语句子事务执行开始之前主回滚日志中已写入相应页面或由先前子事务添加该页面时,才会在语句日志中写入日志记录。 SOLite从不将语句日志内容冲洗到磁盘,因为故障恢复不需要这些内容。
Summary
SQLite 在用户或系统事务中执行每个 SQL语句。默认操作模式是自动提交。在这种模式下,SQLite 创建一个读事务来执行SELECT语句,以及一个写事务来执行非 SELECT(即,插入、删除或更新)语句。在语句执行结束时,事务被提交或取消。
应用程序通过执行开始命令创建用户事务来覆盖默认的自动提交模式。连续的未选择 SOL语句执行成为用户事务的一部分,直到应用程序提交或中止事务。在这一点上,SQLite会恢复到自动提交模式。SQLite还支持用户事务中的保存点。事务可以设置多个保存点,并将数据库状态恢复到任何保存点,然后从那里继续执行。在用户事务中,更新语句在子事务中依次执行。这些子事务通过匿名保存点执行。
SQLite使用基于锁的并发控制机制来确保事务的可序列化执行。它使用数据库级锁定,也就是说,它在整个数据库上设置锁,并且没有细粒度锁。SQLite定义了五种锁类型:无锁、共享、独占、保留和挂起。(这些锁是在数据库文件的不同字节上使用本机读和写锁实现的。)读事务从nolock移到共享锁,然后再移回nolock。写事务从nolock到共享锁,再到保留锁,再到挂起锁,再到排他锁,然后再回到nolock。当数据库需要通过回滚日志文件来恢复时,这个锁转换是从nolock到共享锁,再到挂起锁,再到排他锁,再回到共享锁
当一个应用程序通过执行开始事务命令来打开用户事务时,该事务在此时不会对数据库持有任何锁定。锁定获取被推迟到实际需要时。开始命令有两种变体,即开始独占和开始立即。在成功执行开始独占(或立即)命令后,SQLite立即在所有数据库(主数据库和附加数据库)上设置独占(或保留)锁定。
SOLite实现了一种基于日志的日志方案,用于在事务中断、进程崩溃或系统/电源故障时恢复数据库。在这种情况下,SOLite通过一些简单的撤销操作从数据库中撤销事务的影响。当事务修改页面(第一次)时,SOLite将(整个)页面的旧值记录在撤销日志中。在从数据库中撤销事务的影响时,恢复旧页面映像。(恢复操作是幂等的。)在恢复过程的末尾,数据库文件被截断到事务开始时的大小;这是为了消除由事务添加的所有页面。为了执行“多数据库事务”,SOLite使用主日志(除了所有单独的回滚日志)来保存有关参与事务的数据库的信息;此外,每个单独的回滚日志都包含指向主日志的记录。
在下一章中,我将介绍SQLite世界中名为Pager的事务管理器的内部工作。这里介绍的一些概念将在这里重复,以便使本章内容完整。
第五章 Pager Module
阅读本章后,你应该能够解释/描述:
- 什么是页面缓存,为什么需要它,以及谁在使用它
- 通用缓存管理技术
- 由SOLite执行的正常事务处理和恢复处理步骤
章节概要
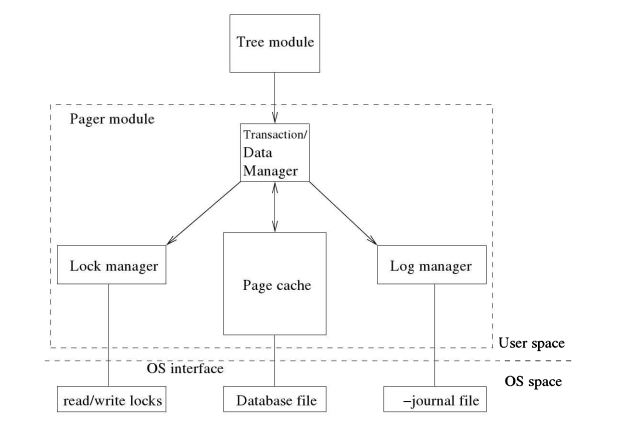
文件之上实现了,本章讨论了寻呼模块。该模块在普通的本地(字节导向)其中数据项是固定个面向页的数据库文件系统的抽象。它作为数据管理器,大小的页,并定义了一个从数据库文件中访问页的接口。它通过为数据库页面提供内存缓存来帮助树模块加速对数据库页的访问。它管理页面缓存,也是事务管理器,通过负责并发控制和故障恢复来实现事务的ACID属性。它使并发控制和恢复对树形和更高层次的模块完全透明。它也是锁和日志管理器。实质上,它实现了普通数据库管理系统的持久层。
5.1 The Pager Module
数据库(内存中的数据库除外)通常以普通本地文件的形式驻留在外部存储设备(如磁盘)上,SOLite不能有效地访问和操作磁盘上的数据。当它需要一个数据项时,它从数据库文件中将其读入主内存,操作内存,如果需要,将其写回数据库文件。通常,与可用的主内存相比,数据库非常大。只有一部分内存被保留来保存来自数据库文件的一小部分数据。这些预留的内存空间通常被称为数据库缓存或数据缓冲区;在SQLite术语中,它被称为页面缓存。缓存驻留在应用程序进程地址空间中,而不是操作系统空间中。(操作系统有自己的数据缓存。
页面缓存管理器在SQLite中称为分页器。它查看随机访问的面向字节的普通本机文件,并将它们转换为随机访问的更高级别面向页面的文件,其中页面是由本机文件构建的固定大小的对象。不同的高级文件可以有不同的页面大小。分页器定义了一个“易于使用”(独立于原生文件系统)的接口,用于从数据库文件访问页面。直接位于pager模块顶部的tree模块总是使用pager提供的接口来访问数据库,从不直接访问任何数据库或日志文件。前者(树模块)通过提供页和引用页的数组indexnumber,将数据库视为(统一大小的)页和引用页的逻辑数组。
SOLite为每个打开的数据库文件(也就是数据库连接)维护一个单独的页面缓存。当一个应用程序进程打开一个数据库文件时,分页器为这个文件创建并初始化一个新的页面缓存。如果进程打开同一个数据库文件两次或两次以上,在默认模式下,page会为这个文件创建并初始化这些单独的页面缓存(SQLite支持一个高级特性,即所有数据库连接到同一个数据库文件可以共享文件的相同页面缓存,该文件通过相同或不同的库连接多次打开,参见第10.13节)。内存数据库不引用任何外部存储设备:但是,它们也像普通的本机文件一样被处理,并且完全存储在缓存中。因此,树模块使用相同的接口来访问任意一种类型的数据库。
分页器是SQLite中最底层的模块。它是唯一使用本地操作系统支持的I/0 api访问nativedatabase和iournal文件的模块。它直接读取和写入数据库文件(和日志文件)。它不理解数据库中的数据项是如何组织的,它既不解释数据库的内容,也不修改自己的内容。它只保证存储在数据库文件中的任何信息都可以在以后不做任何更改的情况下重复检索。从这个意义上说,寻呼机是一个被动的实体。(虽然它可能会修改数据库文件头记录中的一些信息,例如文件更改计数器。)它采用了通常的随机访问面向字节的文件系统,并将其抽象为一个基于随机访问页的文件系统,用于处理数据库文件。它定义了一个易于使用的、独立于系统的接口,用于从数据库文件中随机访问页面。
对于每个数据库文件,在文件和(内存中的)缓存之间移动页面是分页器作为缓存管理器的基本功能。页面移动对树和上层模块是透明的,分页器是本地文件系统和上层模块之间的中介。它的主要目的是使数据库页在主存中可寻址,以便这些模块可以直接访问内存中的页内容。它还将写页面协调回数据库文件。它创建了一个抽象,使整个数据库文件看起来作为页面数组驻留在主内存中。这两个模块通过定义良好的页面访问协议一起工作。
除了缓存管理工作外,分页器还实现了非典型数据库管理系统(DBMS)的许多其他功能。它提供了典型事务处理系统的核心服务:事务管理、数据管理、日志管理和时钟管理。作为事务管理器,它通过负责并发控制和恢复来实现事务性ACID属性,它负责事务的原子提交和回滚。作为数据管理器,它与缓存协调数据库文件中页面的读写,并进行文件空间管理工作;作为日志管理器,它决定日志记录在日志文件中的写入;作为锁管理器,它确保事务在访问数据库页面之前对数据库文件有适当的锁。从本质上说。对等模块实现存储持久性和事务原子性。寻呼机所有子模块之间的相互关系如图5.1所示。
5.2 Pager Interface
在本节中,我将介绍由分页模块公开的一些接口函数,树模块使用这些接口函数来访问数据库。在此之前,我首先讨论分页器和树模块之间的交互协议。
5.2.1 Pager-client interaction protoco)
分页器上面的所有模块都与低级锁和日志管理机制完全隔离。实际上,它们并不知道锁定和日志记录活动。树模块从事务的角度看待一切,而不关心事务性ACID属性是如何由分页模块实现的。分页模块将事务的活动分为时钟、日志记录和数据库文件的读写。tree模块根据页码从寻呼机请求页面。反过来,分页器返回一个指向加载到页缓存中的页数据的指针。在修改页面之前,树模块通知分页器,以便它(分页器)可以保存足够的信息(在日志文件中)以备将来恢复时使用,并且可以获得数据库文件上的适当锁。tree模块最终会在它(tree模块)使用页面完成时通知寻呼者;如果页面被修改,分页器处理将页面写回数据库的操作。
5.2.2 The pager interface structure
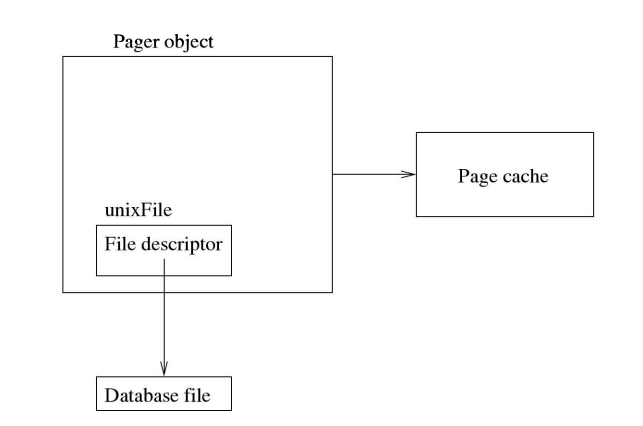
分页模块实现了一个名为pager的数据结构。每个打开的数据库文件都是通过一个单独的Pager对象来管理的(见图5.2),每个Pager对象都与一个且只有一个打开的数据库文件实例相关联。(在分页模块级别,对象是数据库文件的同义词。)为了使用数据库文件,tree模块首先创建一个新的Pager对象,然后使用该对象作为句柄在文件上应用所有分页级操作。分页模块使用句柄来跟踪文件锁、日志文件、数据库状态、日志状态等信息。您可能会注意到,一个进程可以为同一个数据库文件拥有多个Pager对象,每个连接一个到该文件;对象被视为独立的。而且彼此没有关系。(对于共享缓存模式的操作,每个数据库文件只有一个epager对象,由所有数据库连接共享。)也可以使用Pager对象作为句柄访问内存数据库。
Pager对象的一些组件成员变量如图5.3所示。成员变量的用途将在图中讨论。如图所示,紧跟在Pager对象之后的是可变数量的内存空间,用于存储各种处理程序,例如页面缓存、数据库文件、日志文件、数据库文件名称和日志文件名。(我已经在第108页的4.2.6.3节和110页的图4.6中讨论过数据库文件句柄(Linux的unixFile)。)
如前所述,SOLite在用户事务中执行每次更新(即:(SQL插入、删除或更新)保存点中的操作。应用程序还可以设置自己的保存点。可以同时有多个保存点,如图5.3中的保存点数组所示。:创建一个保存点,它将iHdrOffset设置为0。但是,如果它打开回滚日志并在保存点处于活动状态时写入(新的)段头记录,它将ildrOfset设置为紧跟在回滚日志中最后一个日志记录之后的字节偏移量,该日志记录位于段头之前。ioffset被设置为创建PagerSavepoint对象时回滚日志中的起始偏移量。
5.2.3 The pager interface functions
pager模块实现了一组接口函数(由树模块使用)。下面将简要讨论一些重要的接口函数(这些函数的描述将给你一些提示信息,这些信息对阅读本章的其余部分很有价值)。还有许多其他类似的函数。所有函数名的前缀都是salite3Pager, Thevare在page .c源文件中定义。它们严格地属于SQLite内部,SQLite应用程序开发人员不能在他们的应用程序中使用它们。
- sqlite3PagerOpen:这个函数创建一个新的Pager对象,打开一个给定的数据库文件。创建并初始化一个空页缓存,并返回指向Pager对象的指针。根据数据库文件的名称,它创建和/或打开一个适当的文件(参见第81页的3.1节)。数据库文件此时未被锁定;没有创建日志文件,也没有执行数据库恢复操作。(您可能会注意到,$QLite会延迟恢复,直到实际从数据库文件中读取页面。
- salite3PagerClose:这个函数销毁一个Pager对象并关闭相关的opendatabase文件。如果是临时文件,寻呼机将删除该文件。如果该例程不是临时文件,并且在调用该例程时该文件上的事务正在进行中,则强制立即中止该事务,并从数据库文件回滚其更改。所有未完成的缓存页都无效,并且释放它们的内存(即从进程地址空间释放)。在此函数返回后,任何试图使用与此缓存关联的页面的尝试都可能导致coredump。(实际上,分配给pager对象的所有资源都被释放,包括对象本身。)

- sqlite3PagerGet:这个函数为调用者(也就是树模块)提供一个数据库页面的内存副本。调用方通过页码指定所需的页面。这个函数返回一个指向页面缓存副本的指针。为了不回收缓存空间,它固定了页面副本。它在第一次调用时获取数据库文件上的共享锁。(如果无法获得锁,它将返回SQLITE BUSY给调用者。)此时,它决定是否清除现有的页面缓存,如果数据库文件更改计数器(文件头偏移量24处的4字节整数)与先前访问缓存时不同,则清除缓存。此外,如果有需要(在存在热日志文件的情况下),可以从日志中恢复数据库。(我讨论热门新闻。和数据库恢复(见第146页的5.4.2.4节)。如果页面不存在,则该函数将所需的页面加载到缓存中。但是,如果数据库文件小于请求的页面,则不执行实际的文件读取,并且将页面的内存映像初始化为全零。(内存数据库没有文件访问。

- sqlite3PagerWrite:这个函数使所请求的数据库页面对于调用来说是可写的(但是不把页面写到数据库文件中)。它必须在一个页面上被调用,在它的缓存图像被树模块改变之前,否则分页器可能不知道缓存的页面被改变了。(您可能会注意到,出于性能考虑,SQLite避免在分页器和树模块之间来回作用域页面,而树模块直接操作缓存页面中可用的内容。)如果在之前的某个函数调用中没有这样做,则分页器将获取数据库文件上的保留锁并创建回滚日志。也就是说,它创建了一个隐式写事务。(如果无法获得锁,它将返回SOLITE BUSY给调用者。)如果页面还不是日志记录的一部分,它会将页面的原始内容复制到回滚日志中。如果原始页面内容已经被写入回滚日志,这个函数除了将页面标记为脏之外是无操作的。如果当前查询处理发生在用户事务中,并且该页已经在主回滚日志中或者该页是由上一个语句子事务添加的,这个函数也可以在语句日志中写入语句日志记录。
- sqlite3PagerLookup:如果被请求的数据库页面在缓存中,这个函数返回一个指向缓存内副本的指针。如果页面不在缓存中,则返回turnsnull。如果是前一种情况,则锁定页面。
- sqlite3PagerRef:这个函数将页面上的引用计数加1。我们说这个页面被打电话的人固定住了。如果页面在缓存的自由列表中,该函数将从列表中删除该页。
- sqlite3PagerUnref:这个函数将页面上的引用计数减1。当计数达到零时,该页被称为解除固定并被释放。(释放的页面可能仍然作为缓存的自由列表的一部分保存在缓存中。)当所有页面都被解除固定(即,在最后一次调用该函数时)时,数据库文件上的共享锁被释放,Pager对象被重置。
- sqlite3PagerBegin:该函数在关联的数据库文件上启动显式写事务。如果数据库不是临时文件,它还打开回滚日志文件。(对于临时文件,日志文件的打开被推迟,直到有实际需要写入日志文件,)你可能会注意到一个隐式写事务是由ysqlite3pagerwrite启动的。因此,如果数据库已经预留用于写入,则此例程是无操作的。否则,它首先获得数据库文件上的保留锁,如果在输入参数中指出,那么它立即获得文件上的排他锁,而不是等到树模块试图写入数据库文件。
- sqlite3PagerCommitPhase0ne:这个函数在数据库文件上提交当前事务:将内存更改计数器元数据加1,同步日志文件,同步所有更改(也就是从页面缓存中的脏页面)到数据库文件。
- salite3PagerCommitPhaseTwo:这个函数结束(即,删除,无效或截断日志文件)。
- sqlite3PagerRollback:这个函数终止数据库文件上的当前事务。回滚事务对数据库文件所做的所有更改,并将独占锁降级为共享锁,所有缓存内页面恢复为原始数据内容。日志文件已完成,此例程不能失败。
- sqlite3PagerOpenSavepoint:这个函数创建一个新的保存点处理程序对象,为当前数据库状态建立一个保存点。
- sqlite3PagerSavepoint:这个函数释放或回滚一个保存点。对于releaseoperation,它释放并销毁一个特定的保存点处理程序对象。对于回滚操作,它回滚自建立保存点以来对数据库所做的所有更改。并删除以下所有保存点
5.3 Page Cache
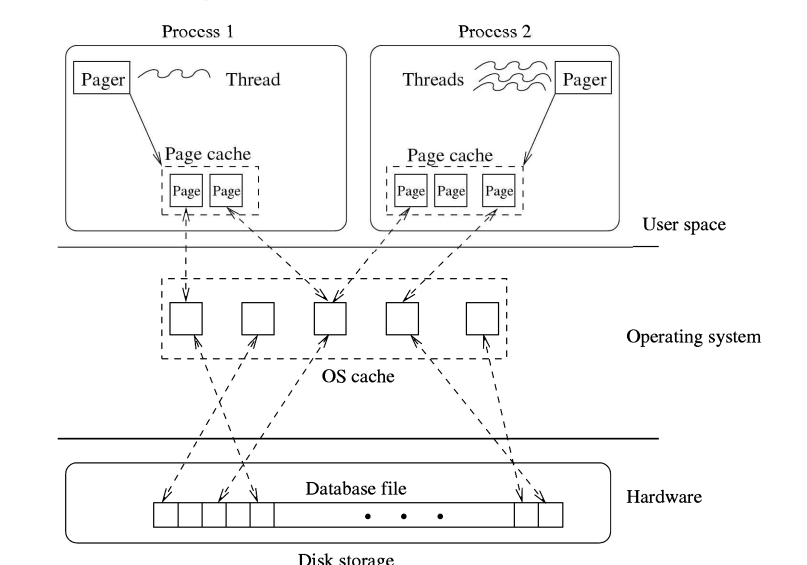
页面缓存驻留在应用程序进程的地址空间中。您可能会注意到,相同的页面可能由本机操作系统缓存。当应用程序从任何文件(驻留在块专用设备上)读取数据时,操作系统通常首先生成自己的数据副本,然后在应用程序中生成副本。我们对操作系统如何管理自己的缓存不感兴趣。SQLite的页面缓存组织和管理是独立于本地操作系统的。图5.5描述了一个典型的场景。在图中,两个进程(一个是多线程进程)访问同一个数据库文件。他们有自己的伤痛。即使一个线程打开同一个数据库文件两次或多次,在默认的操作模式下,SQLite也会为打开的数据库连接分配单独的缓存。这些缓存可以通过它们不同的所有者Pager对象来访问。
5.3.1 Cache state
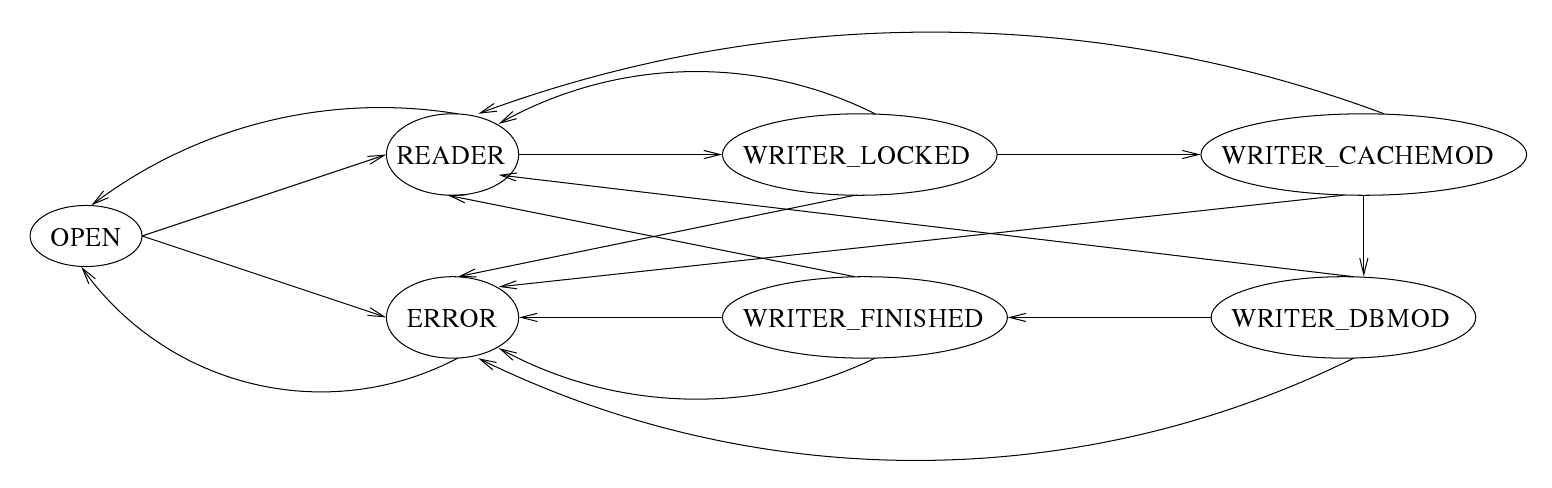
页面缓存的状态(以及相应的所有者Pager对象的状态,参见第126页上的图5.3)决定了分页模块可以对缓存做什么。两个成员变量,即eState和eLock,控制寻呼机行为。页面缓存(和分页器)作为一个整体始终处于以下七种状态之一(pager . estate成员变量的值)。状态转换图如图5.6所示。
- PAGER_OPEN:当创建Pager对象时,这是初始状态。分页器当前没有通过这个pager对象读写数据库文件。内存中可能没有任何数据库页,也就是说,缓存是空的。数据库文件可能被锁定,也可能没有被锁定。数据库上没有打开的事务。
- PAGER_READER:当一个Pager对象处于这种状态时,至少有一个读事务操作在数据库连接上,并且该Pager可以从相应的数据库中读取页面。(但是,在exclusive locking_mode下,读事务可能不会打开。
- PAGER WRITER LOCKED:当一个PAGER对象处于这种状态时,一个写事务在数据库连接上打开。分页器可以从相应的数据库文件中读取页面,但它没有对缓存的页面或数据库文件进行任何更新。
- PAGER_WRITER_CACHEMOD:当一个Pager对象处于这种状态时,该Pager已经授予了树模块更新缓存内页面的权限,并且树模块可能已经进行了一些更新。
- PAGER_WRITER DBMOD:当Pager对象处于这种状态时,表示该Pager已经开始写入数据库文件。
- PAGER WRITER FINISHED:当一个PAGER对象处于这种状态时,表示该PAGER对象已经完成了将当前写事务中所有修改过的页面写到数据库文件中的工作。写事务不能再进行任何更新,并准备提交。
- PAGER_ERROR:当一个Pager对象处于这种状态时,该Pager已经看到了一些错误,例如无法执行I/O,没有可用的磁盘空间用于数据库或日志文件,不能分配ncmemory等。
根据eLock成员变量的值,Pager对象可以处于以下四种状态之一
- NO LOCK:分页器当前没有通过该Pagerobject读写数据库文件。
- SHARED LOCK:分页器一直在从数据库中读取页(以任意顺序)。可以有多个读事务通过各自的Pager对象同时访问同一个数据库文件。不允许修改缓存内页面。
- RESERVED_LOCK:分页器为写入保留了数据库文件,但尚未对该文件进行任何更改。一次只能有一个分页器可以保留给定的数据库文件。由于原始数据库文件未被修改,因此允许其他寻呼机读取该文件。
- EXCLUSIVE LOCK:该分页已经将页面(以任意顺序)写回数据库文件,该文件访问是排他的,当该分页继续写文件时,没有其他分页可以读写该文件。
页面缓存出现在NO_LOCK状态。当树模块第一次调用qlite3pagerget函数从数据库文件中读取任何页面时,分页器将转换到shashared LOCK状态。在tree模块通过执行sglite3pagerunrefunction释放所有页面之后,分页器将转回NO _LOCK状态。(此时,它可能不会清除页面缓存。)当树模块第一次在任何页面上调用sqlite3PagerWrite函数时,分页将转换到RESERVED LOCK状态。(你可能会注意到sqlite3PagerWrite函数只能在已经读取的页面上调用;这意味着分页在转换到RESERVED LOCK状态之前必须处于shared LOCK状态。)在实际将第一个(任何)页写入数据库之前,页切换到EXCLUSIVE LOCK状态。在执行sqlite3PagerRollback或sqlite3pagercommitphasttwo函数的过程中,页传呼会转回NO LOCK状态
注意: 对于临时数据库和内存数据库,Pager。eLock总是被设置为EXCLUSIVE lock,因为它们不能被其他进程访问。
5.3.2 Cache organization
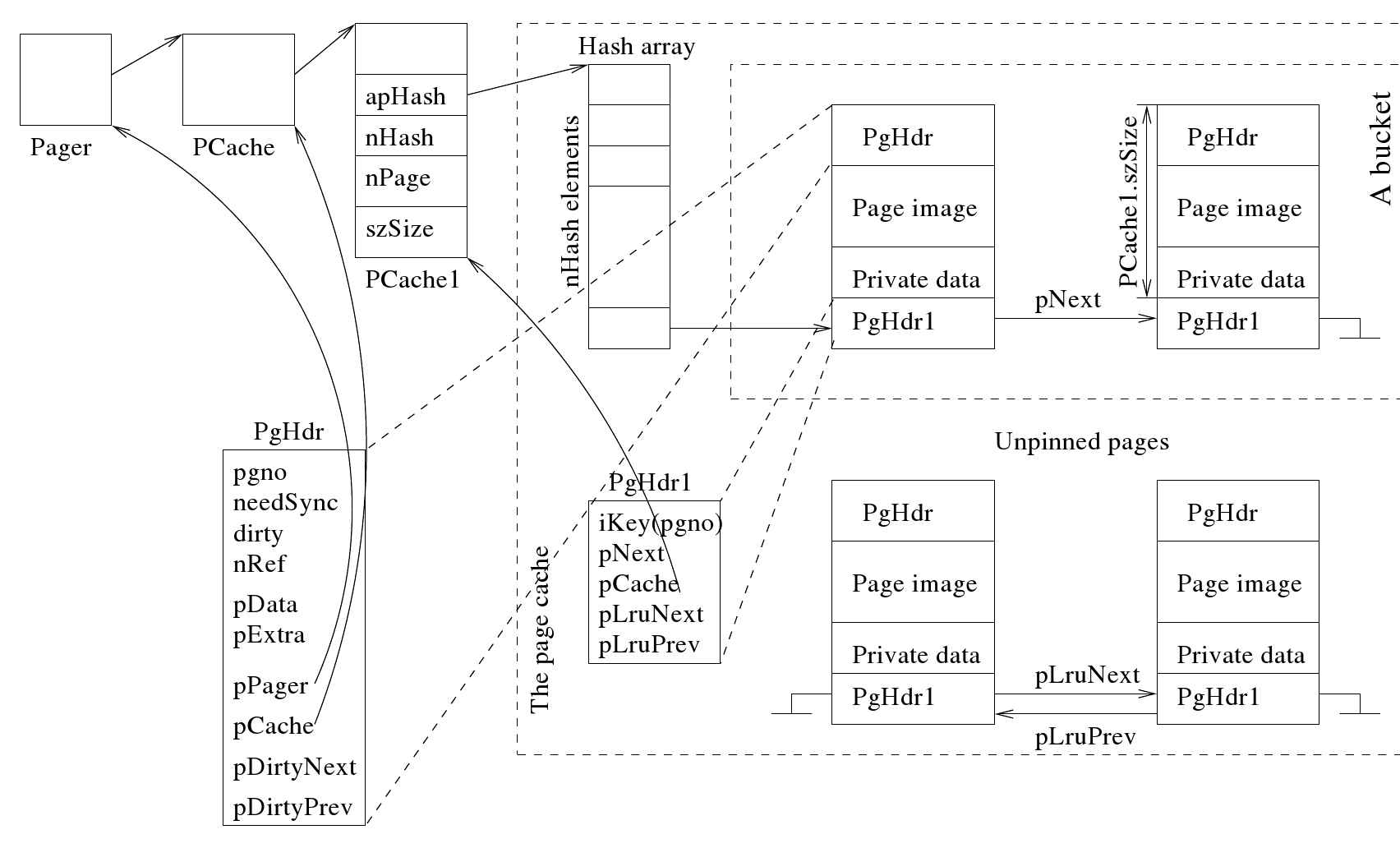
每个页面缓存都是通过一个PCache处理程序对象来管理的。page保存着对这个对象的引用(参见第126页的图5.3)。图5.7描述了一个PCache对象的几个成员变量。SQLite支持用户可以提供的可插拔缓存方案。它提供了自己的pluggablecache模块(在pcachel.c源文件中实现),我将在下面讨论这个模块。除非用户提供,否则这将成为默认的缓存管理器。PCache对象的最后一个组件,即PCache,持有对可插拔缓存模块对象的引用。
通常,为了加快搜索缓存的速度,当前保存在缓存中的项被很好地组织起来。缓存空间是用来存放数据项的。SQLite使用散列表来组织缓存的页面,并使用页面槽来保存表中的页面。缓存是完全关联的,即任何插槽都可以存储任何页面。哈希表最初是空的。随着对页的需求增加,分页器创建新的槽并将它们插入哈希表中。有一个最大限制(PCache . nmax值)或缓存可以拥有的插槽数量。主数据库和其他附加数据库的默认值是2000,临时数据库的默认值是500。(只要操作系统允许应用程序地址空间增长,内存数据库就没有这种限制。)

SQLite通过PgHdr类型的对象表示缓存中的每个页面。分页器理解这个对象,尽管可插拔缓存可以有自己的页头对象。图5.8描述了SQLite自己的可插拔缓存的布局,由一个PCache1对象表示。哈希表中的每个槽由PgHdr1类型的头对象表示。可插入组件理解这种类型,而分页器对它来说是不透明的。槽映像存储在PgHdr1对象的正前方;slot映像的大小由PCache1的值决定。szSize变量。slot映像保存PgHdr的一个对象、一个数据库页面映像和一个私有数据,tree模块使用这个私有数据来保存特定于页面的内存控制信息。(内存数据库没有日志。因此,它们的恢复信息记录在内存对象中。指向这些对象的指针仅供分页器使用。)这(additiona。存储在private部分之后:当分页器将页面带入或构造到cache中时,这些指针(如onpage)空间初始化为零。缓存中的所有页面都可以通过PCache1访问。apHash哈希数组;数组大小存储在PCache1中。变量,数组将根据需要调整大小。每个数组元素都指向一个槽的“桶”:每个桶中的槽被组织成一个无序的单链表。
PgHdr对象只对分页模块可见,而对树和上层模块不可见。头文件有许多控制变量。pgno变量标识它所代表的数据库页面的页码。如果日志在将该页写入数据库文件之前需要刷新,则needSync flag为true。如果页面已被修改,并且新值尚未写入数据库文件,则脏标记为true。nRef变量是本页的引用计数。如果nRef值大于零,则该页处于活跃使用状态,我们说该页已被固定;否则,页面将被解除固定并释放。pDirtyNext和pDirtyPrevpointers用于将所有脏页面链接在一起。
Cache Group: There is an option where SQLite puts all PCache1 objects in a single group. The cachescan recycle each other’s unpinned pageslots when they are subjected to memory pressure.
5.3.3 Cache read
您可能还记得,缓存不是直接可寻址的存储单元。缓存客户端不能通过提供缓存地址来引用单个缓存元素。实际上,它们可能不知道页面副本所在的缓存位置,也不知道它的缓存地址。缓存是一个内容可寻址的存储空间。它通过使用搜索键(在我们的示例中是页码)来引用。在缓存和数据库文件之间移动页面是分页器作为数据管理器的基本功能。它使用PCache1。通过缓存桶将页码转换为适当的缓存点的一个ash数组。最初,页面缓存是空的,但是页面会按需添加到缓存中。如前所述,要读取页面,客户端(即树模块)调用sqlite3PagerGet函数的页码。该函数对请求的页面P执行以下步骤。
- It searches the cache space.
- 它应用一个非常简单的哈希函数[-1],在P上确定到apHash数组的索引:页码模取apHash数组的大小。
- 它使用到apHash数组的索引并获取哈希桶。
- 它通过追踪pNext指针来搜索存储桶。如果在那里找到P,我们就说发生了缓存命中。它固定页面(即增加PgHdr)。nRef值乘以1),并将页面图像的基址返回给调用者。
- 如果在缓存中没有找到P,则认为它是缓存缺失。该函数查找可用于加载所需页面的空闲插槽。(如果缓存没有达到PCache的最大限制nMax,它会创建一个新的空闲槽。
- 如果没有可用的或不能创建的空闲插槽,它将确定一个插槽,从该插槽中可以释放当前页面,以便将该插槽重新用于P,这称为受害插槽。(第135页第5.3.6节讨论了受害者的选择。)
- 如果受害者(或空闲槽)是脏的,它将页面写入数据库文件。遵循预写日志(write-ahead-log, WAL)协议,它也会对日志文件进行刷新。
- 两种情况。(a)如果P小于或等于当前文件中的最大页面,它从数据库文件中读取pageP到空闲槽,固定页面(即,它将PgHdr . nrefvalue设置为1),并将页面的地址返回给调用者。(b)如果P大于文件中当前的最大页面,它不读取该页,相反,它将该页初始化为零。在这两种情况下,无论是否从文件中读取该页,它也将底部私有部分初始化为零。它还设置PgHdr。nRef值为1。
SQLite严格遵循按需获取策略,以保持页面获取逻辑非常简单。(SeeSection 5.3.5)。
当缓存内页面的地址返回给客户端(也就是树模块)时,分页器并不知道客户端何时实际处理该页。SQLite对每个页面都遵循这个标准协议:客户端获取(又名,固定)页面,使用页面,然后释放(又名,解锁)页面。当页面地址返回给客户端时,该页面被锁定(PgHdr . nref大于零)。只有当客户端调用页面上的glite3pagerunref函数并且nRef变为零时,页面才会解除固定。固定页当前处于活动使用状态,缓存管理器无法回收它们。为了避免“缓存中的所有页面都被固定”的情况,$QLite需要缓存中的最小页面数,以便它总是有一些缓存插槽可以回收:最小值为10 (Lite 3.7.8版本)
[-1]A hash function maps a larger set onto a smaller set
5.3.4 Cache update
在获取页面后,客户端可以直接修改页面的内容,但是正如前面提到的,在进行任何修改之前,它必须调用页面上的sqlite3PagerWrite函数。阳离子。从调用返回后,客户端可以随时更新页面。
当客户端第一次在页面上调用sqlite3PagerWrite函数时,分页器将页面的原始内容作为新日志记录的一部分写入回滚日志文件,并设置PgHdr . needsync标记。稍后,当日志记录被刷到磁盘表面时,分页器会清除needSync标记。(SQLite遵循WAL协议:在相应的needSync被清除之前,它不会将修改的pageback写入数据库文件。)每次在页面上调用glite3pagerwrite函数时,就会设置PgHdr .dirty标记;只有当分页器将页内容写回数据库文件时,才会清除该flag。由于分页器不知道客户端修改页面的时间,因此页面上的更新不会立即传播到数据库文件。因此,分页器遵循延迟写(也称为回写)页面更新策略。只有当分页器执行缓存刷新或有选择地回收脏页时,更新才会传播到数据库文件。
注意: 事务对缓存页执行直接更新,缓存管理器对数据库文件执行延迟更新。直接缓存更新需要保存页面的旧值,以便在事务中止时恢复它们。延迟更新数据库文件会增加事务的内存使用。当内存使用超过上限时,缓存管理器执行缓存替换。
5.3.5 Cache fetch policy
缓存取策略决定何时将页放入缓存。按需取策略仅在客户端需要页面时才将页面放入缓存。你可能会注意到,在获取需求的过程中,客户端是停滞的,在从数据库文件中读取页面之前,它不能取得任何进展。许多缓存系统使用复杂的预取技术,提前将一些页面放入缓存,以减少延迟的频率。SOLite严格遵循按需取策略,并避免任何其他预取策略,以保持取逻辑非常简单,并检查SQLite库大小。此外,它每次从数据库文件中读取一个页面。
5.3.6 Cache management
一般来说,页面缓存的大小是有限的,除非数据库非常小,否则它只能保存数据库中的少量页面。可能需要回收缓存空间,以便在不同时间保存来自数据库的不同页面。因此,必须非常小心地管理空间,才能从缓存中获得真正的性能。其基本思想是将缓存客户端立即需要的页面保存在缓存中。在设计缓存管理策略时,我们需要考虑三件事。(1)当缓存中有一个页面时,在数据库文件中也有一个该页面的主副本。当缓存副本更新时,主副本可能也需要更新,(2)对于不在缓存中的请求页面,主副本被引用,并且从主副本生成新的缓存副本。(3)如果缓存已满,又有一个新页面要放到缓存中,则调用替换算法从缓存中删除一些旧页面,为新页面腾出空间。
由于缓存是一个有限大小的存储空间,我们将页面集合到少量的缓存槽中(见图5.9)。在图中,有26个母版页,我们需要通过回收槽将它们放入5个缓存槽中。因此,需要很好地管理空间,以便从缓存中获得真正的性能增益。缓存管理对于缓存性能和整个系统性能都非常关键。只要缓存中有可用的空闲槽用于新请求的页面,缓存管理器就不需要做任何艰苦的工作。当缓存满时,缓存管理变得很有挑战性。缓存管理器的职责是决定在缓存中保留哪些内容,以及当缓存满时将删除哪些内容。缓存的有效性是对在缓存中找到请求页面的频率的度量。我们需要一个命中率很高的缓存。因此,对于缓存替换,最关键的事情是确定要在缓存中保留哪些页面。如果决策不好,缓存会被非立即需要的、不重要的页面污染,现在讨论缓存替换。
5.3.6.1 Cache replacement
缓存替换指的是当缓存满了,旧的页面被从缓存中移除为新页面腾出空间时发生的活动,正如第133页的5.3.3节所提到的,当请求的页面不在缓存中并且缓存中没有可用的空闲槽时。寻呼机占用了一个替换槽。选择受害者可能不是一个容易的决定,您可能还记得,页缓存是完全关联的,也就是说,任何插槽都适合新页。由于要考虑多个插槽进行替换,所选择的插槽由缓存替换策略决定。替换策略的主要目标是将这些页面保留在缓存中,这样就可以在不引用母版页的情况下从缓存中满足大部分请求,也就是说,缓存命中率应该非常高。如果缓存命中率很低,那么缓存就不值得用来加速页面访问。
您可能会注意到,我们没有关于未来页面引用模式的知识。因此,缓存管理器必须根据一些启发式方法或有限的过去历史做出替换决策。因此,通常在实践中使用的替代方案偶尔会在选择受害者时犯错误,当受害者被客户立即召回时,这些替代方案很快就会失效。如果再次引用页p,并且在p被替换之后至少有一个缓存槽没有被引用,那么替换页p被认为是一个糟糕的选择。替换策略的目标是最大限度地减少错误和最大限度地缩短错误之间的时间。一个缓存替换策略与另一个缓存替换策略的不同之处在于如何选择替换的受害者槽。文献中提出了许多替代政策,并在各种情况下实施,先进先出,最近最少使用,最不经常使用。时钟方案在硬件和软件开发中广泛遵循缓存替换策略。sqlite使用一种最近最少使用(LRU)的替换方案。
5.3.6.2 LRU cache replacement scheme
LRU是一种非常流行的替换政策。它及其变体已成功地应用于许多软硬件缓存开发领域。它利用了页面引用的时间局部性。(时间局部性是指在短时间内对同一页面的重复访问。)最近过去引用的局部性用于预测最近将来的引用,它的意思是,如果现在访问了一个页面,则假定该页面将很快再次访问。如果一个页面长时间未被访问,则假定该页面不会很快再次被访问。受害者是最久没有被接触过的人
5.3.6.3 SQLite’s cache replacement scheme
SQLite在逻辑队列中组织非活动页面。当分页被解除固定时,分页器将该页附加到队列的尾部。(队列尾部的页面始终是最近访问的页面,而队列头部的页面是过去访问得最远的页面。)受害者是从队列的头端选择的,但在纯IRU方案中可能并不总是队列上的头元素。SQLite尝试在队列的头部找到一个插槽,这样回收该插槽就不会涉及对日志文件进行刷新。(您可能还记得,按照WAL协议,在将脏页写入数据库文件之前,分页器会刷新日志文件。刷新是一个缓慢的操作,并且SQLite尝试尽可能长时间地延迟该操作,如果找到这样的受害者,那么队列上最前面的受害者将被回收。0 therwise。S(item)首先刷新日志文件,然后从队列中回收头槽。如果受害页面是脏的,则分页器在回收页面之前将该页写入数据库文件
5.4 Transaction Management
分页器也是SQLite中的事务管理器,它负责通过管理数据库文件上的锁和管理日志文件中的日志记录来确保transactionalACID属性。尽管SQLite锁管理器(在第4章中讨论)获取和释放文件上的锁,但分页器决定锁的模式以及获取和释放锁的时间。它遵循严格的两阶段锁定协议来生成可序列化的事务执行。它也决定了日志记录的内容,以及它们对日志文件的写入。
像其他DBMS一样,SQLite的事务管理有两个组成部分:(1)正常处理和(2)恢复处理。在正常处理期间,分页器在日志文件中保存足够的恢复信息,并且在需要时使用保存的信息进行恢复处理。这两个处理组件的活动将在接下来的两个小节中介绍。事务管理的位和字节已经在前面的部分讨论过了。在这里,我以一种有凝聚力的方式巩固它们。
5.4.1 Normal processing
正常的处理包括从数据库文件中读取页面和将页面写入数据库文件,提交事务和语句子事务,以及设置和释放保存点。此外,作为正常处理工作的一部分,分页器选择性地回收页缓存槽或刷新页缓存。
5.4.1.1 Read operation
要对数据库页面进行操作,客户端(也就是树模块)需要对页码应用sqlite3pagerget函数。客户端需要调用该函数,即使该页面在数据库文件中不存在:新页面将由分页器创建。 如果在数据库文件上还没有获得共享锁或更强的锁,则该函数将获得数据库文件上的共享锁如果无法获得共享锁,[-2]则意味着其他事务持有不兼容的锁,函数返回SQLITE BUSY错误码给调用者。否则,它执行读取缓存操作(参见第5.3.3节),并返回一个指向该页的指针。如前所述,缓存读取操作固定页面。
[-2]当分页器第一次获得共享锁时,我们说它已经启动了一个隐式锁。
你可能还记得第133页的图5.8,每个内存中的页面图像后面都有一个私有空间块。这个额外的空间总是在页面第一次从数据库文件(或创建并初始化)加载到主内存时初始化为零。这个空间稍后由tree模块重新初始化。
您可能还记得,当分页器第一次获得数据库文件上的共享锁时,它会确定该文件是否需要恢复。它查找相应的日志文件是否存在。(我将在第146页的5.4.2.4节中讨论热日志和故障恢复的确定。)如果热日志文件确实存在,这意味着在数据库上的前一个事务执行过程中出现了失败,分页器回滚失败的事务并在从sqlite3PagerGet函数返回给调用者之前结束(即删除、截断或无效)日志文件。
如前所述,请求的页面可能不在页面缓存中。在这种情况下,pager找到一个空闲的缓存槽,并以用户透明的方式从数据库文件中读取页面,获得一个空闲的缓存槽可能会导致一个(受害者)页面写入数据库文件,也就是说,需要一个cacheAush(参见章节5.4.1.3)。
5.4.1.2 Write operation
在修改页面之前,客户端(也就是树模块)必须已经固定了页面(通过在页面上应用sqlite3PagerGet函数)。它在页面上应用sqlite3PagerWritefunction,使页面可写。一旦页面变得可写,客户端就可以在不通知分页器的情况下更新页面。写页面不会导致缓存刷新。不过,分页器可能需要获取数据库上的保留锁。第一次在(任何)页上调用sqlite3PagerWrite函数时,该页获取数据库文件上的保留锁。保留锁表示在不久的将来写入数据库的意图。一次只有一个事务可以持有保留锁。如果分页器无法获得锁,则意味着另一个事务已经对该文件具有保留的或更强的锁。在这种情况下,写尝试失败,寻呼机返回$QLITE BUSY错误码给调用者。
当分页器第一次获得预留锁时,我们说它将读事务升级为写事务。(您可能会注意到,这是系统事务或用户事务。)此时,分页器创建并打开回滚日志。(回滚日志创建在数据库文件所在的同一目录中,并且具有相同的名称,但附加了‘-journal ’。)初始化第一个段头记录(参见第91页的图3.7),记下该记录中数据库文件的原始大小,并将该记录写入日志文件。
为了使页面可写,分页器将该页的原始内容(在新的日志记录中)写入回滚日志。(您可能会注意到,新创建的页面不会被记录,因为这些页面没有旧值。)一个页最多只能写入回滚日志文件一次。对页面的更改不会立即写入数据库文件。对页面的更改首先保存在缓存中。数据库文件保持不变,这意味着其他事务可以继续从该文件读取。
扇区日志: 如果存储设备中的扇区可以存储多个数据库页面,SQLite记录整个扇区,而不是更新的页面。
页面日志策略: 一旦页面映像被复制到回滚日志中,该页将永远不会出现在新的日志记录中,即使当前事务多次调用该页上的sqlite3PagerWrite函数。这种日志记录的一个很好的特性是,可以通过从日志中盲复制内容来恢复页面。因此,撤销操作是幂等的,它不会产生任何补偿日志记录。SQLite从来不会在日志中保存一个新的页面(由当前事务添加,即追加到数据库文件中),因为没有旧的pace值,相反,当创建日志文件时,数据库文件的初始大小存储在日志段头记录中(参见第91页的图3.7)。如果数据库文件被事务扩展,文件将在回滚时被截断为其原始大小。
5.4.1.3 Cache fush
缓存刷新是寻呼机模块的内部操作;客户端(也就是树模块)永远不能直接加入缓存刷新。当分页器想要从页面缓存中刷新页面时,有两种情况:(1)缓存已经填满,并且需要替换缓存。或者(2)事务已准备好提交其更改。分页器将部分或全部修改过的页面写回数据库文件。在写入之前,分页器必须确保没有其他事务正在读取数据库文件。SQLite遵循WAL协议编写数据库文件。这意味着回滚日志内容可能需要被刷新到磁盘上,以便在将页面写入数据库时发生故障时回滚事务。寻呼机执行以下步骤:
- 它确定是否需要刷新日志文件。如果事务是同步的,并且在日志文件中写入了新数据,并且数据库不是临时文件。[-3]然后传呼机需要做一个日志刷新。在这种情况下,它对日志进行fsync系统调用。他需要确保到目前为止写入的所有日志记录都实际到达磁盘表面。在fsync的这个时候,分页器不写入当前日志段头中的日志记录数(nRec)值。nRec值是回滚操作的宝贵资源。当形成这些段头时,对于同步事务,该数字被设置为0,并被设置为-1。也就是异步的0xFFFFFFFF。)在日志被刷新后,分页器将rec值写入当前日志段标头中,并再次对文件进行fsync。[-4]由于磁盘写入不是原子的,它将不再重写nRec字段。分页器将为新的传入日志记录创建一个新的日志段。在这些场景中,SQLite使用多段日志文件。
[-3] 对于临时数据库,我们不关心是否能够在系统或电源故障后进行回滚,因此不会发生日志刷新。
[-4] 日志文件被刷刷两次。第二次刷新导致覆盖存储nrecfield的磁盘块。如果这种覆盖是原子的,那么我们就可以保证日志在写入时不会被破坏,否则,我们就会有一些小的风险
- 它试图获取数据库文件上的EXCLUSIVE锁。(寻呼机永远不会无条件地等待锁授予。它在非阻塞模式下尝试锁定。如果其他事务仍然持有SHARED锁,则锁尝试失败,并将SQLITE BUSYerror代码返回给调用者。事务没有中止。
- 它将所有修改过的页面(当前保存在页面缓存中)或选择性页面写入数据库文件。页面写入是就地完成的。它将这些页面的缓存副本标记为干净。(此时它不会将数据库文件推送到磁盘。
如果写入数据库文件的原因是因为页面缓存已满,则分页器不会立即提交事务。相反,事务可能会继续对其他页面进行更改。在将后续更改写入数据库文件之前,分页器将再次重复这三个步骤。
注意: 在事务完成之前,分页器获得的写数据库文件的EXCLUSIVE锁将一直保持。这意味着这个进程(通过不同的库连接)和其他应用程序进程将无法在数据库上打开另一个(读或写)事务,从分页器第一次写入数据库文件开始,直到事务提交或终止。对于短事务,更新保存在缓存中,并且在提交期间只有在提交时才会获得排他锁。但是,长事务会导致其他读事务的性能下降
5.4.1.4 Commit operation
根据提交事务是修改单个数据库还是多个数据库,SQLite遵循的提交协议略有不同。
单一数据库情况: 当树模块准备提交事务时。它首先调用sqlite3PagerCommitPhaseOne函数(参见下面列表中的前两项),然后调用sqlite3PagerCommitPhaseTwo函数(下面列表中的最后两项)。提交读事务很容易。分页器从数据库文件中释放共享锁(如果数据库上没有其他读或写事务)并返回到NO lock状态:它不需要清除页面缓存。(下一个事务从一个热页缓存开始。)为了提交写事务,分页器按照列出的顺序执行以下步骤:
- 它获取数据库文件上的EXCLUSIVE锁。(如果锁获取失败,它将返回SQLITE BUSY给sqlite3PagerCommitPhaseOne函数的调用者。它现在不能提交事务,因为来自其他数据库连接的其他事务仍在读取数据库。它增加了数据库元数据动态更改计数器。它按照5.4.13节的算法步骤1-3将所有修改过的(缓存中的)页面写回数据库文件,这被称为“提交时刷新日志”,这样做是为了在回滚日志中保存重要信息,以消除整个事务的影响。
- 许多操作系统(如Linux)将这些写操作缓存在操作系统空间的内存中,并且可能不会立即将它们发送到磁盘。为了克服这种情况,寻呼机对数据库文件进行fsync系统调用,将文件推送到磁盘。这被称为在提交时刷新数据库,这样做是为了消除系统重启时的重做逻辑。
- 然后完成(即……)删除、截断或使日志文件无效。
- 最后,它从数据库文件中释放EXCLUSIVE锁。如果有concurrentselect操作执行(即读事务),则返回SHARED LOCK状态:否则返回NO_LOCK状态;它不需要清除页面缓存。
提交点: 事务提交点发生在回滚日志文件完成的瞬间。在此之前,如果发生电源故障或系统崩溃,则认为事务在提交处理期间失败。下次SQLite读取数据库时,它将从数据库回滚事务的影响。SOLite假定本机操作系统的日志终结是一个原子操作。
多数据库情况: 提交协议有点复杂,它类似于分布式数据库系统中的事务提交。VM模块(VdbeCommit函数)实际上作为提交协调器驱动提交协议。每个数据库的分页器在其数据库上执行自己的“本地”提交部分。对于只修改单个数据库文件(不计算临时数据库)的读事务或写事务,协议对涉及的每个数据库执行正常的提交。如果事务修改了多个数据库文件。执行的提交协议如下:[-5]
[-5] 如果主数据库是“:memory:”, $QLite不保证多数据库事务的原子性。相反,它遵循对单个数据库文件的简单提交
- 释放那些事务没有更新的数据库的共享锁(如果其他读取事务在这个线程中没有活动).
- 在事务已更新的数据库上获取EXCLUSIVE锁。增加数据库文件的文件更改计数器元数据。
- 创建一个新的主日志文件。(主日志总是在与主数据库相同的目录中,并且具有相同的名称,但后面附加了‘-mj’,后跟八个随机选择的4位十六进制数字。即使提交事务没有修改主数据库,也会发生这种情况。用所有个人的名字填充主日志。回滚日志文件,并将主日志和日志目录刷新到磁盘。(临时数据库名称不包含在主日志中。)
- 将主日志文件的名称写入主日志记录中的所有回滚日志中(参见第94页的图3.9),并刷新回滚日志。直到事务提交时,分页器才知道它已经是多数据库事务的一部分。只有在这一点上,它才知道它是多数据库事务的一部分。)
- 刷新单个数据库文件。
- 删除主日志文件并刷新日志目录。
- 完成(删除或截断)所有单独的回滚日志文件。
- 从所有数据库对象中释放EXCLUSIVE锁。所有分页返回SHARED LOCK或NO LOCK状态。寻呼机不需要清除它们的页面缓存。
提交点: 当主日志文件被删除时,事务被认为已经提交。在此之前,如果发生电源故障或系统崩溃,则在提交处理期间将事务视为失败。当SQLite下次读取这些数据库时,它会将它们恢复到事务开始之前的各自状态。
回滚日志结束: 当日志模式为持久化时,日志文件被截断为零大小,而不是使日志头失效。
警告! 如果主数据库是临时文件(或内存中),SQLite不保证多数据库事务的原子性。也就是说,全球复苏可能是不可能的。它不创建主日志。VM模块遵循单个数据库文件的简单提交,一个接一个。因此,可以保证事务在每个单独的数据库文件中都是本地原子的。因此,在发生故障时,其中一些数据库可能会获得事务的更新,而另一些可能不会。
提交失败: 用户级事务由执行COM的应用程序本身提交。MIT命令和SQLite尝试完成事务。如前所述,由于锁冲突,执行COMMIT命令的尝试可能会失败,并可能导致SQLITE BUSY返回代码。这表明另一个事务持有数据库上的共享锁,从而阻止COMMIT成功。当COMMIT以这种方式失败时,事务保持活动状态,并且在其他事务有机会清除它们的共享锁之后,应用程序可以稍后重试COMMIT。SQLite不会自动重试提交。应用程序必须自己完成
5.4.1.5 Statement operations
语句子事务实现为匿名保存点,在子事务结束时释放。语句子事务级别的正常操作是读、写和提交。下面将讨论这些问题。
读取操作: 语句子事务通过包含的用户事务读取页面。所有规则都遵循与用户事务相同的规则。
写操作: 写操作包括两个部分:锁定和记录。语句子事务通过包含的用户事务获取锁。但是语句日志略有不同,它是通过使用一个单独的临时语句日志文件来处理的。(语句日志是一个任意命名的临时文件,前缀为etills_。)分页器将一些日志记录写入语句日志,一些日志记录写入主回滚日志。当子事务试图通过sqlite3PagerWrite操作使页面可写时,它执行以下两种可选操作之一:
- 如果页尚未在回滚日志中,则分页器将向回滚日志添加新的日志记录。(但是,新添加的页面不会被记录)
- 如果页不在该日志中,则分页器将向语句日志中添加新的日志记录。分页器在语句子事务时创建语句日志文件 写入文件中的第一条日志记录
分页器从不刷新语句日志,因为故障恢复从不需要这样做。如果发生系统故障或断电,主回滚日志将负责数据库恢复。您可能会注意到,当一个页面同时属于回滚日志和语句日志时。回滚日志具有最旧的页面映像。
提交操作: 语句提交非常简单。分页器删除语句日志文件,(但是,请参见下面的子小节。)
5.4.1.6设置保存点
当用户事务建立保存点时,SQLite进入保存点模式。在这种模式下,在提交语句时,SQLite不再删除语句日志。它保留日志,直到事务释放所有保存点,或者提交或中止自己。在保存点模式下,日志记录略有不同:如果一个页面是由前一个语句添加的,那么该页将再次添加到当前语句日志中。因此,语句日志可以对同一个数据库页有多个日志记录。
5.4.1.7 Releasing savepoints
当应用程序执行释放sp命令时,SQLite会销毁相应的PagerSavepoint对象以及在sp保存点建立之后创建的对象。应用程序不能再引用这些保存点。
5.4.2 Recovery processing
大多数事务和语句子事务提交自己。但偶尔,一些事务或语句会自行终止。在极少数情况下,会出现应用程序和系统故障。无论哪种情况,SQLite都可能需要通过执行一些回滚操作来将数据库恢复到可接受的一致状态。在前两种情况下(语句和事务终止),内存中的可靠信息可能在恢复时可用。在后一种情况下(失败),数据库可能已经损坏,并且内存中没有任何信息。存在一种中间情况,即事务恢复到以前的保存点。我将在以下四个小节中讨论这四种情况。
5.4.2.1 Transaction abort
在SQLite中,从abort中恢复非常简单。分页器可能需要也可能不需要从数据库文件中删除事务的效果。如果事务在数据库上只持有一个RESERVED或PENDING锁,则可以保证文件不被修改;分页器将完成日志文件,并从页面缓存中丢弃所有脏页。否则,事务将持有数据库文件上的排他锁,并且事务可能已将某些页面写回数据库文件,分页器将执行以下回滚操作。
分页器从回滚日志文件中逐条读取日志记录,并从这些记录中恢复页面映像。(您可能还记得,事务最多记录一个数据库页一次,日志记录存储该页之前的映像。)因此,在日志扫描结束时,数据库将恢复到事务开始之前的原始状态。如果事务扩展了数据库,则分页器将数据库截断为原始大小。然后,它(分页器)首先刷新数据库文件,然后完成回滚日志文件。它释放排他锁,并清除页面缓存。
5.4.2.2 Statement subtransaction abort
如第5.4.1.5节所述。语句子事务可以同时向回滚日志和语句日志添加日志记录。SOLite需要回滚语句日志中的所有日志记录,以及回滚日志中的一些日志记录。如前所述,每个语句都被视为一个匿名保存点。因此,语句中止相当于恢复匿名保存点。我将在下一小节中讨论它。
5.4.2.3 Reverting to savepoints
如第145页5.4.1.6节所述,当处于保存点模式时,事务不会删除语句日志。当事务执行回滚到sp命令时,SQLite还播放sp点建立后生成的语句日志中的日志记录。PagerSavepoint对象对应的三个成员变量ioffset、iHdrOffset和iSubRec起着至关重要的作用。它首先播放主回滚日志中的所有日志记录,从iOffset处开始,直到日志文件的末尾。然后,它播放从iSubRec开始的语句日志中的所有日志记录,直到文件末尾用于恢复保存点。但是,在前一种情况下,如果iHdrOffset不为零,则从回滚日志播放日志记录分两步完成:(1)从ioffset到iHdrOfset,(2)所有后续的日志段。在恢复过程中,分页器会记录回滚哪些页面,并确保不会对某个页面进行多次回滚。寻呼机。dbsize被恢复为保存点(PagerSavepoint.nOrig)开始时的大小。对于恢复整个事务,只使用回滚日志。SQLite销毁sp保存点之后创建的所有PagerSavepoint对象,但不包括它的保存点。应用程序无法再访问这些保存点。
5.4.2.4 Recovery from failure
当没有应用程序更新数据库,但存在回滚日志文件时,这意味着之前的事务可能已经失败,SQLite可能需要从失败事务的影响中恢复数据库,然后才能将数据库用于正常业务。如果相应的数据库文件被解锁或共享锁定,则回滚日志文件称为热文件。当一个写事务正在完成时,一个失败阻止了完成,日志就会变热。但是,如果回滚日志是由多数据库事务产生的,并且没有主日志文件,则回滚日志不热;这意味着在发生故障时提交事务。热日志意味着需要回滚以恢复数据库的一致性。
热度测定: 有两种情况。(1)不涉及主日志,即回滚日志文件中没有主日志记录。如果回滚日志存在并且有效(即,日志头格式良好且不为零),并且数据库文件没有预留强锁并且数据库不是空的(size = 0),则回滚日志是热的(您可能还记得带有保留锁的事务创建回滚日志文件;(2)回滚日志中出现主日志名。如果主日志存在并具有对该回滚日志的引用,并且对应的数据库文件上没有保留或更强的锁,则回滚日志为热点。
在大多数dbms中,当数据库启动时,事务管理器会立即启动对数据库的恢复操作,而SOLite执行延迟恢复。如5.4.1.1节所述,当第一次读取数据库中的(任何)页时,只有当回滚日志是热的时候,分页器才会经过恢复逻辑并恢复数据库
警告!: 如果当前应用程序对数据库文件只有读权限,并且对文件和包含目录没有每任务写权限,则恢复失败,应用程序将从SQLite库获得一个意想不到的错误代码。
当分页器第一次想要从数据库文件中读取数据时,它在实际从文件中读取页面之前执行以下恢复步骤序列。
-
它获取数据库文件上的共享锁。(如果它不能获得锁,它将向应用程序返回SQLITE_BUSY错误代码。
-
它检查数据库是否有热日志。如果数据库没有热日志。恢复操作完成。如果存在热日志,则按照以下步骤回滚日志。
-
它获取数据库文件上的EXCLUSIVE锁。(寻呼机没有获得re - serve锁,因为这会使其他寻呼机认为日志不再是热的,他们会读取数据库。它需要一个排他锁,因为作为恢复工作的一部分,它即将写入数据库文件。如果它未能获得锁,则意味着另一个分页器已经在尝试回滚,在这种情况下,它释放所有锁并将SQLITE_BUSY返回给应用程序。
-
它从回滚日志文件中读取所有日志记录并撤消它们。此步骤将数据库恢复到崩溃事务开始之前的原始状态,因此,数据库现在处于一致状态。如果需要,它将数据库文件截断到失败事务开始时的大小。
-
它刷新数据库文件。这样可以在发生另一次电源故障或崩溃时保护数据库的完整性。
-
它结束(即删除、截断或使回滚日志文件无效)。
-
它删除主日志文件,如果这样做是安全的。(这一步是可选的。下面讨论)。
-
它将锁强度降低为SHARED。(这是因为分页器在sqlite3PagerGet函数中执行恢复)。
在上述算法成功终止后,数据库文件被保证已恢复到失败事务开始时的状态,现在可以安全地从文件中读取。
过期主日志: 如果不再有单独的回滚日志引用该主日志,则认为该主日志已过期。分页器首先读取主日志并获取所有回滚日志的名称。然后,它单独检查每个回滚日志,如果它们中的任何一个存在并指向主日志,则主日志没有过期。如果所有回滚日志都丢失,或者它们引用其他主日志,或者根本没有引用主日志,则主日志失效,分页器将删除主日志。不要求删除陈旧的主日志。这样做的唯一原因是释放它们占用的磁盘空间。
5.4.3 Other management issues
本小节简要讨论其他与数据库相关的问题。
5.4.3.1 Checkpoint
为了减少故障恢复时的工作负载,大多数dbms会定期在数据库上执行检查点。您可能还记得,SQLite一次最多只能在一个数据库文件上有一个写事务,日志文件只包含来自该事务的日志记录,因此SQLite删除(或截断或无效)日志 文件,当事务完成时。不会永远累积日志,不需要执行检查点,也没有嵌入任何检查点逻辑。当事务提交时,SQLite确保所有来自事务的更新在日志文件结束(即删除,截断或无效)之前都在数据库文件中。(在SQLite 3.7.0版本中,SQLite开发团队引入了WAL日志记录功能。在这种日志模式下,执行检查点。我在249页的10.17节中讨论了这个日志。)
5.4.3.2 Space constraint(约束)
在一些dbms中,最麻烦的问题是日志空间不足。也就是说,文件系统没有足够的空间来增加日志文件以写入新的日志记录。在某些dbms中,中止事务会在撤消某些更新的同时产生(补偿)日志记录,从而使情况进一步恶化。缺少日志空间可能会在这些系统中造成事务中止和系统重启的问题。SQLite没有日志空间问题,因为终止事务不会产生任何新的日志记录。系统重新启动可能是一个问题,但只有在以下极端情况下才会出现:事务缩小了数据库文件,而释放的空间已经被本机文件系统分配给了其他用途。在这种情况下,恢复将失败,因为SQLite无法将数据库恢复到原来的大小,并且数据库将停止运行,直到数据库文件恢复到原来的大小所需的可用空间。
还有另一个相关的问题:没有空间让数据库文件增长。在这种情况下,分页器将SQLITE_FULL错误代码返回给可能中止事务的应用程序。所以这在SQLite中也不会造成问题。
Summary
这一章详细介绍了最重要的模块,分页器直接访问数据库和日志文件,管理数据库文件上的SQLite锁获取和释放。(SQLite中没有其他模块可以绕过分页模块直接访问这些资源。)总的来说,它实现了ACID属性。
分页器使用进程地址空间中的少量空间(实际上是在进程堆空间中)来保存部分数据库文件。这个空间在SQLite世界中被称为页缓存。这个空间是分槽的,每个槽可以精确地保存一个数据库页和一些控制信息。页面缓存抽象简化了树模块对数据库文件的访问,而不管它访问的是哪种类型的数据库。
页面缓存管理非常灵活。缓存方案是一个可插拔模块,用户可以提供他们自己的缓存模块,尽管SQLite提供了一个默认的缓存模块。它使用可扩展/可收缩哈希数组将缓存槽组织到桶中。使用页码作为搜索关键字,SQLite使用一种LRU缓存替换方案。它维护一个未固定页面队列,其中最近访问次数最少的页面位于标题端。被害人可能不是头部元素。SQLite尝试找到第一个不会导致日志刷新的槽位。如果发现该槽位,则使用该槽位进行更换。否则,更换头槽。
本章还描述了实现ACID属性的各种事务处理相关(内部)步骤。内部处理分为正常处理和恢复处理两部分。正常的处理包括读取页面、写入页面、刷新页面缓存以及提交事务或子事务。在用户事务中。SQLite在一个匿名保存点的抽象中执行每个SOL语句。恢复处理,包括子事务或事务中止、保存点恢复和处理系统故障。
Chapter 6 The Tree Module
读完这一章,你应该能够解释/描述:
- SQLite如何将表组织成单独的B+树
- 如何在数据库文件中构造树,元和组分别插入和删除树
- B和B+树结构和操作它们的算法
- 内部页、页和溢出页的结构
Chapter synopsis 数据库文件中的数据可以以多种方式组织,例如条目顺序、相对顺序、散列、ker顺序。SQLite使用B+树来组织表的内容,使用B-树来组织表的索引。它们是关键序列数据,结构。本章讨论B/B+树的实现,通常用于在其他dbms的外部(基于磁盘的)数据库上实现有序索引。在SQLite中实现的算法是Donald E. Knuthin在他的著名著作《计算机编程的艺术》第3卷中提出的:“排序和搜索”。
6.1 Preview
在前一章中,我讨论了分页模块如何在本机面向字节的文件之上实现面向页面的文件抽象。在本章中,我将讨论tree模块如何在面向页面的文件之上实现面向元组(也就是行)的文件抽象。元组的最终用户(也就是数据库文件)是VM模块,它通过树模块提供的接口访问元组。VM将数据库视为(键排序的)面向元组的文件。
本章介绍了SQLite的元组管理方案。您可能还记得,每个关系都是一组元组。数据库中所有关系的元组都存储在同一个数据库中。虚拟机必须有一种方法来集群和组织一个关系的元组,并将它们与其他关系的元组分开。此外,VM必须能够有效地存储、检索和操作元组。树模块帮助VM这样做;tree模块负责元组到页面的转换。
关系的元组可以以多种方式组织,例如条目顺序、相对顺序。哈希,键序列。每个组织都有自己的机制,可以根据(关系的)某些属性值在关系中插入新的元组,以及从关系中检索和删除元组。在VM看来,它是一种可内容寻址的基于元组的存储组织。不同的关系可以有不同的元组组织。SQLite使用一个B+树来组织一个关系的所有元组,不同的关系使用不同的元组。它将索引的内容视为一种关联,并将内容存储在b树中,并将不同的索引存储在不同的b树中。它不使用任何其他元组组织技术。因此,SQLite数据库是B树和B+树的集合。所有这些树都存储在单个文件中,它们分布在数据库页面中,并且可以穿插。但是,没有数据库页面存储来自两个或多个关系或索引的元组。tree模块的职责是组织树的页面,以便有效地存储和检索元组。模块查看面向页面的文件,并将其转换为面向树的文件(元组)。
B-树和B+树是类似的键序列数据结构。在本章的其余部分中,我主要限制自己使用B+树。出于一般目的,我将使用B+树。tree模块实现了从树中读取、插入和删除单个元组的原语,当然还有创建和删除树的原语。就元组的内部结构而言,它是一个被动模块,它将元组视为可变长度的字节字符串。关系名称或索引名称到树(实际上是树的根)的映射信息保存在sqlite_master(或sqlite_temp master)目录中,该目录存储在预定的B+树中。
6.2 The Tree Interface Functions
tree模块实现了一组接口函数(由VM模块使用)。下面将简要讨论一些重要的函数,还有更多这样的函数,它们严格地属于SQLite内部,SQLite应用程序开发人员不能在他们的应用程序中使用它们。它们在btree.c源文件中定义。所有函数名都以sqlite3Btree作为前缀。
- sqlite3BtreeDpen:这个函数打开到数据库文件的连接,而不是数据库中的单个树或B+树。它最终调用sqlite3PagerOpen分页函数来打开文件。通过这样做,它在应用程序和文件之间建立了一个新的连接。它创建并返回一个指向Btree类型对象(参见第6.5.1.1节)的指针,该指针被VM用作其他树接口函数的句柄。
- sqlitebtreclose:这个函数关闭先前打开的数据库连接并销毁Btree对象的历史。它最终调用sqlite3PagerClose分页函数来销毁它的分页对象。但是,在此之前,它回滚所有挂起的事务,关闭并释放所有游标(请参阅此列表中的下一项),并释放分配给Btree对象的其他资源。
- sqlite3BtreeCursor:这个函数在一个特定的树上创建一个新的游标,也就是说,它打开树来读写它。(该树由其根页面标识。)游标可以是读游标,也可以是写游标,但不能两者都是。在同一棵树上可以有许多打开的游标,每个游标都是通过单独调用sqlite3BtreeCursor函数创建的。但是,读游标和写游标不能在同一棵树上共存。(您可能会注意到,SQLite有一个限制,即一个事务不能同时使用不同的游标读写同一棵树。)在创建第一个游标时,该函数获得数据库文件上的共享锁(通过它的分页器)。
- sqlite3BtreeCloseCursor:这个函数关闭先前打开的游标。当最后一个游标(可以在任何树上)关闭时,数据库文件上的共享时钟将被释放。
- sqlite3BtreeClearCursor:这个函数基本上使游标无效。
- sqlite3BtreeFirst:这个函数将光标移动到树中的第一个元素,即到树的最左边的后代节点。
- sqlite3BtreeLast:该函数将光标移动到树中的最后一个元素,即到树的最右边的后代节点。
- sqlite3BtreeNext: This function moves a cursor to the next element after the one it is currently pointing to.
- sqlite3BtreePrevious: This function moves a cursor to the previous element before the one it is currently pointing to.
- sqlite3BtreeMovetoUnpacked:这个函数将光标移动到与作为参数传递的键值匹配的元素上。如果没有找到精确匹配,则游标总是指向叶子页,如果存在该条目,则叶子页将保存该条目,游标可能指向键之前或之后的条目。
- sqlite3BtreeBeginTrans:这个函数在数据库文件上启动一个新的事务。如果在参数中指明,则启动写事务;否则,它将启动一个读事务。调用者可以请求排他性事务,这意味着不允许其他进程或线程访问数据库。
- sqlite3BtreeCommitPhaseOne:这个函数执行SQLite两阶段提交的第一阶段。它为提交事务做了所有的事情,比如刷新回滚日志、刷新数据库文件,但它不完成回滚日志,也不释放锁。
- salite3BtreeCommitPhaseTwo:该函数实际提交数据库文件上当前正在进行的事务。它完成回滚日志文件,并将排他锁降级为数据库文件上的共享锁,如果没有活动游标,它还释放共享锁。
- sqlite3BtreeRollback:这个函数回滚当前的写事务。当前写事务访问的所有游标都将被此函数失效。以后任何使用这些游标的尝试都会导致错误。(该函数将数据库文件上的排他锁降级为共享锁,如果没有活动游标,它也会释放共享锁。)
- salite3BtreeBeginStmt:该函数启动语句子事务,(VM模块必须在启动子事务之前启动一个事务)。一次只能有一个子事务处于活动状态。如果另一个子事务已经处于活动状态,则尝试启动新的子事务是错误的。每个语句子事务都是一个匿名保存点
- sqlite3BtreeCreateTable:这个函数在数据库文件中创建一个新的空树,树的类型(B或B+)由输入参数决定。在SQLite 3.7.8版本中,只允许两个可选值:BTREE INTKEY(用于SQL表,新的B+树具有整数键和任意大小的数据)或BTREE BLOBKEY(用于SQL索引,新的B+树具有任意大小的键和没有数据)。在此函数调用时,数据库上必须没有打开的游标;否则返回错误码。
- sqlite3btreeddroptable:这个函数销毁B-或B+树,并释放它的所有页面。但是,它永远不会释放驻留在Page 1的根节点
- salite3BtreeClearTable:该函数从现有的B树或B树中删除所有数据,但保留树本身。它释放所有相应的树页面和溢出页面,除了根页面。从这个函数返回时,树的根页是空的,就像刚刚创建树一样。
- sqlite3BtreeDelete:这个函数删除游标当前指向的条目。删除后,光标将指向一个随机位置。
- sqlite3BtreeInsert:这个函数通过游标在B-或B+树的适当位置插入一个新元素。密钥由一对(pKey, nKey)给出,数据由一对(pData, nData)给出。对于B+树(即SQL表),只使用密钥对的nKey值:忽略pKey。对于b树(即SQL索引),pData和nData都被忽略。游标仅用于定义条目应该插入到哪个表中。在插入之后,光标将指向一个随机位置
- sqlite3BtreeKeySize:这个函数返回给定游标所指向的条目键的字节数。如果游标没有指向有效的条目,则返回0
- sqlite3BtreeKey:这个函数返回给定游标所指向的条目的键 来
- sqlite3BtreeDataSize:这个函数返回给定游标所指向的条目数据中的字节数。如果游标没有指向有效的条目,则返回0
- sqlite3BtreeData:这个函数返回给定游标所指向的条目的数据。
- sqlite3BtreeGetMeta:这个函数返回数据库设置参数的值。元数据。这个函数必须在读或写事务中调用。
6.3 B+-tree Structure
B-tree,其中“B”代表“balanced”,是迄今为止我所知道的许多基于外部存储的dbms中最重要的索引结构。它是一种按键排序的方式来组织类似数据记录的集合。(排序顺序是键的总顺序。)同一数据库中的不同b树可以具有不同的排序顺序。B-tree是一种特殊的高度平衡的n层树,所有的叶节点都在同一层。条目[-1]和搜索信息(即…键值)存储在内部节点和叶节点中,B-tree在整个树操作范围(即插入,删除)中提供了最佳性能。搜索。然后搜索下一步。
[-1] 为了避免混淆,我在这里使用术语“条目”来表示元组或数据项。条目由键和其他可选数据组成。
B+树是B树的一种变体,其中所有条目都位于叶节点中。条目是(键值,数据值)对;它们是按键值排序的。内部节点只包含搜索信息(键值)和子指针。内部节点中的键按排序顺序存储,用于将搜索定向到适当的子节点。
对于任何一种树,内部节点都可以在预设范围内拥有可变数量的子指针。对于特定的实现,内部节点可以拥有的子指针数量有上限和下限。下界通常等于或大于上界的一半。根节点可能违反此规则;它可以有任意数量的子指针(从0到上限)。所有叶节点都在同一最低层。在一些实现中,它们被链接在一个有序的链中,根节点总是B+树的内部节点。
对于给定的上限n+ 1,n > 1,在n+ 1元的B+树中,每个内部节点最多包含n个键和最多n+ 1个子指针。键和子指针的逻辑组织如图6.1所示。对于任何内部节点,以下条件成立:

- Ptr(0)所指向的子树最左边的所有键值小于或等于Key(0);
- Ptr(1)所指向的子树上的所有键值大于Key(0)且小于或等于Key(1),以此类推;
- Ptr(n)所指向的子树最右边的所有键值都大于Key(n -1)。
内部节点中的键值仅用于搜索路由。查找给定键值的特定条目需要遍历O(log m)个节点,其中m是树中数据项的总数。
6.3.1 Operations on B+-tree
在接下来的小节中,我将介绍四种操作,即搜索、下一步搜索、插入和删除。我将在下面简要讨论它们;关于它们的详细信息可以在任何关于数据结构和算法的教科书中找到,尤其是Knuth[14]的那本。你可能会注意到,在SQLite中,所有的B+树都是唯一的键值,不重复;它也不会将叶节点连接在一起。在下面的小节中,我将使用图6.2中的B+树样本作为参考示例。我将树的每个节点关联到一个名称,该名称打印在节点的顶部:NO-N8。这些名称仅用于以下子小节中的参考目的。
6.3.1.1 Search
考虑一个键值k的搜索操作。搜索从根节点开始,到叶节点结束。根节点总是一个内部节点。假设有n个键,Key(0),…,键(n -1)和n + 1指针Ptr(0),…, Ptr(n),在节点上。键和指针的逻辑结构如图6.1所示。若k> Key(n-1),则在以Ptr(n)为根的子树继续搜索;若存在j=0,…,n-1,使得Key(j-1)<k< Key(j),则在以Ptr(j)为根的子树继续搜索。(我假设这里Key(-1)< k,对于任意k)如果子树的根是内部节点,则对内部节点应用相同的过程。最终,搜索到达一个叶节点。在叶节点中搜索键值为k的条目是否存在。solite在实体上使用标准的二进制搜索技术,在单个叶节点上进行本地搜索。
假设您在图6.2的参考B+树中搜索93。从根节点(N0)开始搜索,取左指针,因为93 < 100,即从节点N1重新开始搜索。搜索从最右边的指针开始,因为93 bb0 90,搜索从节点N5重新开始。n5是叶节点,搜索在这里成功结束。如果你在树中搜索94,搜索将在N5处失败而终止。
6.3.1.2下一步搜索
这个操作在SQLite中比较复杂,因为它不把叶子节点链接在一起。假设之前的搜索在叶节点N的索引i处停止。如果i不是该节点上的最后一个索引。返回n中的第i+ 1个条目,否则,我们需要移动到另一个叶节点,该节点在逻辑上是n的下一个叶节点。移动是一个简单的树遍历逻辑。如果N是树的最后一个节点。那么树中就没有要搜索的条目了,它返回EOT(树尾)。假设N不是树的最右边后代结点。我们从结点N开始追父结点,直到到达结点N’它不是父结点最右边的子结点。假设N是P,它的父结点P的子结点,搜索移动到P的最左边的子代结点(a叶节点),P的子树+1,它返回该叶节点的第一个条目。
假设在最后一小节的示例示例中,前面的搜索在节点N5的键93处终止。下一个搜索从N5开始。在N5处没有大于93的条目,并且节点是其父节点(N1)的最右边的子节点。N1不是其父节点(NO)最右边的子节点。所以,搜索移动到N0的最右边子树的最左边的后代。这是。在N6处重新开始搜索,并返回N6中的第一个条目(110)。如果我们再次调用search-next,它将返回N6中的下一个条目(120)。
6.3.1.3插入
假设我们想在B+树中插入一个键k(和数据)。首先,我们调用常规搜索来查找k可能驻留的叶子,如果k已经在那里,我们拒绝插入操作,因为我们有一个唯一的B+树。假设k不在这里。如果叶节点上有空间,我们将键和数据插入到所需排序位置的节点上。如果叶节点上没有空间,我们将把驻留在叶节点上的现有条目和正在插入的新条目分成相等的两部分:下半部和上半部。(上半部分的键严格大于下半部分的键。)我们分配一个新的叶节点,并将上半部分移动到新节点中。现在我们需要将新节点添加到树中。我们加上一对(K,P)其中K是分裂节点上的最大键,P是指向新节点的指针,指向被分裂的原始叶节点的父节点。如果父节点有存储新pair的空间,则将新pair存储在那里,并在此时终止插入。否则,父节点以同样的方式分裂。分割会一直传播,直到我们找到一些有足够空间容纳新对的祖先,或者根被分割。
拆分根需要格外小心,因为没有更高级别的节点可以插入拆分对。此外,B+树的根页永远不会被重新定位。根分裂通常采用如下方式:设N为根节点。首先分配两个节点,比如L和R。将N的下半部分移到L中,上半部分移到R中,此时N为空。在N中加上(L, K, R),其中K是L中的最大键,页N仍然是根。请注意,树的深度增加了1,但新树保持高度平衡,没有违反任何B+树的属性
假设我们在图6.2的B+树中插入200。我们首先搜索可以插入条目的叶节点。搜索在节点N8处终止。节点已满。因此,我们分配一个新节点,比如N9,并将180从N8转移到N9,并在N9中插入200。然后,我们将(170,N9)插入到有空间存储对的N2中。最终配置如图6.3所示。
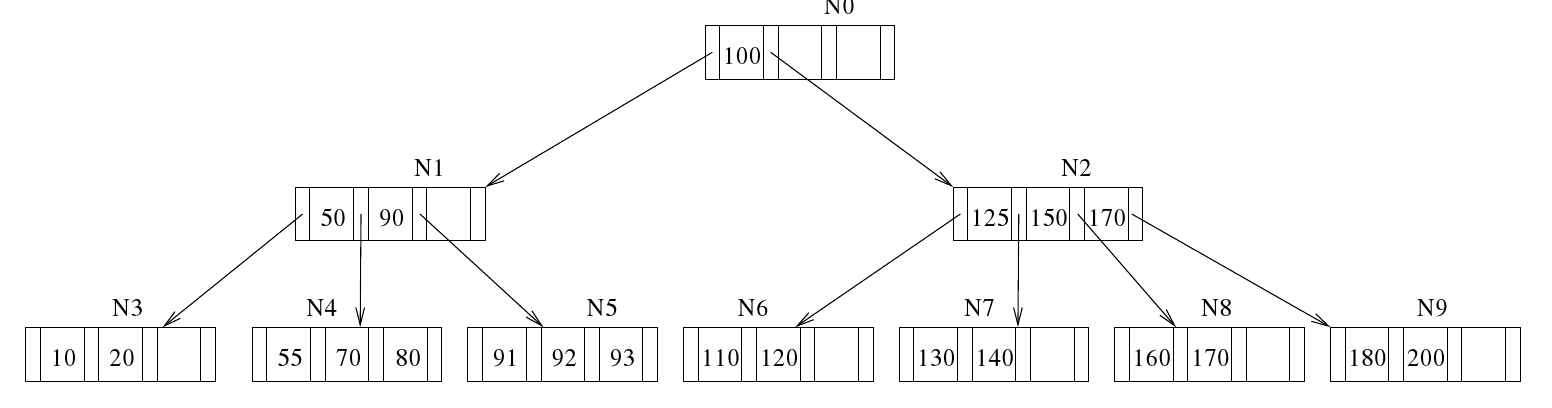
6.3.1.4 Delete
假设我们要从B+树中删除键值为k的项。首先,我们调用常规搜索例程来查找k可能所在的叶节点。如果在叶子上没有找到键值,则删除操作立即终止。假设键值在那里,i是对应条目的索引。所有索引大于i的项都下移一个元素。如果剩余条目的数量不低于页面占用的下限,则删除将立即终止。假设叶占用率低于下界。我们需要从这个节点开始自下而上地重组树(通过合并兄弟节点)。我们将进行以下工作,直到重组过程结束。
假设节点N正在重构过程中。我们重新分配N上的条目,最多两个N的兄弟节点,这样所有节点都有相同数量的空闲空间。通常在N的两边各有一个兄弟结点用于平衡动作,尽管只有当N是父结点的最左子结点或最右子结点时,兄弟结点才会来自其中一边。如果N的兄弟节点少于两个(只有当N是根页面或根页面的子页面时才会发生这种情况),那么所有可用的兄弟节点都将参与重构过程。
为了保持节点(几乎)满,N的兄弟节点的数量可能会减少一个或两个。根节点是特殊的,允许(几乎)为空。如果N是根节点,那么树的深度可能会根据需要减少1,以防止根节点过满。在平衡N的兄弟节点的过程中,N的父节点可能会变得不够满。如果发生这种情况,则在父节点上递归地调用重构,直到我们重构根节点。
6.3.2 B+tree in SQLite
通过分配根页面来创建树,根页面不会重新定位。每棵树都由它的根页码标识。该编号存储在主编目表中,其根始终位于第1页。
SQLite将树节点(包括内部节点和叶子节点)存储在单独的页面中,一个页面存储一个节点(见图6.4)。因此,这些页分别称为内页和叶页。实际数据、条目部分驻留在叶页上,部分驻留在溢出页上。tree模块可能无法理解数据或键的内部结构。它以原始字节串及其大小存储数据和键。对于每个节点,任何条目的键和数据被组合在一起形成有效负载。固定的预设负载量直接存储在页面上。该模块试图将尽可能多的有效载荷放在单个页上。如果有效负载大于该量,则模块将剩余字节溢出到一个或多个溢出页中:多余的有效负载依次存储在溢出页的单个链接列表中。内部页面(虽然没有在图中显示)也可以有溢出页。
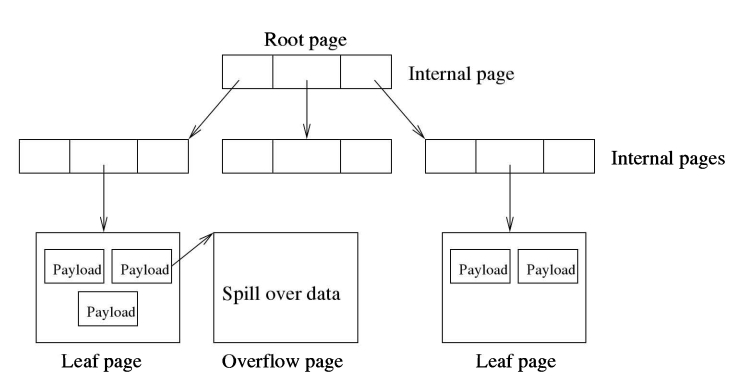
6.4 Page Structure
您可能还记得,每个数据库文件都被划分为固定大小的页面。树模块管理所有这些页面。每个页要么是一个树页(内部页、叶子页或溢出页),要么是一个自由页。(例外是锁字节和指针映射页。)第89页上的图3.5描述了空闲页面是如何组织到单个trunk列表中的。在本节中,我将介绍内部页、页和溢出页的结构。
除了数据库文件的第一页(page 1)始终是包含根节点的B+树内部页外,任何数据库页都可以用于任何目的。但是,第一页的前100个字节包含一个特殊的头(称为“文件头”),它描述了flex的属性。图3.4在第86页展示了文件头的结构。页面上的剩余空间用于B+树的根节点。所有其他数据库页都被完全用于存储单个树节点或溢出内容
6.4.1 Tree page structure
每个内部/叶页的逻辑内容被划分为所谓的单元。例如,对于B+树内部节点,单元格由键值和键前面的子指针组成;对于叶节点,单元格包含(一部分)有效负载,没有子指针。我将在163页的6.4.1.3节中讨论细胞。单元是树页面上空间分配和回收的单位。为了对每个内页或页的空间进行管理,将其分为四个部分,如图6.5所示:
- 页眉,
- 单元格内容区,
- 单元格指针数组,以及
- 未分配的空间。
您可能还记得Page 1也有一个位于页头之前的100字节的文件头。单元格指针数组和单元格内容区彼此增长(通过中间未分配空间),就像两个堆栈彼此相对放置一样。单元格指针数组充当页面重目录,帮助将逻辑单元格顺序映射到它们在单元格内容区的物理单元格存储。
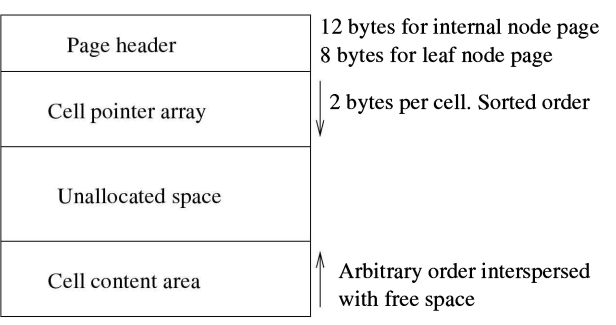
6.4.1.1 Structure of page header
页头只包含该页的管理信息,页头总是存储在页的开头(低地址)页1是个例外:前100个字节包含文件头。页眉的结构如图6.6所示。前两列以字节为单位;多字节整数以大端字节格式存储。偏移量0处的标记定义了页面的格式(也就是树页面的类型)。有四种可能性:(1)表B+树内部页,(2)表B+树叶子页,(3)索引B-树内部页,(4)索引B-树叶子页。对于内部页,页头也包含偏移量为8的最右边的子指针。标题的其他组件将在下一小节中解释

6.4.1.2 Structure of storage area
单元存储在页面的最末尾(高地址),它们向页面的开头生长。单元格指针数组从页标头后的第一个字节开始,它包含零个或多个单元格指针。见图6.7。数组中的元素数存储在页头偏移量3处(见图6.6)。每个单元格指针都是一个2字节的整数,表示单元格内容区域内到实际单元格的偏移量(从页面开始)。单元格指针按排序顺序存储(按对应的键值),即使单元格可能是无序存储的。左边项的键值比右边项的键值小。单元格不一定是连续的或按顺序排列的。SOLite努力在最后一个单元格指针之后保持空闲空间,以便可以轻松添加新单元格,而不必对页面进行碎片整理。
由于在页面上随机插入和删除单元格,因此页面可能会散布单元格和空闲空间(在单元格内容区域内)。单元格内容区域内未使用的空间被收集到一个自由块的单链表中。列表中的块按其地址升序排列。指向列表的头指针(一个2字节的集合)起源于偏移量1的页头(见图6.6)。每个空闲块的大小至少为4字节。每个空闲块的前4个字节存储控制信息:前2个字节是指向下一个空闲块的指针(0值表示没有下一个空闲块),另外2个字节是这个空闲块的大小(包括leader)。由于空闲块的大小必须至少为4字节,因此单元格内容区域中任何少于3个未使用字节的组(称为片段)都不能存在于空闲块链上。所有片段的累积大小记录在页头偏移量7处(见图6.6)(大小最多可为255)。在达到最大值之前,SQLite对页面进行碎片整理。)单元格内容区域的第一个字节记录在页头偏移量5处(见图6.6):如果该值为0(它被视为偏移量65,536)。该值充当单元格内容区域和未分配空间之间的边界。
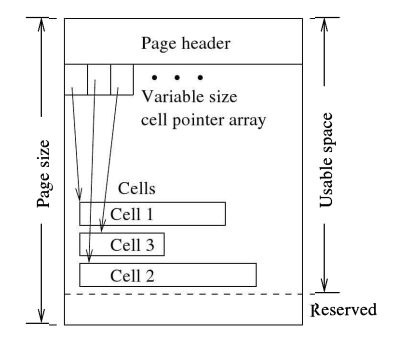
6.4.1.3 Structure of a cell
cell是可变长度的字节字符串,cell存储(一部分)单个负载,它是键和可选数据的组合。单元格的结构在图6.8的表格中给出。size列的单位是字节。size列中的var条目是一个可变长度的整数,用1到9个字节表示:它将被称为变体

对于内部页,每个单元格包含一个4字节的子指针;对于叶页,单元格没有子指针。接下来是数据图像中的字节数和天空图像中的字节数。(内部表树页面上不存在数据和键图像,键长度字节存储的是整型键值。索引树不存在数据映像。)因此(1)细胞在桌子上左子树的内部节点有一个4字节的页码和rowid yalue变体:(2)细胞atable树的叶子:节点有一个变种,总长度的表行记录,rowid价值的变体,行记录的一部分,和一个4字节溢出页码(3)细胞索引树的内部节点上有一个4字节的左子页面数,总长度的变异的关键值,一个关键的一部分,和一个4字节溢出页码;(4)索引树叶节点上的单元格,键值的总长度的变体,键的一部分,以及4字节的溢出页码。图6.9描述了单元的格式:单元的部分(a)结构,有效载荷的部分(b)结构。有效负载中可能没有键或数据,或者两者都没有。
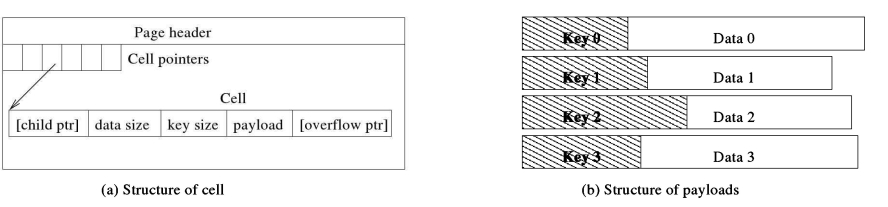
Variant Integer Number 如图6.8所示,SQLite使用可变长度的整数来表示整数大小(和整数键值)。可变长度整数是1-9字节长,其中低7位。的每个字节用于整数值计算。该整数由所有设置了8位的连续字节和第一个清除8位的字节组成。整数的最高位字节首先出现。可变长度整数的长度不超过9个字节,作为特殊情况,第9个字节的8位全部用于确定值。这种表示允许SQLite在最多9个字节内编码64位整数。它被称为霍夫曼密码,发明于1952年。比起固定长度的64位编码,SQLite更喜欢可变长度的Huffman编码,因为存储最常见的情况只需要一个或两个字节,但如果需要,最多可以编码64位信息(9个字节)
您可能还记得,SQLite对在树页面上存储有效负载有限制。即使页面上有足够的可用空间,有效负载也可能不会全部存储在页面上。最大嵌入有效负载分数是一个页面中可以被一个内部页面的单个单元消耗的总可用空间量。这个值在数据库文件头偏移量21处可用(参见第86页的图3.4)。如果内部页面上单元格的有效负载大于允许的最大大小,SQLite将额外的有效负载溢出到溢出页面链中。一旦分配了溢出页,就会将尽可能多的字节移动到溢出页中,同时不让单元格大小低于最小嵌入负载分数值(在数据库文件头偏移量22处)。最小叶有效载荷分数(在文件头偏移量23处)类似于最小嵌入有效载荷分数,不同之处在于它适用于叶页。叶子页的最大有效负载分数始终是100%,并且它没有在标题中指定
溢出计算 设p为有效负载大小,u为页面上的可用面积 Leaf table-tree page: if (p < (u - 36)), then put the entire payload on the leaf; otherwise, let M = (((u2)*32/255)-23); store min{u-35, (M+(p-M)%(u-4))} bytes on the page and rest on overflow pages. Internal table-tree page: has no payload and no overflow;
Leaf/internal index-tree page: if (p<(((u- 12)*64/255)- 22)), then put the entire payload on the page; otherwise, let M=(((u-12)*32/255)-23); store min{(M +(p- M)%(u-4)),(((u-12)*64/255)-23)bytes on the page and rest on overflow pages.
6.4.2 Overflow page structure
多个小条目可以放在一个树页面上,但是一个大条目可以跨越多个溢出页面。溢出页面(对于有效负载)形成一个单链表。每个溢出页(最后一个页除外)都被长度等于可用空间减去四个字节的数据完全填充:前四个字节存储下一个溢出页码。最后一个溢出页可能只有一个字节的数据。(页面上的剩余空间是内部碎片。)溢出页面从不存储来自两个有效负载的内容。
6.5 The Tree module Functionalities
tree模块帮助VM将所有表和索引组织到B-树和B+树中:每个表一个B+树,每个索引一个B-树。每个树由一个或多个数据库页面组成,虚拟机可以存储和检索任何树中的可变长度记录。它可以随时从树中删除记录。树模块对插入和删除进行自平衡,并自动回收和重用空闲空间。对于包含m个元组的树,该模块为VM提供0(logm)个限时查找、插入和删除记录,以及O(1)个平摊的双向遍历记录
6.5.1 Control data structures
tree模块是一个被动实体,因为它不解释存储在B-树和B+树中的记录(键和/或元组图像)。VM是记录的唯一解释器。tree模块通过分页模块访问每个数据库页面。它创建了四种数据结构(Btree、BtShared、MemPage和BtCursor)的许多内存控制对象来管理数据库页面的内存副本。这四种数据结构将在接下来的四个子小节中讨论
6.5.1.1 Btree structure
当VM通过调用sqlite3BtreeOpen函数打开数据库文件时,该函数将创建一个Btreetype对象,以便在树模块层对文件应用进一步的操作。VM使用对象作为句柄来操作文件。虚拟机需要知道的关于文件的所有信息都汇总在对象中。该对象是虚拟机的数据库连接的同义词。该对象具有以下成员变量:(1)db:指向库连接持有的指针;这个Btree对象,(2)pBt:指向一个BtShared对象的指针,通过这个BtShared对象,tree模块访问数据库文件的页面;这个对象持有一个Pager对象(参见第6.5.1.2节);(3) inTrans:表示一个事务是否正在通过这个数据库连接在数据库文件上进行;(4)许多其他控制变量,inTrans的值决定了b树对象的状态;它可以处于以下三种状态之一:TRANS_NONE, TRANS READ和TRANS WRITE,表示当前通过Btree对象在数据库文件上进行的事务类型。
6.5.1.2 BtShared structure
在树模块层,BtShared对象的实例表示单个数据库文件的状态。该对象有以下成员变量:(1)pPager:它指向一个管理数据库和日志文件的Pager对象;(3) pageSize:表示每个页面上的总字节数;(4)nTransaction:打开(读和写)事务的数量;(5)in’transaction:事务状态;(6) pSchema:指向模式缓存的指针(模式对象);db:指向当前正在使用该对象的库连接的指针;(8) pPagel:指向数据库页面1的MemPage对象的内存副本的指针;(9)互斥锁:访问同步器;(10)许多其他控制变量。当共享缓存功能被禁用时,每个BtShared对象由单个Btree对象拥有。当这个特性被启用时,一个BtShared对象可以被多个Btree对象拥有,我将在第241页的10.13节中讨论共享页面缓存
6.5.1.3 MemPage structure
如图5.8第133页所示,对于页面缓存中的每个页面图像,分页器会在页面正下方分配额外的空间。tree模块使用这个空间来存储特定于页面的控件信息。分页器在将页放入缓存时将空间初始化为零。树模块根据需要重新初始化空间。这个空间包含一个MemPage类型的对象。图6.10给出了MemPage的一些关键成员变量。这些变量是不言自明的。MemPage对象存储从原始文件页面内容解码的页面信息。parent变量指向父页的缓存内副本。这个变量允许我们从任何节点到树的根遍历树,aData指向缓存中页面副本的开始。

6.5.1.4 BtCursor structure
要对数据库中的特定树进行操作,VM必须首先通过在树上创建游标的方式(通过调用sqlite3BtreeCursor函数)“打开”树。游标(许多作者称之为扫描)是对树应用操作的抽象。游标充当指向树中特定条目的逻辑指针。对于每个打开的树,树模块创建一个BtCursor类型的对象,该对象用作从树中读取、插入或删除元组的句柄。这里的游标是在单个树上执行单个SQL语句的一种表示,BtCursor对象不能被多个数据库连接(即b树对象)共享。
图6.11给出了btcursor的一些关键成员变量。变量是自解释的。apppage是一个MemPage对象数组。这些对象包含从根目录到当前页面的所有页面;游标当前指向的条目。aiIdx[]包含这些页面上单元格指针数组的相应索引。eState是游标的状态:valid(指向一个有效的条目)、invalid(没有指向一个有效的条目)、requireseek(树被其他人修改了)或fault(一些错误,比如没有发生内存)。
虚拟机可以在同一棵树上打开多个游标。游标可以是读游标,也可以是写游标,但不能两者都是。我们只能通过读游标读单元格,但可以通过写游标读和写。(读游标的输出是按自然树顺序排序的元组。)读游标和写游标不能在同一树中共存。(读写事务不能通过两个不同的游标并发地读写同一棵树。)因此,读游标保证具有可重复读属性,读游标是树上的一种“读锁”。(这与数据库连接是否对数据库文件具有排他锁无关。)这允许读游标对树进行顺序扫描,而不必担心在扫描期间条目被插入或从树中删除。只有当VM打算在树上执行范围搜索查询时,才会打开读游标。所有其他游标都是写游标,既可以读也可以写树。
您可能会注意到,树可以有自己的键比较函数。对于同一树上的每个游标,比较函数在逻辑上必须相同。默认的比较函数是表B+树的整数比较和索引B-树的本机memcmp API
6.5.1.5 Integrated control structures
以上四种数据结构与第5章定义的数据结构之间的联系如图6.12所示。b树对象及其相关的控制结构总结了V通过该b树对象看到的一个数据库文件的当前状态。(许多Btree对象可以共享同一个BtShared对象。我在第241页的10.13节中讨论了这一点。)

6.5.2 Space management
tree模块从VM模块随机接收负载插入和删除请求。插入操作需要在树(和溢出)页中分配空间。删除操作从树(和溢出)页面中释放占用的空间。管理每个页面上的空闲空间对于有效利用分配给数据库的空间非常重要。这些将在本小节的其余部分进行讨论
6.5.2.1 Management of free pages
当从树中删除一个页面时,该页面将被添加到文件自由列表中以供以后重用。(自由列表起源于文件头偏移量32处:参见第86页的图3.4。)当树需要扩展时,从自由列表中取出一个页面并添加到树中。如果自由列表为空,则从本机文件系统获取一个页面。(从本机文件系统获取的页面总是附加在数据库文件的末尾。)
vacuum命令用于清空文件自由列表。该命令通过压缩文件来适当地收缩数据库文件,在‘autovacuum’模式下创建的数据库将在每次COMMIT时自动收缩数据库,而不是保留数据库本身的空闲页面(如果有的话),我在235页的10.8节中讨论了autovacuum特性
6.5.2.2 Management of page space
在树页面上有三个可用空间分区:
- 单元格指针数组与单元格内容区域顶部之间的空格。最高值存储在页头偏移量5处(参见第162页图6.6)。
- 单元格内容区域内的空闲块。这些块链接在一起,链接头指针存储在页头偏移量1处。这些块通过增加它们的地址来排序。
- 单元格内容区域中分散的片段。总碎片空间量存储在页头偏移量7处。
空间分配是从前两个分区开始的。在每次分配或重新分配时,相应的受影响分区都会相应地更新。空间管理器的一个职责是确保单元格指针数组和单元格内容区域不重叠,分配和释放步骤将在下面讨论。
Cell allocation 空间分配器不分配少于4字节的空间;这样的请求被四舍五入到4字节。假设一个新的请求nRequired, nRequired > = 4, bytes出现在一个页面上,而该页总共有nFree字节。nRequired > nFree表示请求失败。假设nRequired < nFree。分配器执行以下步骤来满足请求:
-
它遍历空闲块列表,看看是否有足够大的块来满足请求。这是第一次匹配搜索。如果找到一个合适的块,它将执行以下操作之一
-
如果块大小小于nRequired+ 4,则从满足请求的空闲块列表中从块开始移除该块,并将剩余空间(< 3bytes)放入片段分区中。
-
否则,它满足块底部的请求,并减少块的大小nRequired字节。
-
-
否则,没有足够大的空闲块来满足请求。如果中间未分配的分区中没有多少空间,或者碎片太多,空间分配器会首先对页面进行碎片整理。它在页面上运行压缩算法,以合并中间的整个空闲空间。在压缩过程中,它将现有的单元一个接一个地转移到页面的底部
-
它从空闲空间区域的底部分配nRequired字节,并将顶部值增加nRequired字节。
Cell deallocation(回收) 假设一个请求来释放之前由分配器分配的nfree(>= 4)字节。分配器创建一个大小为nFree字节的新空闲块,并将该块插入到空闲块列表的适当位置。然后,它尝试合并释放块附近的空闲块。如果在两个相邻的空闲块之间有一个片段,它也会将片段与块合并。如果在顶部指针上有一个空闲块,它会将该块与中间未分配分区中的空间合并,并增加top的值。
Summary
tree模块从分页模块获取服务,并实现面向元组文件系统的抽象,供V模块使用。每个表或索引都被认为是一组经过排序的元组。这些元组分别被组织成B+树或B-树。每个活动数据库页作为内部、叶子或溢出节点属于树。(锁字节和指针映射页面除外)任何页面都不能存储来自多个树的信息。
tree模块实现了树的创建和删除功能,以及树中单个元组的读取、插入和删除功能。该模块不会改变元组的内部结构,并将其视为二进制字符串。
所有树的根页面信息都存储在sglite master(或sqlite_temp_master)目录中。它是一个B+树,就像另一个表树一样。在为文件头留下前100字节后,它存储在第一个数据库页上。
SQLite中使用的B+树算法在Knuth的著名著作《计算机编程的艺术》第3卷中有描述:“排序和搜索”。内部节点存储搜索导航信息和叶节点元组。内部节点可以拥有的条目数有一个上限和一个下限。本章概述了如何在B+树上执行点查找、下一步搜索、插入和删除操作。
Chapater 7 The Virtual Machine Module
读完这一章,你应该能够解释/描述:
- 五种存储数据类型及其表示
- 已编译SQL语句的内部表示形式
- 数据如何在SQL类型和C类型之间转换
- 表和索引记录的逻辑结构
- 清单类型在编码数据值方面的优点
本章简介 本章讨论SQLite虚拟机(VM)如何解释用内部字节码编程语言编写的应用程序,VM是存储在数据库文件中的数据的最终操纵器。它支持五种基本数据类型,即NULL、整数、real、字符串和blob,以表示文件和内存中的基本数据项。用户数据和内部表示之间的转换完全由VM完成。这一章讨论了虚拟机是如何工作的,以及在将索引和表记录存储到B-树和B+树之前,它是如何格式化索引和表记录的。
7.1 Virtual Machine
后端最顶层的模块通常被称为虚拟数据库引擎,或者在SQLite术语中称为虚拟机(VM)。VM是SQLite的核心,是前端和后端之间的接口。核心信息(算术和逻辑)处理只发生在这个模块,因为就存储的信息而言,较低的模块是被动的。VM模块在面向元组的文件系统之上实现了一个新机器的抽象,并执行用SQLite内部字节码程序编写的应用程序。明的语言。这种编程语言专门用于搜索、读取和修改树中的元组。虚拟机接受字节码程序(由前端生成),并执行这些程序。(您可能还记得,字节码程序是SQLite中的预处理语句。)VM使用tree模块提供的基础结构来执行字节码程序并生成程序执行的输出。
SQLite开发团队认为,在SQLite中使用VM对库的开发和调试有很大的好处。VM在前端(解析SOL语句并生成VM应用程序的部分)和后端(执行字节码应用程序并计算结果的部分)之间提供了良好定义的粘合剂。字节码程序比解释集成数据对象的复杂网格更容易读懂。VM还帮助SQLite引擎开发人员清楚地看到引擎试图对它编译的每个SQL语句做什么
字节码执行跟踪: 对于普通人来说,读取字节码程序比解释数据结构值更容易。根据SQLite源代码的编译方式,它还具有跟踪的能力,每个VM应用程序的程序执行,打印每个字节码指令和执行演变的结果。
字节码应用程序由sqlite3_stmt类型的内存对象表示(内部称为vdbe),可以在对象上应用以下SQLite API函数,将输入值与SOL参数关联起来,执行字节码程序,并检索程序产生的输出。关于这些函数的详细信息可以在第51页的2.2.2节中找到
- sqlite3_bind_*:它们为SQL参数赋值,这些参数将成为字节码程序的输入。
- sqlite3 _step:它将字节码程序的执行推进到下一个断点,或停止点。
- sqlite3_reset:它将程序执行倒回开始,并使相同的程序准备好使用相同的有界参数值进行新的执行
- sqlite3_column_*:它们从程序产生的当前输出行逐列提取结果。
- sqlite3 finalize:它连同字节码程序一起销毁sqlite3_stmt对象
Vdbe对象的内部状态(也称为。预备声明)包括以下内容:
- a bytecode program
- names and datatypes for al result columns.
- values bound to input parameters,
- ea program counter
- an arbitrary amount of “numbered" memory cells (referred to as register locations).
- other run-time state information (such as open Btree objects, sorters, lists, sets)
虚拟机不做任何查询优化。它盲目地执行字节码程序,在这样做时,它根据需要将数据从一种格式转换为另一种格式。实时数据转换是VM的主要任务:其他一切都由它执行的字节码程序控制。本章的主要部分介绍数据转换和操作任务。在此之前,我将在下一节中概述字节码编程语言、字节码程序和程序执行逻辑
7.2 Bytecode Programming Language
SQLite定义了一种内部编程语言来准备字节码程序。该语言类似于物理机和虚拟机(如Java)使用的汇编语言:它定义字节码指令。每个字节码指令做少量的信息处理工作或进行逻辑决策。字节码程序由一个或多个字节码指令组成,在一个线性指令序列中。一个字节码指令最多可以有5个操作数,其形式为(opcode, P1, P2, P3, P4, P5),其中opcode标识一个特定的字节码操作,P1, P2, P3, P4和P5保存该操作数的操作数或包含操作数的寄存器名。P1, P2, P3操作数为32位有符号整数。在任何可能导致跳转的操作中,P2操作数始终是跳转目的地的地址。它也用于其他目的。P4操作数是一个32/64位带符号整数或64位浮点数,或指向以空结尾的字符串、blob、排序比较函数、SQL函数等的指针。P5操作数是一个无符号字符。有些操作码使用所有五个操作数,有些通常忽略一个或两个操作数,有些则忽略所有五个操作数
注意: 操作码是内部VM操作名称,它们不是SQLite接口规范的一部分。因此,它们本身或它们的操作语义可能会在不同的版本之间发生变化。SQLite开发团队不鼓励SQLite用户自己编写字节码程序。字节码编程语言严格限于内部使用。
图7.1显示了一个典型的字节码程序,它相当于这个SQL查询语句。SELECT * FROM t1。表t1有两列,分别是x和y。(您可能注意到图中最上面的一行不是程序的一部分。每隔一行是一个字节码指令。示例中有14个字节码指令。)字节码程序的执行从地址0处的指令开始,一直持续到执行了一个暂停指令或程序执行控制超出了最后一条指令
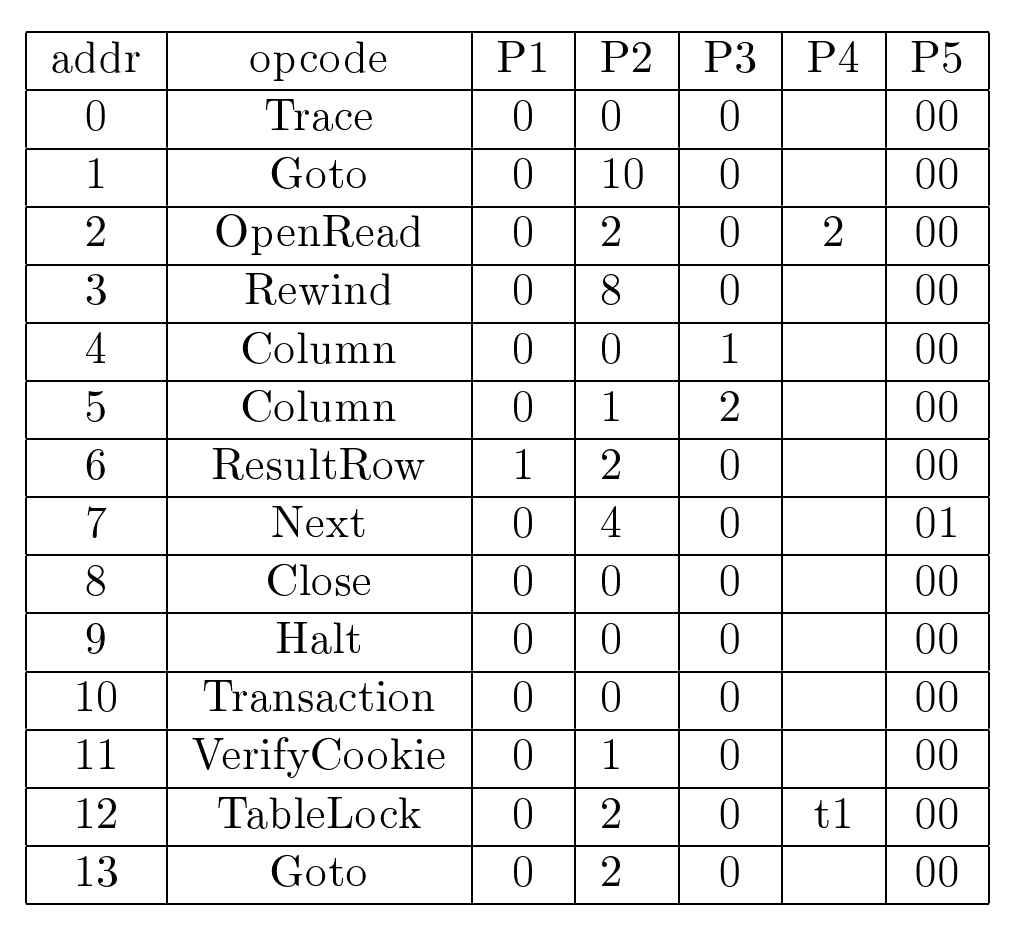
7.2.1 Bytecode instructions
目前大约有142种操作码。操作码分为五类:(1)算术和逻辑,(2)数据移动,(3)控制流,(4)B-和B+树相关,(5)专用操作码,第一类操作码包括加、减、乘、除、余、位或、位与、一补、二补、右移、左移和字符串连接。第二类操作码在存储单元之间移动值,第三类操作码包括goto、gosub、return、halt和条件分支。第4类操作码包括(i)创建、销毁和清除B/B-树,(ii)打开和关闭B/B+-树上的游标,(iii)向前和向后移动游标或移动到特定的键,(iv)在游标移动时进行分支,(v)在B/B+-树中插入、删除记录,(vi)开始提交和回滚事务,第5类操作码包括(a)获取当前未使用的行,(B)从内存单元中组合n个元素形成记录,(c)从表行中提取第i列。等。
每个字节码指令在内部由VdbeOp类型的对象表示。Lt是一个简单的对象,它有以下成员:(1)opcode表示要执行的操作,(2)p1保存第一个操作数,(3)p2保存第二个操作数,(4)p3保存第三个操作数,(5)p4保存第四个操作数,(6)p5保存第四个操作数,(7)p4type表示p4操作数的类型。p4操作数有13种类型。VM应用程序实际上是VdbeOp对象的线性数组
一些操作码(图7.1中使用的操作码)的语义如下所示。最新SOLite版本的所有操作码都记录在SQLite网页http://www.sqlite.org/opcode .html上。在SQLite源代码中,每个操作码名称都以OP为前缀,并被分配一个不同的整数字面值
-
Trace:这个操作码检查SQLite库是否开启了跟踪模式。如果打开,则在每个跟踪回调时输出P4内容(UTF8字符串)。(您可以使用salit3跟踪aptfunction启用跟踪。
-
Goto:无条件跳转到P2操作数指定的地址。VM执行的下一条指令将是程序开始处偏移量P2处的指令
-
OpenRead:打开根页由P2操作数标识的B/B+树上的只读游标(如果P5 != 0)。那么寄存器P2的内容具有根页码,而不是P2值本身。)数据库文件由P3操作数决定——主数据库的值为0,临时数据库的值为1,附加数据库的值大于1。P1(一个非负整数)操作数的值成为新游标的标识符。P4值要么是一个整数,要么是一个指向KeyInfo结构的指针。如果游标在b树(一个SOL索引)上打开,keyinfo结构定义内容和排序顺序。如果P4是一个整数值,它定义表的列数
如果在打开读游标时解锁数据库,则作为该指令执行的一部分获取共享锁。如果它不能获得共享锁,Vl将使用SOLIE BUSY错误码终止字节码的执行。
-
Rewind:重置游标P1,游标将指向表或索引中的第一个条目。即对应树中的最小条目。如果树为空并且P2 > 0,则立即跳转到P2地址,否则,跳到下面的指令
-
Column:获取游标Pl所指向的记录中的第p2列。(将游标P1指向的数据解释为使用MakeRecord指令构建的结构,参见下面的MakeRecord操作码,以获取有关数据记录格式的其他信息。)如果记录包含的值少于P2,则提取NULL;如果P4的类型是P4_MEM,那么使用P4值作为结果。返回值存储在P3寄存器中。
-
MakeRecord:将从寄存器P1开始的P2个寄存器转换为一个实体,该实体适合用作数据库表中的数据记录或索引中的键。也就是说,寄存器P1包含第一个数据项,P1+1包含第二个数据项,以此类推。
-
ResultRow: P1到P1+P2-1寄存器只包含一行结果。当应用程序执行sqlite3 _step函数并且函数执行返回SQLITE_ROW时,该指令在进程中执行。
-
下一步:移动游标Pl,使其指向树中的下一个条目(键值对)。如果没有更多的条目,则执行以下指令。否则,立即跳转到P2地址。
-
关闭先前以Pl形式打开的游标。如果游标Pl当前未打开,则此指令为no-op。
-
Halt:在关闭所有打开的游标、fifo(即RowSet对象)等后立即退出。P1是将由sqlite3_exec、sqlite3_reset或sqlite3_finalize API函数返回的结果代码。对于正常的中断,返回码是SQLITE_OK(= 0)。对于错误,返回码可以是其他值。如果P1 = 0,则P2的值决定是否回滚当前事务需要回滚,如果P2= OE_Fail则不回滚。如果P2=OE_Rollback,执行回滚。如果P2= OE _Abort,则回滚执行期间发生的所有更改,但不回滚事务。如果P4不为空,则为错误消息字符串
在每个字节码程序的最后插入一个隐含的“Halt 0 0 0 0 0”指令。因此跳过程序的最后一条指令与执行Halt是一样的。
-
Transaction:打开一个新事务。P1是启动事务的数据库文件的索引。主数据库文件的值为0,临时数据库文件的值为1,附属数据库文件的值大于1,如果P2为0,则在数据库文件上获得共享锁,如果P2不为0,则启动写事务,即在数据库上获得预留锁。如果P2是2或更大,那么在文件上也获得一个EXCLUSIVE锁。启动写事务还会创建回滚日志
-
VerifyCookie:检查全局数据库参数0的值(即模式版本cookie),并确保它等于P2值,并且本地模式解析上的生成计数器等于P3值。Pl是数据库编号,主数据库为0,临时数据库为1,附属数据库为更高的数字(您可能还记得,每当数据库模式更改时,cookie值就会更改)。 此验证操作用于检测cookie何时更改以及当前进程是否需要重新读取模式。在执行该操作码之前,要么需要启动事务,要么需要执行OpenRead/OpenWrite(至少在数据库上建立共享锁)。
-
TableLock:获取数据库P1上根页为P2的表的锁。如果P3为0,取读锁;如果P3为1,则取写锁。P4包含一个指向表名的指针。
在接下来的两个小节中,我将介绍VM的SQL插入和连接处理的执行逻辑,这将使您了解如何为SQL语句生成字节码程序
7.2.2 Insert logic
假设您有一个表T1,其中有两列:c1文本和c2整数;这个表没有索引。如果执行insert into T1 values(‘Hello, World! ‘,2000)语句,虚拟机将执行以下算法步骤。
- 在主数据库上打开一个写事务。
- 检查数据库架构版本,以确保在字节码程序生成后没有更改架构
- 在表“T1”B+树上打开一个新的写游标。
- 创建一个新的行,并创建一个表记录条目和“Hello, World!”和2000值
- 通过打开游标将记录项插入B+树。
- 关闭光标。
- 将执行状态代码返回给调用者
如果T1上有索引。VM将在步骤3中打开每个索引上的写游标,并分别在步骤4和步骤5中准备和插入索引记录。
7.2.3 Join logic
在连接操作中,将两个或多个表组合在一起以生成单个结果表。结果表由连接的表中所有可能的行组合组成。实现连接的最简单和最自然的方法是使用嵌套循环。SQLite只做循环连接,不做合并连接。FROM子句中最左边的表形成外部循环。最右边的表形成内部循环。
考虑下面的SQL选择语句:select * from t1,t2 where some-condition。假设这两个表上没有索引。select语句处理的伪代码如下所示。
-
在主数据库上打开一个读事务。
-
检查数据库架构版本,以确保在字节码程序生成后没有更改架构。
-
打开两个读游标,一个用于T1表,另一个用于T2表。
-
对于1.do中的每条记录:
对于T2.do中的每条记录:
如果WHERE’s some条件的计算结果为TRUE,
计算结果当前行的所有列。
为结果的当前行调用默认回调函数。
5.关闭两个游标。
7.2.4 Program execution
虚拟机从指令0开始执行字节码程序。直到(1)一个显式的Halt指令被处理,或者(2)程序计数器指向过去的最后一条指令(也就是隐式的Halt指令),或者(3)有一个执行错误。当VM停止时,所有分配给它的内存被释放,所有它打开的游标被关闭。如果执行因错误而停止,则终止挂起的事务,并回滚对数据库所做的更改。
VM解释器的C代码结构如图7.2所示。解释器(sqlite3VdbeExec函数接受一个Vdbe对象指针)是一个简单的for循环,它包含一个包含大量case的大型开关。每个case语句实现一个字节码指令。(在源代码中,操作码名称以0p_前缀开始。数值。to操作码的名称不是静态编号的:它们是在SOLite源代码编译时分配的,参见第77页第2.8节。在每次迭代中,VM从程序中获取下一个字节码指令,即从使用pc(都是Vdbe对象的成员)作为数组索引的数组中获取字节码指令。它解码并执行指令指定的操作。通常程序执行从一个字节码指令演变到下一个字节码指令(pc++),但是pc可以通过跳转指令改变。for循环一直持续到vmhalt指令或循环条件失败(即pc大于或等于nOp),我们说字节码程序已经终止,这是正常的终止。

sqlite3 prepare API函数返回的sqlite3_stmt结构指针实际上是一个指向Vdbe类型对象的指针。(它代表虚拟数据库引擎。)该对象包含虚拟机的完整状态。物体的一些部件如图7.3所示。aOp数组保存操作码。执行此程序所需的所有内存都位于大小为nMem的aMem数组中
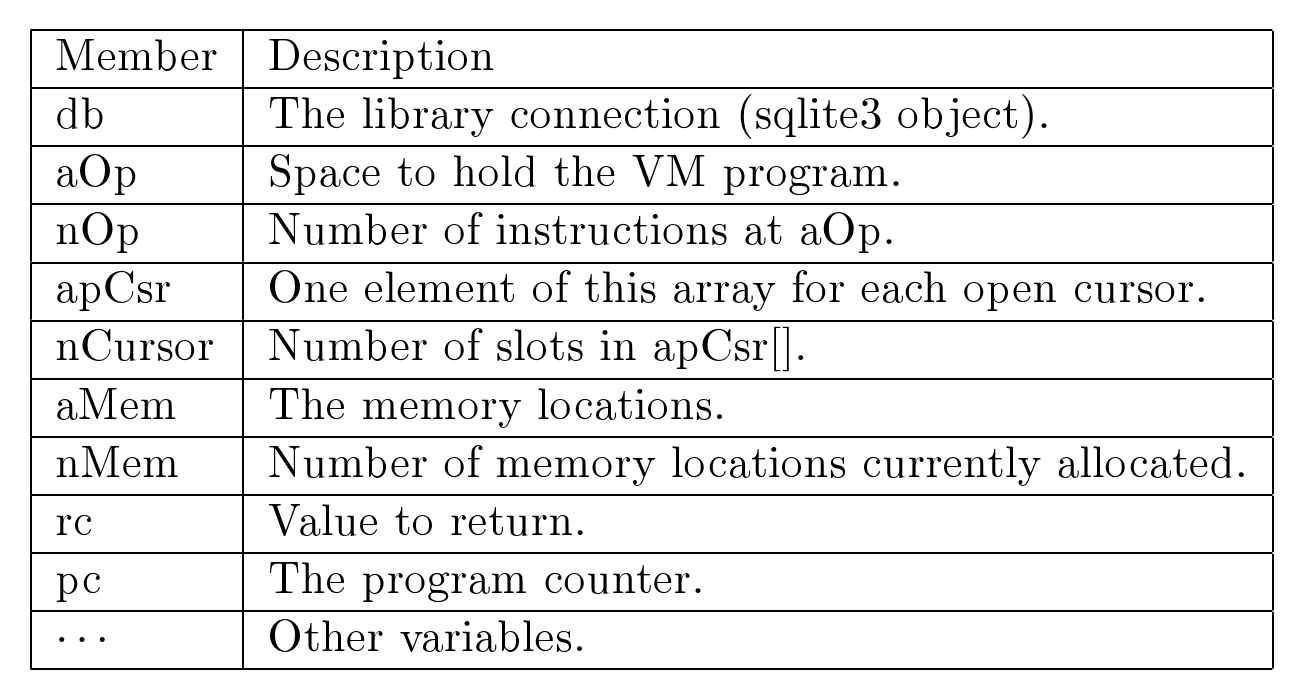
虚拟机使用游标访问数据库,(这些与树模块中使用的BtCursors不同)。它可以在数据库上有零个或多个打开游标。每个游标都是指向数据库中单个表或索引树的指针。游标可以查找具有特定键的项,也可以遍历树的所有项。VM插入新表项,从游标上的当前表项检索键/值,或者删除表项。
可以有多个游标指向同一个索引或表。所有游标都独立操作,即使它们指向相同的索引或表。VM打开的每个游标都由VdbeCursor对象表示。VdbeCursor的结构如图7.4所示。字节码程序中的指令可以创建一个新的游标(OP_OpenRead或OP_OpenWrite),从游标(OP_Column)中读取数据,将游标推进到表或索引的下一个条目(OP_Next),以及许多其他操作。当虚拟机终止字节码程序执行时,所有游标将自动关闭。

7.3 Internal Datatypes
VM使用任意数量的编号内存位置来保存所有中间结果。每个内存位置保存一个数据值。虚拟机处理的每个数据值都有以下五种数据类型之一:
- INTEGER:有符号整数;
- REAL:有符号浮点数;
- EXT:字符串值;
- BLOB:字节映像;
- NULL: SQL NULL值;
这是VM支持的仅有的五种基本数据类型。类型决定了值的物理表示方式。存储在数据库文件或内存中的每个数据、值都必须是这些类型中的一种。您可能会注意到,有些值可能一次有多个表示形式。例如,123可以同时是整数、a、浮点数和字符串。BLOB和NULL值不能有其他表示形式。您可以使用内置的SQL函数typeof来确定值的类型‘select a, typeof(a) from t1’返回列a的值及其存储类型。当salite3_step函数返回一行时,API函数sqlite3_column_type返回列值的存储类型。
在内部,VM操作几乎所有的值作为Mem对象(见图7.5)。每个Mem对象可以缓存相同值的多个表示形式(字符串、整数等)。一个值(以及相应的Mem对象)具有以下属性:每个值恰好具有上述五种存储类型中的一种。(每个Vdbe.amem数组元素都是一个Mem对象。)

7.4 Record Format
虚拟机将数据值组成记录,存放在B-树和B+树中。每条记录由一个键和可选值组成。V只负责维护键和值的内部结构。(尽管树模块可以跨叶子或内部和多个溢出页拆分单个记录,但VM将记录视为逻辑上连续的字节串。)VM对表和索引记录使用两种不同但非常相似的记录格式。
有两种格式化值键记录的方法:固定长度和可变长度。对于固定长度格式,所有记录(表或索引)使用相同数量的空间;每个单独列的大小在表/索引创建时已知。在可变长度格式中,单个列的空间可能因记录而异。SOLite使用变长记录格式的一种变体,因为它有几个优点。它导致更小的数据库文件,因为没有由于填充而浪费的空间。它还使系统运行得更快,因为在主存储器和外部存储设备(如磁盘)之间移动的字节更少。此外,可变长度记录的使用允许SQLite使用清单类型而不是静态类型。在讨论记录格式之前,我将在接下来的两个小节中讨论清单类型。
7.4.1 清单类型
每个原始数据、值,无论是存储在数据库文件中还是存储在内存中,都有一个与之关联的数据类型。这称为数据值的存储类型。大多数SQL数据库使用静态类型:数据类型与表中的每个列相关联,并且只允许将特定数据类型的值存储在该列中。这是非常刚性的,有其自身的优点和缺点。SQLite通过使用清单类型[8][-1]放宽了这一限制。在清单类型中,数据类型是值本身的属性,而不是存储值的列或变量的属性。这使您能够在任何变量或列中存储任何数据值,并且值的实际类型不会丢失。SQLite使用清单类型,其中存储类型信息作为数据值的一部分存储。它允许您将任何数据类型的任何值存储到任何列中,而不管该列声明的SQL类型是什么。(此规则有一个例外:整数型主键列只存储-2 ^63到2^63-1范围内的整数。)虽然这个特性存在争议和争议,但SQLite开发团队对此感到自豪;他们对这个功能感觉非常强烈。
[-1] 其他作者可能会使用术语而不是清单类型。注意名称混淆。
7.4.2 类型编码
存储类型被编码为整数,类型的整数值编码如表7.6所示。这种编码的美妙之处在于数据长度成为类型编码的一部分。NULL类型表示SQL NULL值。对于INTEGER类型,数据值是一个有符号整数(2的补码),存储在1,2,3中。4、6或8字节,具体取决于值的大小。对于REAL类型,数据值是存储在8字节中的浮点数,如lEEE浮点数表示标准中指定的那样。类型编码值8和9分别表示整数常量0和1,对于TEXT类型,数据值是一个文本字符串,使用数据库文件的默认编码(UTF-8、UTF-16BE或UTF-16LE)格式存储,对于后两者,本机字节顺序分别为大端序或小端序。(每个数据库文件仅以一种UTF格式存储文本数据。)对于BLOB类型,数据值是一个BLOB,与输入时完全相同。
布尔值: 布尔值true有数据类型9(整数1),false有数据类型8(整数0)。
7.4.3表记录格式
表记录(即行数据)的格式如图7.7所示。它有两个部分:标题和记录图像。标题以大小字段开始,后跟类型字段。标头后面跟着记录的各个数据项。(SQLite不会改变create语句中声明的列的顺序。建议模式设计人员将小的和经常使用的列放在记录的早期,以尽量减少遵循溢出链的需要。
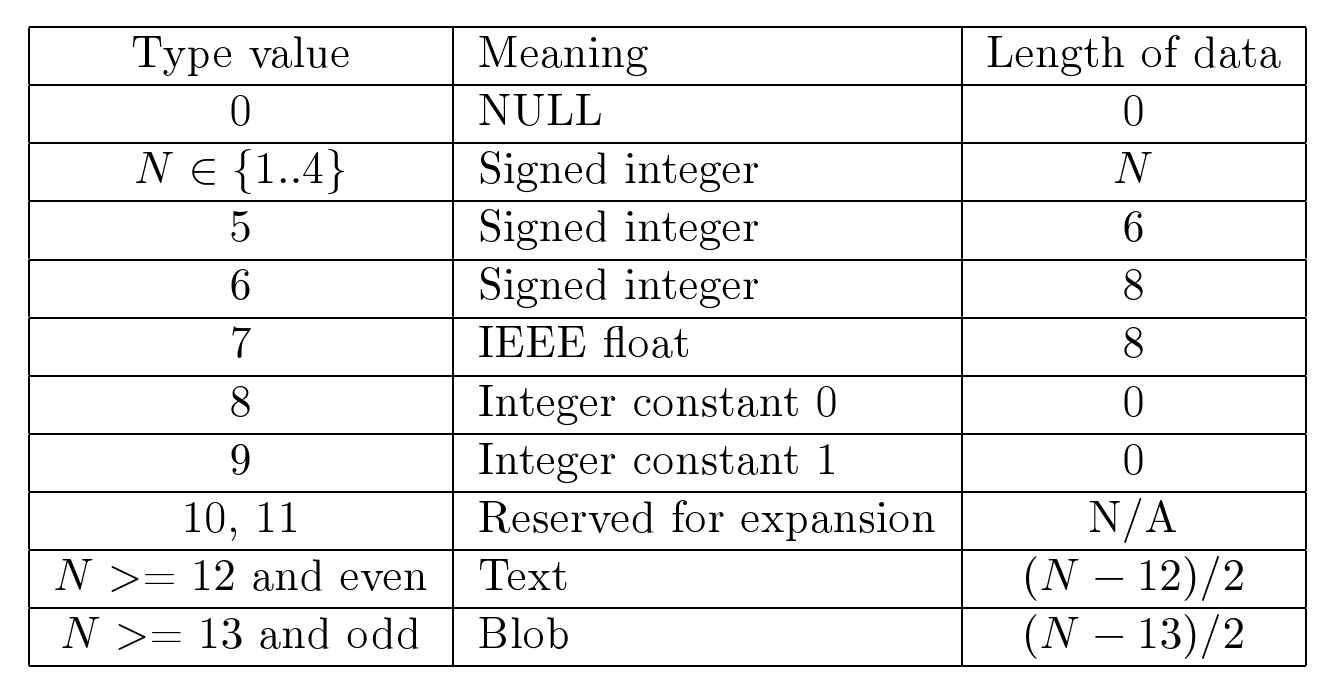

报头大小是Data 1字段之前的字节数。大小在霍夫曼码中表示为可变长度的64位整数,它包括自身占用的字节数。size有效地充当指向Data 1项的指针。在报头大小字段之后是数据类型字段,记录中的每个数据值按其在记录中出现的顺序对应一个字段。每个Type i字段都是一个可变长无符号整数(最大值为2^64),用于编码Data i的存储类型。
零长度数据: 对于类型值0、8、9、12和13,数据的长度为零,因此,数据不存储在记录中。
7.4.4 表键格式
在SQLite中,每个B+树必须有一个唯一的键,尽管根据定义是一个关系(表)。不包含相同的行,在实践中,用户可以在关系中存储重复的行。数据库系统必须有办法将它们视为不同的、不同的行。该系统必须能够关联额外的信息,以达到区分的目的。这意味着系统为关系提供了一个新的(唯一的)属性。因此,在内部,每个表都有一个唯一的主键,这个键要么由表的创建者定义,要么由SQLite定义。主键是一个名为rowid的整数。
7.4.4.1 Rowid column
对于每个SQL表,SQLite指定一列作为rowid(也被oid和_rowid_调用),其值唯一地标识表中的每一行,它是表的隐式主键,表B+树的唯一搜索键。如果表的任何列被声明为整数主键,那么SQLite将该列本身(也称为别名)作为表的行。否则,SQLite将为rowid创建一个单独的唯一整数列,其名称为rowid本身。(如果表中的列具有相同的三个名称,即rowid、oid或_rowid_,则这些名称将指向这些列,而不是内部的rowid列。)因此,无论是否声明了整型主键列,每个表都有一个唯一的整型键,即rowid。对于后一种情况,row本身在内部被视为表的整数主键。在任何一种情况下,rowwid都是一个64位带符号的整数值,范围是-2^63…2 ^ 63 1。(有一个编译时标志可以将队列限制为32位值。)表B+树上的排序顺序是整数(作为数学对象)的自然数字顺序,我们不能有任何其他排序顺序。这些B+树是表上的主索引。row存储在二级索引中(如果有的话),作为指向表B+树的软指针(参见第7.4.5节)。
图7.8显示了一个典型的SQL表的内容,该表是通过SQL语句create table t1(x, y)创建的,其中rowid列由SQLite添加。rowwid值通常由SQLite确定。不过,您可以为rowid c列插入任何整数值,如insert into t1(rowid,x,y)values(100,‘hello ‘,‘world ‘)。行按照行值的顺序存储,
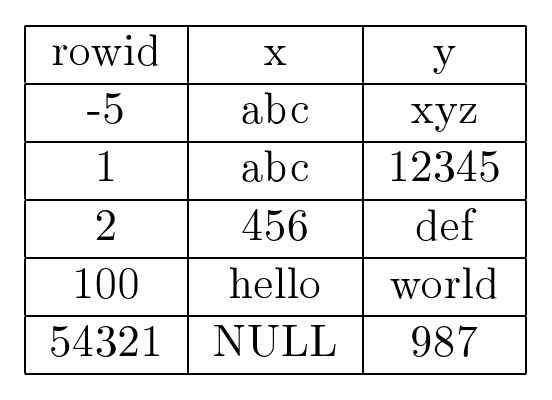
7.4.4.2 Rowid value
如果rowid是一个别名列(即,声明为INTEGER PRIMARY KEY),数据库用户知道这个列,如果rowid列是由SQLite添加的,他们可能知道也可能不知道这个列。在这两种情况下,用户都可以定义rowid值,或者SQLite可以为用户定义这些值。它保证了它们的独特性。当没有指定行id列值的行插入到表中时,SQLite访问表B+树并为行id找到一个未使用的整数。它通常比树中的最大值大1。但是,如果最大值为9223372036054775807,则随机选择一个未使用的数字。它返回SQLITE_FULL错误代码。
7.4.4.3 Rowid representation
根据谁创建了列,row值有不同的表示。如果rowwid列是由SQLite创建的,那么表记录就没有它。否则,将在每个表记录中存储NULL(类型值为0)。SQLite从键中获取实际值。该值表示为可变长度的霍夫曼代码。负rowidd是允许的,但它们总是使用9字节的存储空间,因此不鼓励使用它们。当rowid由SQLite生成时,它们总是非负的,尽管你可以显式地给出负的rowid值;上表中的-5就是这样一个例子。通常很难说(除了负值)哪些是由系统生成的,哪些是由用户提供的。
7.4.5 Index key format
在前面的两个小节中,您已经看到每个表的B+树的键是一个整数,数据记录是表的一行,Indexes颠倒了这种安排。对于索引条目,键是存储在索引表中的行的所有索引列的组合值,数据是一个整数值,即该行的行号。为了访问(从表中)具有用于索引列的特定值的行,VM首先搜索索引以查找相应的整数值(rowid),然后使用该整数值在表的B+树中查找完整的记录。尽管许多人认为按主键引用行成本太高,但SQLite使用它是为了简单。
SQLite通过创建一个单独的“索引表”来实现每个索引(在表上),该索引表存储在单独的b树中。索引B树将搜索键映射到行,行又用于搜索索引表B+树。索引b树有自己的键比较,即排序比较器函数来对索引项进行排序,VM向树模块提供一个指向相应键比较函数的指针。
SQLite自动为CREATE TABLE语句中指定的每个UNIQUE列(包括PRIMARY KEY列)创建索引。如果不删除已索引的表,就不能删除这些索引。可以使用create INDEX语句显式地在非编目表上创建索引。当一个表被删除时,它的所有索引都会被自动删除。有多种方法可以在SOLite中创建索引。下面三个示例在表T1(a, b, c)的a和b列上创建索引。
- Declare the index explicitly.
- CREATE TABLE T1(a.b,c)
- CREATE INDEX idx1 ON T1(a, b)
- Declare columns to be UNIQUE
- CREATE TABLE T1(a, b, c, UNIQUE(a, b))
- Declare columns to be PRIMARY KEY.
- CREATE TABLE T1(a, b, c,PRIMARY KEY(a, b))
Note: INTEGER PRIMARY KEY is special and does not generate a separate index. The table B+tree is ordered by the INTEGER PRIMARY KEY column aliased as rowid.
SOLite allows creation of multiple indexes on the same column. Consider the following example
- CREATE TABLE T2(x VARCHAR(5)UNIQUE PRIMARY KEY.y BLOB):
- CREATE INDEX idx2 ON T2(x)
上面的示例在表T2的列x上创建了三个相同(且独立)的索引:一个隐式地使用关键字unique,另一个隐式地使用关键字primary key,还有一个显式地使用用户。您可能会注意到,额外的索引会减慢insert、update和delete的速度,并使数据库文件变大。模式设计者已经被警告过了!
如前所述,SQLite将索引视为一种表,并将索引存储在自己的b树中。它将搜索键映射到行。索引记录的格式如图7.9所示。整个记录作为b树键;没有数据部分。索引记录的编码与索引表记录的编码相同,除了rowwid被附加在末尾,并且rowid的类型不会出现在记录头中,因为该类型始终是带符号整数,并以Huffman代码表示(而不是内部整数类型)。其他数据、值及其存储类型从索引表逐字复制。图7.8表x列索引的内容如图7.10所示。

SQLite还支持多列索引。图7.11给出了图7.8表中y和x列索引的内容,索引中的表项按照第一列排序;第二列和随后的列用作决胜局。
索引主要用于加快数据库搜索速度,例如,考虑以下查询:SELECT Y FROM t1 WHERE x = 456。假设在x列上有一个索引。VM对索引b树进行索引搜索,并找到x= 456的所有行;对于每一行,它搜索表t1 B+-树,以获得满足搜索的行的y列的值。它使用两次树搜索而不是一次树搜索,因此它比基于行搜索的查找时间长两倍,但是,这绝对比进行全表扫描要好。
临时索引: SQLite可以在执行sql语句时使用order by或group by子句创建临时索引,或者在聚合查询中使用distinct select,或者使用union、except或intersect创建复合查询。这些临时索引存储在临时文件中。
7.5 Datatype Management
数据处理仅在VM模块中进行,该模块驱动后端在数据库中存储和检索数据。虚拟机是存储在数据库中的数据的唯一操纵者;其他一切都由它执行的字节码程序控制。它决定在数据库中存储什么数据,以及从数据库中检索什么数据。为数据值分配适当的存储类型并执行必要的数据、值转换是VM的主要任务。数据和值的转换可能发生在三个数据交换的地方:从SQLite应用程序到引擎,从引擎到SQLite应用程序,以及从引擎到引擎。对于前两种情况,虚拟机为用户数据分配类型。VM尽可能尝试将用户提供的值转换为列声明的SQL类型,反之亦然。对于最后一项,表达式求值需要数据转换,我将在接下来的三个小节中讨论这三个数据转换问题。
7.5.1 Assigning types to user data
在7.4节中,我讨论了表和索引记录的存储格式。每个记录列值都有一个存储类型。您可能会注意到,应用程序以两种方式向SQLite发送列值:(1)嵌入在SOL语句中的文字,(2)绑定到准备好的语句中的值。(虚拟机也通过执行表达式派生列值。)在VM执行准备好的语句之前,它为每个这样的输入值分配一个存储类型。存储类型用于将输入值编码为适当的物理表示形式。
VM分三步确定列的给定输入值的存储类型:首先确定输入数据的存储类型,然后确定列的声明SQL类型,最后,如果需要,它进行数据转换。在下面描述的情况下,VM可以在查询求值期间在数字存储类型(INTEGER和REAL)和TEXT之间转换数据。(您可能会注意到,SQL标准没有为数据编码提供任何指导原则,只有一些例外,如日期、时间、时间戳等)这些将在本小节的其余部分讨论。
7.5.1.1 Storage type determination
SQLite是“无类型的”,也就是说,没有域约束。(SQLite开发团队希望永远保持无类型)无类型允许您在任何表列中存储任何类型的数据,而不考虑该列声明的SQL类型。(此规则的例外是整型主键,也就是rowid列;该列仅存储整数值;您可能会注意到,SQLite不允许在create table语句中声明SQL类型!例如,在SQLite中,create table T1(a, b, c)是一个有效的SQL语句。问题是VM如何在存储给定列之前将存储类型分配给给定的输入值?我在下面回答这个问题。
虚拟机为用户提供的值分配初始存储类型,如下所示。如前所述,有两种方法可以提供SQLite输入值。
-
作为SQL语句的一部分,指定为文字的值被分配为以下存储类型之一:
-
TEXT: 如果值被单引号或双引号括起来
-
INTEGER: 如果值是没有小数点和指数的未计数数
-
REAL: 如果值是带小数点或指数的未引号数
-
NULL: 如果值是不带引号的字符串NULL
-
BLOB: if the value is specifed using the X’ABCD’ notation, where A, B, C, D arehexadecimal digits
否则,输入值将被虚拟机拒绝,查询求值失败
-
-
使用sqlite3_bind_* API函数提供的SQL参数的值被分配为与本机类型绑定最匹配的存储类型。例如,sqlite3_bind_blob绑定一个存储类型为BLOB的值。
作为SQL标量运算符结果的值的存储类型取决于表达式的最外层运算符。用户定义的函数可以返回任何存储类型的值。通常不可能在$QL语句准备时确定表达式结果的类型。虚拟机在运行时获取存储类型后,自动分配存储类型。
7.5.1.2
您可能还记得,SQLite允许任何列(除了整型主键)存储任何类型的值。因此,类型信息与值一起存储。我所知道的其他SQL数据库引擎使用更严格的静态类型系统,其中类型与容器关联,而不是与值关联。SQLite更灵活一些。为了最大限度地提高SQLite和其他数据库引擎之间的兼容性,SQLite支持表中列的类型关联概念。每个输入值都可能与列声明的SQL类型有亲缘关系。列的类型关联是存储在该列中的值的推荐类型:注意“这是推荐的,不是明确的要求”。
列的值的首选类型称为其(列的)亲缘性。列的关联类型与其声明的类型不同,尽管前者派生自后者。每个列具有以下五种亲和类型之一:TEXT、NUMERIC、INTEGER、REAL和NONE。(您可能会注意到一些命名冲突:“text”、“integer”和“real”也是用于内部存储类型的名称。但是,您可以根据其使用的上下文中确定类型类别。)根据CREATE TABLE语句中列声明的SQL类型,SQLite在确定列的亲和类型时遵循以下规则。
-
如果SQL类型声明包含子字符串INT,则该列具有INTEGER关联。
-
如果SQL类型声明包含子字符串CHAR、CLOB或TEXT中的任何一个子字符串,则该列具有TEXT亲缘性。(您可能注意到SQL类型VARCHAR包含字符串CHAR。因此具有TEXT亲和性。)
-
如果SQL类型声明包含子字符串BLOB,或者没有指定类型,则该列具有NONE亲和性。
-
如果SQL类型声明包含子字符串REAL、FLOA或DOUB中的任何一个,则该列具有REAL亲和性。
-
否则,列的关联类型为NUMERIC。
VM按照与上述相同的顺序评估规则。模式匹配不区分大小写。(您可能注意到SQLite对SQL类型声明中的拼写错误一点也不严格。)例如,如果列声明的SQL类型是BLOBINT,则关联是INTEGER,而不是NONE。
注意: 如果创建一个SQl表,使用create table table1作为select…语句中,每列的声明类型由create table语句的select部分中对应表达式的关联类型决定。如果表达式亲和性为文本、数字、整数、实数或无,则声明的列类型分别为文本、num、int、实数或(空字符串)。每个这样的列的默认值是SQL NULL。隐式行的类型总是整数,不能为NULL。
7.5.1.3 Data conversion
SQLite定义了关联类型和存储类型之间的关系。如果用户为列提供的数据值不满足关系,则拒绝该值或将其转换为适当的格式。当一个值要插入到一个列中时,VM首先给它分配最合适的存储类型(参见7.5.1.1节),然后确定该列的关联类型(参见7.5.1.2节),最后尝试将具有初始存储类型的值转换为其关联类型的格式。它使用以下规则:
-
具有TEXT关联的列存储具有NULL、TEXT或BLOB存储类型的所有值。如果在列中插入数值(整数或实数),则将该值转换为文本形式,最终存储类型为text。
-
具有NUMERIC亲缘关系的列使用所有五种存储类型存储值。当文本值插入NUMERIC列时,虚拟机尝试将该值转换为整数或实数,如果转换成功(即…无损和可逆)[-2],然后转换后的值使用INTEGER或REAL存储类型进行存储。如果不能执行转换,则使用TEXT存储类型存储该值。虚拟机不尝试转换NULL或BLOB值。
[-2]要实现无损,必须保留数字的前15位有效十进制数字。
-
具有INTEGER亲缘关系的列与具有NUMERIC亲缘关系的列的行为方式相同,不同之处是,如果插入没有浮点组件的实值(或转换为浮点组件的文本值),则VM将该值转换为整数,最终存储类型变为INTEGER。
-
具有REAL亲和性的列的行为类似于具有NUMERIC亲和性的列,不同之处在于它将整数值强制转换为浮点表示。(但是,SQLite执行优化,没有分数的小值作为整数存储在磁盘上,以占用更少的空间,并且只有在将值从表中读出时才转换为浮点。)
-
亲和性为NONE的列存储所有五种存储类型的值,并且不会优先选择一种存储类型。虚拟机不转换任何输入值。
注意: 所有SQL数据库引擎都进行数据转换。它们拒绝不能转换为所需列类型的输入值。然而,即使不能进行格式转换,SQLite也可以存储值。例如,如果您将一个表列声明为SQL类型INTEGER,并且尝试插入一个字符串(例如“123”或“abc”),VM将查看该字符串并分析它是否看起来像一个数字。如果字符串看起来确实像数字(如“123”),则将其转换为数字(如果数字没有小数部分则转换为整数),并以实数或整数存储类型存储。但是,如果字符串不是格式良好的数字(如“abc”),则将其存储为具有TEXT存储类型的字符串。具有TEXT关联的列在存储数字之前尝试将数字转换为ASCII文本表示形式。但是,BLOB作为BLOB存储在TEXT列中,因为SQLite通常不能将BLOB转换为文本。SQLit允许在整型列中插入字符串值。这是一个特性,而不是一个bug。SQLite开发团队为这个特性感到自豪
7.5.1.4 A Simple Example
让我们研究一个非常简单的示例,以便更清楚地了解存储类型、关联类型和类型转换。图7.12展示了一个典型的表,它的所有列都是无类型的。假设执行图中所示的SQL插入语句。图中还显示了虚拟机插入T1表B+树的行记录。a、b和c列输入值的初始存储类型分别为integer、NULL和text(参见7.5.1.1节)。所有列的亲和性类型都是NONE(参见7.5.1.2节),虚拟机不会转换这些初始存储类型(参见7.5.1.3节)。在图中,行记录(标题加上数据项)由11个字节组成,如下所示。(记录中的所有数字都以十六进制表示。您可能还记得,SQLite不会重新排序列的位置:它们以与create语句中出现的顺序相同的顺序出现。)
-
报头长度为4字节:一个字节用于报头大小,另外一个字节用于列值的三种显示类型。值4被编码为单个字节0x04。
-
类型1(列a值的类型)是数字2(表示2字节有符号整数),编码为单个字节0x02。
-
类型2(列b值的类型)是编码为单个字节0x00的数字0 (NULL)。
-
类型3(列c值的类型)是数字22(一个文本,(22-12)/2=5字节长)编码为单个字节0x16。
-
数据1是一个2字节的整数00B1,其值为177。(您可能会注意到177不能被编码为单个字节,因为Bl是-79,而不是177。)
-
数据2为NULL,它不占用记录中的任何字节。
-
数据3是5字节字符串68 65 60 6C 6F。省略零终止符
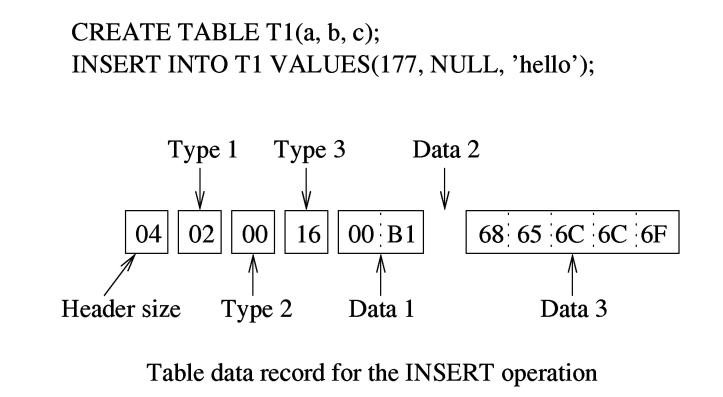
7.5.1.5 Column affinity example
考虑一个由以下SQL语句创建的表T1: create table T1(t TEXT, n NUMERIC, i INTEGER, r REAL, b BLOB)。假设您执行以下sql语句:insert into T1 values(‘1.0’, 1.0’, ‘1.0’, ‘1.0’, ‘1.0’, ‘1.0’)。所有输入值的初始存储类型都是TEXT,因为它们都是单引号。列t、n、i、r和裸列的关联类型分别为TEXT、NUMERIC、INTEGER、REAL和NONE,基于第191页第7.5.1.2节定义的规则。t、n、i、r和b值的最终存储类型分别是TEXT、INTEGER、INTEGER、REAL和TEXT。对于数字亲缘关系类型,‘1.0 ’看起来像一个有效的数字1.0,在数字上等于整数值1,因此最终的存储类型是整数。blob列没有亲和性,因此存储值时不改变初始存储类型。对于insert into T1值(1.0、1.0、1.0、1.0、1.0)的SQL语句,所有输入值的初始存储类型都是real,列的最终存储类型分别是TEXT、INTEGER、INTEGER、real和real。对于文本列,将实际值1.0转换为文本“1.0”作为文本存储类型。对于插入T1值(1,1,1,1,1,1)的SQL语句,所有输入值的初始存储类型都是整数,列的最终存储类型分别是TEXT、integer、integer、REAL和integer。您可以在http:/ www.sglite.org/datatype3.html上找到更多关于列关联的示例
7.5.1.6 Other affinity modes
以上小节描述了数据库引擎在“正常”和默认关联模式下的操作。对于两个极端,SQLite支持另外两个与亲缘模式相关的特性
-
严格关联模式: 在此模式下,如果需要在初始存储类型和关联类型之间进行转换,则引擎返回错误,当前语句执行失败。
-
无亲和性模式: 在这种模式下,虚拟机不执行存储类型之间的转换。
7.5.2 Converting engine data for applications
应用程序调用sqlite3_column_* API函数从SLite引擎读取数据。这些函数尝试在适当的地方转换数据值。例如,如果内部表示是REAL,并且请求文本结果(通过sqlite3_column_text函数),VM在将值返回给应用程序之前,会在内部使用sprintf()库函数进行转换。图7.13中的表格给出了虚拟机对内部数据进行数据转换的规则,从而为应用程序产生输出数据
7.5.3 Assigning types to expression data
VM可以在比较内部数据之前或在计算表达式时转换内部数据。在本小节的其余部分中,我将讨论VM如何处理内部数据
7.5.3.1 Handling SQL NULL values
SQL NULL值可以用于除主键列以外的任何表列。NULL值的存储类型为“NULL”。NULL值与给定列的所有有效值不同,无论它们的存储类型如何。SQL标准通常不是很清楚如何处理表达式中列的NULL值,也就是说,如何在所有情况下处理NULL值。例如,我们如何将NULL值与其他值进行比较?SQLite处理NULL值的方式与许多其他rdbms(如Oracle和PostgreSQL)一样。NULL值在SELECT DISTINCT语句、复合SELECT中的UNION操作符和GROUP BY中被认为是不明显的(即相同的值)。然而,NULL值在UNIQUE列中被认为是不同的。NULL值由SQL标准指定的内置SUM函数处理。对NULL的算术运算总是产生NULL。
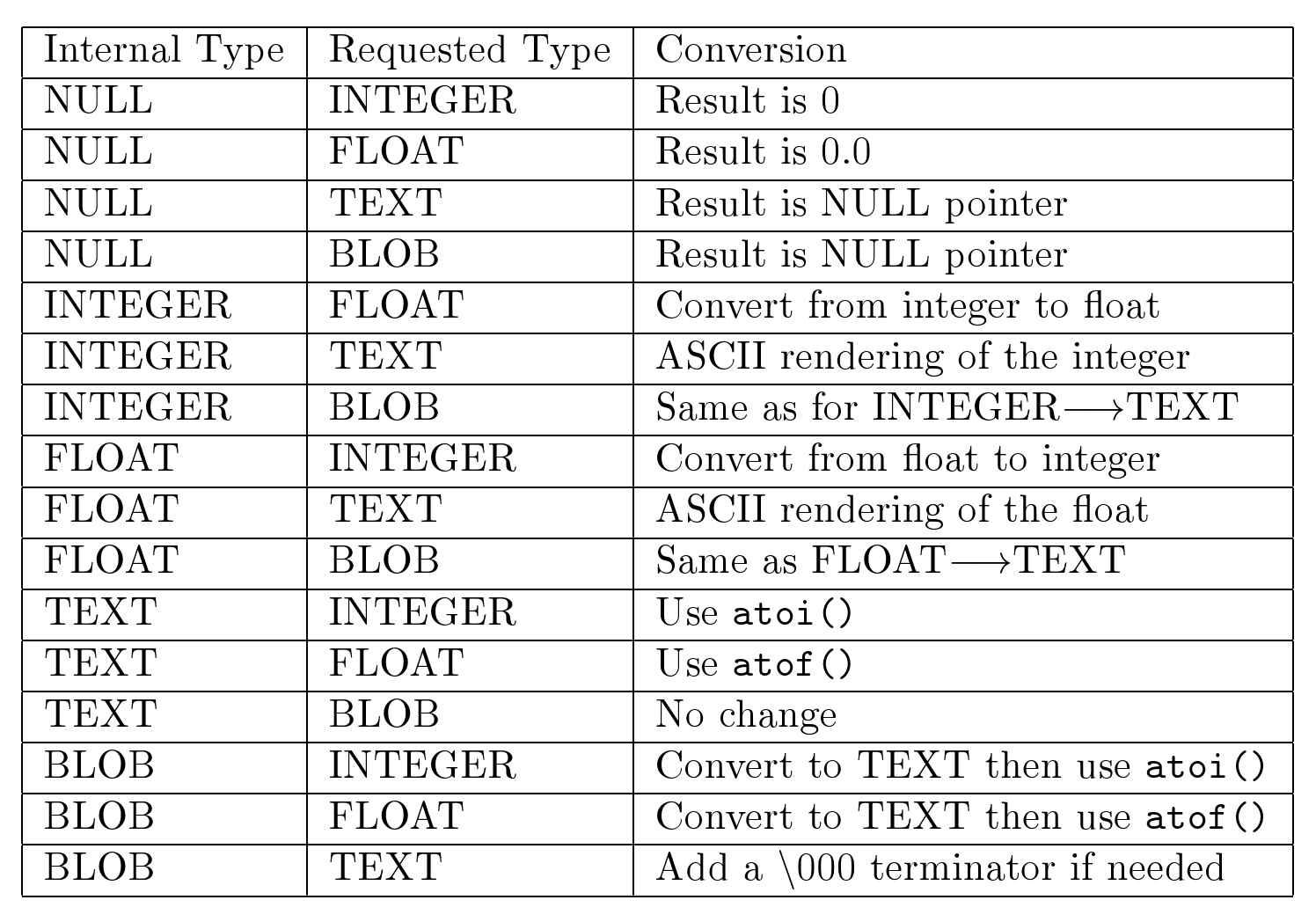
7.5.3.2 types for expressions
SQLite supports four kinds of comparison operations:
-
binary comparison operators =,==,<,<=,>,>=,<>,and !=
-
the ternary comparison operator ‘BETWEEN’
-
the set membership operators ‘IN’and ‘NOTIN’
-
the null checking operators ‘IS NULL’ and ‘IS NOT NULL’
比较操作的结果取决于被比较的两个值的存储类型,遵循以下规则:
-
存储类型为NULL的值(左侧操作数)被认为小于任何其他值(包括存储类型为NULL的另一个值)。
-
INTEGER或REAL值小于任何TEXT或BLOB值。
-
当一个INTEGER或REAL与另一个INTEGER或REAL比较时,执行数值比较
-
TEXT值小于BLOB值。
-
当比较两个TEXT值时,通常使用标准C库函数memcmp来确定结果,但是您可以通过系统或用户定义的排序函数覆盖它。(我将在第247页第10.16节讨论排序。)
-
当比较两个BLOB值时,结果总是通过使用memcmp来确定
但是,在应用上述规则之前,VM的首要任务是确定比较操作符的操作数的最终存储类型。VM首先确定操作数的初步存储类型,然后(如果需要的话)根据它们的亲和力在类型之间转换值。最后,使用上述规则执行比较。如前所述,VM在文本和整数/实存储类型之间转换值。
如果表达式是一个列,或者通过AS别名或子选择引用一个列,并将列作为返回值或行号,则使用该列的关联作为表达式的关联。(参见expr.c源文件中的salite3exprnity函数。您可能会注意到,每个强制转换表达式都显式指定了关联类型。)否则,表达式的亲和力为NONE。在执行比较操作之前,VM可以在数值存储类型(INTEGER和REAL)和TEXT之间转换值。对于二进制比较,这是在下面项目标记的情况下完成的(请参阅expr.c中的sqlite3compareaffinity函数)。以下项目符号中的术语“表达式”是指除列值以外的任何SQL标量表达式或文字。
-
当比较两个值时,如果其中任何一个是具有INTEGER、REAL或NUMERIC亲缘性的列值,则该亲缘性对于两个值都是首选的。也就是说,VM在比较之前尝试转换其他列的值。
-
如果一个值具有TEXT关联,而另一个值为NONE,则将TEXT关联应用于另一个值
-
否则,不会应用关联,也不会发生转换。值的比较遵循上述标准规则:例如,如果将字符串与数字进行比较,则数字将始终小于字符串。
在SQLite中,表达式a BETWEEN b AND c相当于一个>= b AND a <= c。AND操作符的两个子句是使用比较运算符独立求值的,在求表达式所需的两次比较中,每个子句都可以对a应用不同的亲和关系。
a IN (SELECT b from…)类型的表达式由上面列举的相等二进制运算符(例如,a = b)的规则处理。例如,如果b是列值而a是表达式,则在进行任何比较之前将b的亲缘性应用于a。SQLite将表达式a IN(x,y,z)视为等价于a=x OR a= y OR a= z,并且不会对x,y,z应用任何亲和关系。
如果a是NULL值,表达式a IS NULL返回true;否则,返回false
这里有几个简单的例子;您可以在http://www.sglite.org/datatype3.html网页上找到它们和其他内容。假设你有一个表t1,它是通过CREATE table t1(a TEXT,b NUMERIC, c BLOB, d)创建的。你通过执行insert INTO t1 VALUES(‘500’, ‘500’, ‘500’, ‘500’, 500)在表中插入一行。a、b、c和d列值的最终存储类型分别是TEXT、INTEGER、TEXT和INTEGER。下面的比较(选择)语句及其输出揭示了一些微妙之处。
-
SELECT a<600,a<60,a<40 FROM t1在比较前将600,60和40分别转换为“600”,“60”和“40”,因为a列具有TEXT亲和性,并且值作为TEXT进行比较;语句返回110作为输出,因为“500”小于“600”和“60”作为文本,并且不小于“40”
-
SELECT b< 40,b<60,b<600 FROM t1不转换任何文字值,因为b具有NUMERIC亲和力,并将值作为NUMERIC进行比较,并返回0 | | 1作为输出,因为500在数字上小于40和60,但不小于600。
-
SELECT c< 40,c<60,c<600 from t1不会转换40,60和600,因为c具有NONE亲和关系。三个文字值(存储类NUMERIC)小于“500”(存储类TEXT),语句返回0|0|0作为输出。
-
SELECT d< 40,d<60,d<600 from t1不会转换40,60和600,因为d具有NUMERIC亲和性,并且返回0|0|1作为输出,因为值是作为整数进行比较的。
7.5.3.3 Operator types
所有数学运算符(除了连接运算符l)在求值之前对所有操作数应用NUMERIC亲和性。但是,如果任何一个操作数为NULL,则结果为NULL;其他非数字操作数在执行数学运算之前被转换为0或0.0。对于连接操作符,将TEXT关联应用于两个操作数。如果VM不能将任何一个操作数转换为TEXT(因为它是NULL或BLOB),则连接的结果为NULL。
7.5.3.4 按顺序键入
当在选择查询中使用ORDER by子句对值进行排序时,在排序之前不会进行存储类型转换。遵循前面所述的标准比较规则:存储类型为NULL的值首先出现,然后是按数字顺序排列的INTEGER和REAL值,然后是按memcmp()顺序或系统或用户定义的排序顺序排列的TEXT值,最后是按memcmp()顺序排列的BLOB值。(参见第10.16节学习如何在SQL语句中使用排序规则。)
7.5.3.5 group by的类型
对于在选择查询中使用GROUP BY子句对值进行分组,在分组之前不进行存储类型转换。具有不同存储类型的值被认为是不同的,除了INTEGER和REAL值,如果它们在数字上相等,则被认为是相等的。作为GROUP BY子句的结果,任何值都没有关联
7.5.3.6 复合select中的类型
复合SELECT操作符(即UNION、INTERSECT和EXCEPT)执行值之间的隐式比较。在执行对应的比较之前,虚拟机不会执行任何与亲缘性相关的值转换。值按原样进行比较
Summary
虚拟机模块为后端数据库引擎。数据操作逻辑驻留在这个模块中。它执行用特殊的字节码编程语言编写的程序。(这与其他汇编语言类似。)字节码程序是字节码指令的线性序列。字节码指令有一个操作码,最多可以有五个操作数或寄存器名 操作数。
字节码程序(由前端系统生成)由Vdbe对象表示(外部由sqlite3_stmt指针表示)。应用程序在对象上应用SQLite api来执行字节码程序。例如,当应用程序执行sqlite3_step API函数时,它会对程序执行进行迭代,直到执行停止或中断输出行。
虚拟机支持5种数据类型:integer、real、text、blob和SQL NULL。数据库或内存中的每个数据必须是这五种类型之一。这被称为数据的存储类型。根据需要,虚拟机可以将数据从一种类型转换为另一种类型。应用程序可以使用SQL函数的类型来确定值的数据类型。
虚拟机是唯一的数据操控者。它维护表树和索引树中的记录。它们的记录格式非常相似。SOLite使用变长记录格式方案的变体。它使用清单类型来表示记录中的单个值。在清单类型中,对于每个值,其存储类型信息也存储在记录中。该方案允许在任何列中存储任何存储类型的值,而不考虑列声明的SQL类型,只有一个例外,即整数主键列仅存储整数值。值的存储类型被编码为整数,整数也编码值的(字节)长度。每个表记录都以标头大小开始(这是一个可变长度的Huffman代码),然后是数据值的清单类型,然后是单个数据值。
在SQLite中,数据类型管理有点复杂。SQLite根据列声明的SOL类型为列分配关联类型。首先尝试将输入数据值转换为关联类型。如果转换不成功,原始值仍然存储在列中。SQLite为表达式和函数的求值做类似的数据转换。
Chapter 8 The Frontend module
读完这一章,你应该能够解释/描述。
-
SQLite前端系统是如何由标记器、解析器、优化器和代码生成器组成的
-
SQLite使用的各种代码优化技术
章节简介
为了执行SQL语句(或SQLite命令),SQLite首先对语句进行预处理和分析,然后生成一个字节码程序,VM可以执行该程序来生成语句的输出。前端子系统对SQL语句进行预处理、优化,生成字节码程序。他的章节介绍了前端的内部工作原理。
8.1前端
每个SQL数据库系统都将每个SQL语句编译成某种内部表示,后端引擎使用它来执行语句指定的工作。在大多数SQL rdbms中,内部表示是一个相互链接的对象的复杂网络,或者至少是一个对象树。在SOLite中,表示是一个类似机器语言的程序,这个翻译是由前端完成的。(对于任何SQL语句,都可以通过在语句前加上EXPLAIN关键字来查看相应的字节码程序。第176页的图7.1给出了一个示例字节码程序。)
SQLite前端由四个子系统组成:(1)标记器,(2)解析器,(3)优化器和(4)代码生成器。标记器将输入字符串分解为许多不同的标记。解析器通过将相应的标记组织到解析树中,为输入SQL语句分配结构。优化器重新构造解析树并生成一个新的解析树,该解析树将生成一个等效但高效的字节码程序。代码生成器遍历树并生成一个字节码程序,该程序被认为等同于输入SQL语句指定的操作。前端实现sqlite3 prepare API函数,用于转换SQL;语句和SQLite命令转换成字节码程序。您可能还记得,每个字节码程序在内部都由一个Vdbe对象表示。在本章的其余部分,我将讨论四个前端子系统。本章的大部分内容是关于查询优化的。
8.2标记器
标记器子系统是前端的最顶层模块(参见第72页的图2.10)。标记器查看输入字符串,并将字符串分割成一系列标记,然后将这些标记一个接一个地发送给解析器(标记是具有特殊含义的字符序列,标记的示例包括左括号、文字、关键字、标识符等)。字面值是字符串、数字和二进制常量,关键字在SQL/SOLite中有特殊的含义。标识符引用特定的对象,如列、表、索引)。标记器丢弃所有空白和注释标记。它为每个令牌分配一个令牌类。大约有140种不同的令牌类(SQLite使用Lemon解析器生成器,它定义了令牌类,并在SQLite源代码编译过程中将它们写入parse.h文件;令牌类名称的前缀为TK_string。)标记器源代码在tokenize.c文件中定义。它还使用keywordash .h中的SQL关键字哈希表(该文件也是在SQLite源代码编译时生成的)。图8.1显示了标记器对一个SQL输入字符串所做的典型示例。
CREATE TABLE table1(a BLOB PRIMARY KEY, b TEXT);
标记器将标记分为两组:关键字和非关键字。如果令牌是关键字,则从关键字哈希表中获取该关键字的令牌代码,并将其发送给解析器。如果令牌不是关键字,则返回TKID。例如,在上面的表中,table1是TK_ID。您可能会注意到,除了TK_ID之外,每个(非空格和非注释)类类型都是关键字。
8.3 解析器
解析器从标记器接受标记,分析SQL语句的结构。并将这些标记组织到一个解析器树中。(解析树是描述SQL语句的数据结构。)解析树由我下面描述的几个主要数据结构组成。
-
令牌:来自输入SQL语句的单个令牌。令牌对象用于保存文字的文本值或表或列的名称。它用于将值从标记器传递给解析器。
-
Expr:表达式中的单个操作符或操作数。表达式结构树描述了一个完整的表达式。
-
ExprList:一个或多个表达式的列表,每个表达式都有一个可选的标识符和升序/降序标志
-
标识符:一个或多个标识符的列表。
-
SrcList:一个或多个数据源的列表。数据源可以是SOL表、视图或子查询,基本上可以是生成数据行的任何东西。(对于插入、删除和更新语句,列表大小为1。)
-
Select:在子查询中找到的SELEOT语句
解析器检查查询的语法,还执行一种语义检查,例如,查询中引用的表是否存在于数据库中,以及所有属性是否在其模式中。下面是如何使用上述数据结构解析SQL语句的一些示例
-
DELETE FROM (srclist) WHERE (expr);
-
UPDATE(srclist) SET (exprlist) WHERE (expr);
UPDATE(srclist)SET(id=expr,id=expr,id=expr)WHERE (expr); -
INSERT INTO(srclist(idlist))VALUES((exprlist));
INSERT INTO(srclist(idlist))select; -
SELECT (exprlist) FROM (srclist) WHERE (expr) ORDER BY (exprlist)
当解析器被调用时(通过sqlite3_prepare函数),它首先创建并初始化一个Parse类型的对象(见图8.2)。对象表示一个SOL解析上下文。对象通过解析器向下传递到所有解析器操作例程,以便携带整个解析过程的全局信息
Parse对象包含一个指向Vdbe对象的指针。如第181页的图7.3所示,Vdbe对象包含一个用来保存字节码程序的空间。最初空间是空的。随着解析和代码生成活动的发展,它由代码生成器填充。您可以研究build. source文件,了解如何为create table/index语句执行解析和代码生成。
8.4 The Code Generator
代码生成器从解析器接受解析树,并生成VM可以执行的字节码程序。许多(几乎所有)rdbms生成一个数据结构树,VM遍历该树以评估程序。SQLite生成类似于汇编语言程序的字节码过程程序。虚拟机解释字节码程序
代码生成器接受来自查询优化器的(优化的)解析树,并生成字节码指令,以执行解析树所表示的SQL语句的工作。它是SQLite中最大、最复杂的子系统:它占据了SOLite库代码的40%。与其他子系统不同,它没有定义良好的接口。它与解析器/优化器紧密耦合。以下内部函数有助于代码生成过程
-
sqlite3GetVdbe: It returns a pointer to the Vdbe obiect for the current parse tree. it create the object if it does not already exist.
-
sqlite3VdbeAdd0p0-4: It adds a new bytecode instruction to the end of the program for the given Vdbe obiect.
-
sqlite3VdbeChangeP1-5:It changes the P1-5 operand of an existing instruction.
-
sqlite3VdbeCurrentAddr: It returns the address of the next instruction to be inserted.
-
sqlite3ExprCode:It generates code to evaluate an expression
-
sqlite3ExprIfTrue: It generates code that will branch if a boolean expression is true.
-
sqlite3ExprIfFalse: It generates code that will branch if a boolean expression is false
-
sqlite3CodeVerifySchema: It generates code that will verify the schema cookie after starting a read-transaction on a database file. (It is important that the schema cookie be verified and a read-transaction be started before anything else happens in the bytecode program.
-
sqlite3BeginWrite0peration: It generates code that prepares for doing an operation that might change the database. It starts a new write-transaction on a database file and the temp database if we are not already within a transaction
-
sqlite3ChangeCookie: It generates code that will increment the schema cookie.
-
sqlite3NestedParse: It is used only to parse and generate code for an SQL statement as a part of another SQL statement. This function is designed to allow the INSERT, UPDATE and DELETE operations on the sqlite master table, which are needed when users execute CREATE,DROP,and ALTER statements
where.c 文件中的例程生成代码来实现SQL SELECT、DELETE和UPDATE语句的WHERE子句。该文件中的代码决定使用什么搜索策略和索引(如果有的话)。SELECT、DELETE和UPDATE的代码生成器调用sqlite3WhereBegin来创建循环的顶部,该循环将为匹配WHERE子句的每一行运行一次。然后调用者添加字节码来处理单行。然后调用sqlite3WhereEnd来结束循环。sqlite3WhereBegin返回一个指针,该指针成为sqlite3WhereEnd的唯一参数。
8.4.1 Name resolution
即使存在不能与有意义的信息相关联的标识符(TK), SQL语句也没有任何意义。当标识符的名称出现在表达式中时,代码生成器必须找出标识符引用的表、索引或表的列。例如,一个标识符可以解析为一个列是SELECT的FROM子句中的一个表,也可以解析为正在被INSERT、UPDATE或DELETE操作的表;源表的srlist。标识符还可以解析为SELECT语句的结果集中的一个表达式(ExprList)的名称。SrcList和ExprList(每个都可能为空)形成一个“NameContext”,用于解析表达式中的标识符名称。子查询可以导致嵌套的namecontext。例如,在SELEcT exprlist2 FROM srclist2 WHERE…在(SELECT exprlist1 FROM srclist1 wHERE…),内部名称econtext (exprlist1, srclist1) pair保存一个指向外部NameContext (exprlist2, srclist2)对的指针。
代码生成器使用sqlite3ResolveExprNames例程(在resolve.c中实现)来解析表达式中的名称。在解析子查询中的名称时,它使用内部的Name ontext调用解析器,并使用外部的NameContext来解析周围语句中的名称。在为子查询解析名称时,如果不能使用内部上下文解析名称,则会弹出到外部上下文并再次尝试。在外部上下文中解析名称意味着我们正在处理相关子查询,非相关子查询运行一次,其结果被存储以供将来使用,相反,相关子查询必须在每次需要其结果时重新运行。
8.5 Query Optimizer
给定一个SQL语句,通常有许多不同的等价关系代数表达式,因此有许多解析树,从某种意义上说,它们都产生相同的结果。代码生成器可以为不同的解析树生成不同的字节码程序。虚拟机执行这些字节码程序所需的时间不同。查询优化器的职责是找到生成最有效字节码程序的树。
每个解析树都是关系代数操作树,并确定查询求值的计划。该计划决定每个代数操作的适当算法和存储中间结果的机制。RDBMS通常包括一个优化器,其工作是选择用最少的时间和/或空间产生结果的最佳计划。寻找最佳方案是一项计算量很大的任务,实际系统满足于接近最佳方案或至少避免了最坏方案。大多数系统采用各种启发式方法来决定最终计划。查询优化是一个非常微妙的问题,因为引擎执行查询的速度取决于前端所做的优化。在SQLite中,由于V盲目执行字节码程序,所有的优化工作都由前端完成。
对于SQL插入语句和那些没有where子句的语句,优化器可以做的事情不多。在其他情况下,优化器的主要目标是减少从基表检索的行数。访问基表是非常密集的I/0操作,因此是一个代价高昂的操作。因此,优化器减少对基表的访问越多,查询执行速度就越快。实现这一点的唯一方法是使用一个好的访问路径(即索引)。对于每个SQLite表,表本身是主索引,但表上可以有二级索引。优化器必须决定从每个基表检索行的访问路径:全表扫描或索引扫描。在SQLite中,全表扫描包括按照行顺序从表B+树中读取所有行,如果扫描列没有索引,那么全表扫描是唯一的选择。否则,我们可以进行索引扫描,这样可以减少从基表中检索一些不需要的行。例如,按rowid执行的点查找查询(例如select from t1,其中rowid=2)使用表B+树进行索引扫描,并且快速检索结果,因为它最多从表中检索一行。对于select * from t1, SQLite执行t1表B树的全表扫描。对于select * from t1 where col1 = val.如果列col1上没有索引,SQLite执行全表扫描,并对每一行col1的值与val进行比较。。
在给定查询的查询优化中有两个主要问题:(1)考虑哪些备选计划,以及(2)如何估计计划的成本。SQLite在很多层面上进行优化。优化基本上包括选择那些能更快产生结果的表和索引。您可能还记得,每个SQL表都存储在以rowid为键的B+树中。B+树称为表的主索引。对于不同的搜索键,表上可以有其他二级索引(b树),二级索引中的每个条目包括SQL表中相应条目的行号。在对一行进行索引查找时。VM遵循的正常过程是,它搜索索引以找到索引条目,提取。从索引获取行id,并使用该行id在基表上执行搜索。因此,典型的通过索引查找涉及对两个树进行两次搜索。但是,如果要从表中提取的列在索引本身中已经可用,则VM将使用索引中包含的值,并且永远不会查找基表。(您可能还记得在第187页的7.4.5节中,相同的值及其清单类型信息从基表复制到索引中。这为每行节省了一次树搜索,并且可以使许多查询以两倍的速度运行。
在本章的其余部分,我将讨论SELECT语句的查询优化问题。DELETE和UPDATE的优化方法类似。后两者实际上分为两个阶段。(1)在第一阶段,虚拟机将受影响行的队列存储在一个内部FIFO对象中(RowSet类型在RowSet .c源文件中定义)。(2)在第二阶段,它做实际的删除或更新的顺序,将队列放入先进先出。没有WHERE子句的DELETE语句使用一个特殊的操作码(OP_CLEAR)来擦除整个表。如果要抑制这种优化,必须在DEETE语句中添加WHERE 1。c源文件几乎包含了所有的查询优化代码。
您可能会注意到,SQLite不跟踪SQL表的大小和其他统计信息。优化方案相当简单。每个SQL被划分为查询块的集合,并且每个块都是独立优化的。以下小节描述了一些优化方案。
8.5.1
默认情况下,SQLite不收集统计信息,而许多dbms通常会收集统计信息以进行查询优化。但是,SQLite支持用于此目的的分析命令,以便数据库用户可以手动在表和索引上构建一些统计信息。这使查询优化器能够更准确地估计使用各种索引所涉及的工作量,并为查询选择最佳索引(这是一个高级特性,可以在SQLite源代码编译时永久禁用)。默认情况下,analyze命令扫描所有(包括附加的)数据库中的所有表和索引,并收集有关它们的统计信息。但是,您可以选择性地对特定数据库(它的所有表和索引)或甚至特定表运行该命令,以仅分析其本身及其索引或仅分析单个索引。analyze命令执行的结果存储在sqlite_stat1编目表中。
在第一次执行analyze命令时,SQLite创建sqlite_stat1目录。目录的结构相当于以下模式定义:创建表sqlite_stat1(tbl, idx, stat),其中tbl是表的名称,idx是表上的索引名称,stat包含索引的统计信息。最后一个是一个字符串,由表示索引的各种统计信息的整数列表组成。第一个整数是索引中条目的总数。连续的整数值表示表中每个索引列的统计信息。这个整数值是对索引将为给定列值选择的表的行数的猜测。如果d是列中不同值的计数,k是表中的总行数,则该整数计算为[k/d]。如果k= 0,则d = 0,并且在stat1目录中不会有任何条目。如果k >为0,那么d >总是为0。查询优化器可以使用该分析的输出信息为查询执行计划更好地选择索引。您可能会注意到,stat1目录不会随着数据库的更改而更新。因此,在进行重大更改之后,可能需要再次重新运行theNALYZE命令。但你有一个选择。ANALYZE命令的结果只对在ANALYZE命令完成后打开的数据库连接可用。
您可以读取、修改甚至完全擦除stat1目录的内容,但不能删除它。擦除目录的整个内容具有撤消ANALYZE命令的效果。更改目录的内容会扰乱信息,使优化器非常困惑,并可能导致它做出愚蠢的索引选择。SOLite开发团队不建议以任何方式更新目录,除非运行ANALYZE命令。
注意: 有一个可选的sqlite_stat2目录,用于存储在analyze命令执行期间收集的直方图数据。当使用SQLITE_ENABLE_STAT2编译标志编译SQLite源代码时,此目录可用。
8.5.2 WHERE clause
WHERE子句是SQL应用程序中使用最广泛的子句。SQLite将其分解为多个“术语”,其中术语通过AND操作符连接。这被称为合取范式的表达式。(您可能会注意到,如果where子句包含OR操作符,则整个子句是单个项,SQLite应用OR优化技术;参见第210页第8.5.4节。)例如,在select * from t1 where一个> and b <0语句中,一个> and b <0是where子句,这里有‘a > ’和‘b <0 ’项。SQLite尝试使用索引来计算每个项。如果可能,则不会对该术语执行单独的测试,因为索引搜索将自动执行测试。如果对于term不可能这样做,则根据相关输入表的每一行计算term。(您可能会注意到,该测试仅用于丢弃一些检索到的行:但它们并不影响检索到的总行数。)有时,一个术语可能为索引提供提示,但该术语仍然针对基表的每一行进行计算。在分析一个词的过程中,SQLite可能会在WHERE子句中添加新的“虚拟”词。虚拟术语通常使用索引来满足,从不针对从基表检索的行进行测试。以下构造控制优化过程中索引的使用。
-
Indexes will only be used when the WHERE clause consists of terms connected by AND (e.g. select * from table1 where x = 5 AND y >= ‘a’ AND y , ‘zzz’).
-
An IN clause will also use an index (e.g. select * from table where x in (5.7))
-
The use of OR disables indexes (e.g.,select *from table1 where x=5 0R y=7)Instead of OR, you can use a UNION in such cases (e.g., select * from table1 wherex=5 union select from table1 where y= 7). If the two SELECTs are disjoint, aUNION ALL runs faster than a UNION(e.g.,select * from table1 where x5 union.all selectfrom table1wherex7).
A term must be of one of the following forms in order to be used in an index: (1) column OP expression,(2)expression OP column, (3) column IN (expression-list),(4)column IN (subquery)(5)column is null:where OP is either = or > or >= or < or <=.
Using single column indexes is straightforward. Let us study how SOLite decides on a multicolumn index Suppose a table table1 has an index that is created using a statement like this: create index idx1 ON table1(a,b,c,d,e,…,y,z).对于每一对连续的列i和j, i是主列,j是排序顺序的决定性因素。因此,索引的列只能按从左到右的顺序使用,从a开始。因此,如果索引的初始列(列a、b等等,连续出现)出现在WHERE子句terms中,$QLite可能会选择该索引。例如,如果列a没有出现在一个术语中,则不能使用索引idxl。所有索引列(从最左边的列开始)必须与相等操作符或IN操作符一起使用,但最右边的列可以有不相等操作符,并且可以是任何列。对于最右边的列,最多可以有两个不等式定义列的上限和下限边界值。
您可能特别注意到,要使用索引,索引的每一列不一定要出现在WHERE子句项中,但是索引的列之间不能有空白。对于我们的示例索引,假设在查询中没有约束列的WHERE子句。那么约束列a和b的项可以与索引一起使用,但约束列d到z的项不能与索引一起使用。类似地,在仅受不等式约束的列的右侧不会使用索引列(用于索引目的)。对于我们的示例索引和WHERE子句,像这样:…如果a=5 AND b IN (1,2,3)AND d = ‘hello world ‘,则只有索引列a, b和c可用。d列是不能用的因为它在c的右边c受到不等式的约束。d子句成为查询求值目的的测试用例
8.5.3 BETWEEN clause
SQLite将诸如expr1 BETWEEN expr2 AND expr3这样的BETWEEN子句转换为expr1 > expr2 AND expr1 <= expr3。这个替代条款有两个虚拟条款。如果两个虚拟项都可以使用索引求值,那么原始的BETWEEN项将被删除,并且不会对输入行执行相应的测试。相反,SQLite对索引执行范围搜索,下界和上界分别由expr2和expr3设置。否则,虚拟项可能用作索引选择的提示,并且对每一行计算原始子句;expr1表达式只求值一次。
8.5.4 OR cause
如果一个词由多个包含相同列名的子词组成,并以OR分隔,例如:column = expr1 0R expr2 = column OR column = expr3 0R…注意,指定的列在每个or连接的子项中必须是相同的列,尽管该列可以出现在=操作符的左侧或右侧。如果列有索引,则使用该索引。否则,SOLite使用一种不同的优化策略,其中分析每个单独的词(就好像它是一个完整的where子句),以查看是否可以有效地使用某些索引。如果索引可以单独满足所有项,则将选择的行合并,并消除冗余。在最坏的情况下,它执行全表扫描。
8.5.5 LIKE or GLOB clause
这两个是模式匹配操作符,GLOB操作符总是区分大小写的。但;LIKE操作符有两种模式,可以通过pragma来设置。LIKE比较的默认模式对拉丁1字符的大小写差异不敏感-基本上是英语语言的大写字母和小写字母在较低的127个ASCIl代码中。因此,默认情况下,以下表达式为true: ‘a ' LIKE ‘a ‘,您可以通过将bragma变量case_sensitive_like设置为1或通过构建默认的类似大小写敏感的SQLite库来使LIKE操作符区分大小写。除非用户提供的排序序列不同,否则国际字符总是区分大小写的。
由LIKE或GLOB操作符组成的术语有时可以用来约束索引,在这个问题上有很多条件:
-
LIKE或GLOB操作符的左侧必须是具有文本关联的索引列的名称。
-
LIKE或GLOB的右侧必须是一个字符串字面值或绑定到a的参数 不以通配符开头的字符串字面值。
-
ESCAPE子句不能出现在LIKE操作符上。
-
不能使用salite3_create_function API重载用于实现LIKE和GLOB的内置函数。
-
对于GLOB操作符,列必须使用默认的BINARY排序序列。
-
对于LIKE操作符,如果启用了case_sensitive LIKE模式,那么列必须使用默认的BINARY排序序列,或者如果禁用了case_sensitive_like模式,那么列必须使用内置的NOCASE排序序列。
8.5.6 Join table ordering
当前SQLite的实现只使用循环连接:它总是作为一系列嵌套循环执行。FROM子句中表的顺序决定了循环的嵌套。FROM子句中的第一个表成为最外层循环,最后一个表成为最内层循环,所有中间表以指定的顺序出现作为中间循环。例如,两个表连接的实现方式如下:对于外部表中的每一行,在内部循环上扫描整个表并生成输出行。当有一个带有IN操作符的WHERE子句时,可能会导致额外的嵌套循环,用于扫描IN右侧的所有值。
上面的段落解释了嵌套循环的默认顺序。但是,在某些情况下,如果这样做有助于选择更好的索引,那么SQLite可能会以不同的顺序嵌套循环,从而导致更快的查询求值。它使用贪婪算法来确定循环嵌套顺序。在制定查询计划时,优化器首先在连接中查找需要处理的工作量最少的表。这个表成为外循环。然后,它寻找下一个最容易处理的表,这将成为下一个循环,以此类推。如果出现平局,原始FROM子句中指定的表顺序将成为平局打破者。为了确定处理一个表需要做多少工作,它会考虑许多因素,例如特定列上索引的可用性、索引的使用是否会消除排序的需要以及索引的选择性。有些索引可能会将搜索从一百万行减少到几千行,其他索引可能会将搜索减少到几行或单行。当然,首选其他索引。ANALYZE命令(参见第8.5.1节)的目的是收集有关索引的选择性的统计信息,以便SQLite可以做出明智的猜测,哪些索引可以将搜索减少到数千行,而不是1行或2行。如果在表的连接列上存在索引,SQLite可以将其作为内部循环并利用该索引。它被称为索引嵌套循环连接。
注意: 当选择表的连接顺序时,SOLite使用贪婪算法,运行时间为多项式。如果在内连接中使用ON和USING子句,则在分析WHERE子句之前将它们转换为WHERE子句的附加术语。
上内部连接可以自由地重新排序。因为左外连接既不是交换的也不是关联的,而且SQLite不会对表重新排序。如果优化器认为外部连接左侧和右侧的内部连接中的表可以重新排序,但是外部连接总是按照它们发生的顺序进行评估。
上嵌套表的重新排序是自动的,通常工作得很好,程序员不必考虑它。但偶尔他们的一些暗示是值得赞赏的。您可以通过在from子句中使用‘cross ’关键字强制SQLite,例如table1交叉连接table2。在这种情况下,table1是外部循环,table2是内部循环。
8.5.7 lndex section
对于查询的FROM子句中的每个表,SQLite最多只能使用一个索引;异常是or子句,它可以使用多个索引。而且,它力求在每个表上至少使用一个索引。当有多个索引可供表使用时,SQLite根据一些启发式方法选择其中一个。例如,考虑以下示例。
CREATE TABLE table1(x,y,z);
CREATE INDEX i1 ON table1(x);
CREATE INDEX i2 ON table1(y);
SELECT z FROM table1 WHERE x=5 AND y= 6:
对于示例SELECT语句和数据库模式,SQLite可以使用i1索引查找表table1中x列中包含值5的行,然后根据y= 6项测试每个匹配行。或者,它可以使用i2索引查找table1中y列中包含值6的行,然后根据x=5项测试每个匹配行。在同一表上的两个或多个索引是候选索引的情况下,SQLite尝试使用每个单独的索引估算执行查询所需的总工作量,并选择估算工作量最少的索引。如果sqlite_stat1目录可用,SQLite将从目录中挖掘出一些信息,以便在索引选择方面做出更好的决策。您可能还记得,stat1目录存储关于一个列值平均需要多少行的信息。可以选择给出最低预期数字的指数。
在这种情况下,SQLite为应用程序开发人员提供了制定查询的选择。它们可以通过在列名前添加一元+运算符来手动取消索引的资格。一元+是无操作的,但它会防止术语约束索引,因此,在上面的示例中,他们可以将查询重写为:SELECT z from table1 WHERE +x=5 AND y= 6。x列上的+操作符将阻止该项约束列x上的索引。这将强制优化器使用i2索引。
8.5.8 ORDER BY
只要有可能,SQLite就会尝试使用索引来满足查询的ORDER BY子句。当面临使用索引来满足WHERE子句约束或满足ORDER BY子句的选择时,SQLite执行与8.5.7节中描述的相同的工作分析,并选择它认为最快得到答案的索引。
如果结果记录不能在索引的帮助下以ORDER BY的顺序读出,则所有记录都被加载到排序器中,按预期的顺序排序,然后按指定的顺序读出。SQLite使用瞬态索引进行所有这些排序,因此具有很高的内存开销。排序模板是这样的。
open a sorter
where-begin
extract columns
bundle colmns into a record
create sort key
add key and record to the sorter
where-end
sort
foreach sort element
extract columns
send result to caller
eno-foreach
close the sorter
8.5.9 GROUP BY
聚合查询使用“aggregator”,这是一个特殊的表,包含键值和数据值的记录。GROUP BY术语构成键,其他术语构成数据。对于每一行,使用GROUP BY项查找记录,然后相应地处理它们。下面是groupby模板。
where-begin
compute group-by key
focus on the group-by key
update aggregate terms
where-end
foreach group-by
compute result-set
send result to caller
end-foreach
8.5.10 Subquery flattening
当在SELECT查询的FROM子句中出现子查询时,查询的默认求值方式是先执行子查询,将结果存储在临时表中,然后在临时表上运行外部查询,最后删除临时表。这是有问题的,因为临时表将没有任何索引,外部查询(很可能是带有where子句的连接)将被迫对临时表进行全表扫描。也就是说,它需要对数据进行两次传递,从而降低了查询处理速度。为了克服这个问题,SQLite尝试在SELECT的FROM子句中填充子查询,这需要将子查询的FROM子句插入到外部查询的FROM子句中,并重写外部查询中引用子查询结果集的表达式。
为了更好地理解增肥的概念,让我们学习下面的SELECT语句:SELECT a FROM (SELECT x + y AS a FROM t1 WHERE z<100) WHERE a>5。使用查询增肥技术将该语句重写为:SELECT x + y as a FROM t1 WHERE z<100 AND a>5。为这种简化而生成的代码给出了相同的结果,但只需要扫描一次数据。而且,由于索引可能存在于表t1上,因此可能没有必要对数据进行完整的表扫描。
要发生查询增肥,必须满足一长串条件。只有当下列所有条件都满足时,才会尝试扁平化。最新的列表可以从SQLite主页获得。
-
The subquery and the outer query do not both use aggregates.
-
The subquery is not an aggregate or the outer query is not a join.
-
The subquery is not the right operand of a left outer ioin
-
The subquery is not DISTINOT or the outer query is not a join
-
The subquery is not DISTINCT or the outer query does not use aggregates
-
The subquery does not use aggregates or the outer query is not DISTINCT
-
The subquery has a FROM clause
-
The subquery does not use LIMIT or the outer query is not a join
-
The subquery does not use LIMIT or the outer query does not use aggregates
-
The subquery does not use aggregates or the outer query does not use LIMIT
-
The subquery and the outer query do not both have ORDER BY clauses
-
The subquery and outer query do not both use LIMIT
-
The subquery does not use OFFSET
-
The outer query is not part of a compound select or the subguery does not have both a. ORDER BY and a LIMIT clause.
-
The outer query is not an aggregate or the subquery does not contain ORDER BY
-
The sub-query is not a compound select, or it is a UNION ALL compound clause made uientirely of non-aggregate queries,and the parent query:
-
is not itself part of a compound select.
-
is not an aggregate or DISTINCT query, and has no other tables or sub-selects in the FROM clause
The parent and sub-query may contain WHERE clauses. Subject to rules (11), (12) and (13)they may also contain ORDER BY, LIMIT and OFFSET clauses.
-
If the sub-query is a compound select, then all terms of the ORDER by clause of the parenmust be simple references to columns of the sub-query.
-
The subguery does not use LIMIT or the outer query does not have a WHERE clause.
-
If the sub-query is a compound select, then it must not use an ORDER BY clause.
8.5.11 最小/最大
考虑这样的查询:SELECT MIN(col) FROM table1和SELECT MAX(col) FROM tablel。如果在col列上有一个索引,我们需要做一个表扫描。但是,如果在col列上有索引,$QLite将根据表的大小以对数时间计算查询。基本上,它查找所选索引B树中的第一个或最后一个条目,如果列是INTEGER PRIMARY KEY,则查找表B+树。
Summary
本章讨论SQLite前端系统的功能。它由标记器、解析器、优化器和代码生成器组成。它接受来自应用程序的SQL语句,并将其转换为V执行以产生所需输出的等效字节码程序。
每个输入SQL语句首先被提供给标记器,标记器将语句分割成不同的标记,并将它们一个接一个地发送给解析器。(与YACC/BISON不同,在SQLite中,标记器驱动解析器。)解析器分析标记并检查原始SQL语句的语法,并从标记中形成一种解析树。优化器和代码生成器携手工作,从解析树中生成字节码程序。所有这些神奇的事情都发生在salite3 _prepare API函数的实现中。
查询优化在任何SQL数据库系统中都是一个微妙的问题。大多数实际的数据库系统使用一些启发式方法来达到接近最优的性能,SQLite使用一些简单的优化方案。对于带有where子句的查询,SQLite尝试在表上找到最佳索引,以避免访问所有表中的所有行。本章简要讨论了这些方案。
Chapter 9 SQLite Interface Handler
After reading this chapter, you should be able to explain/describe.
- how all SOLite internal structures are interlinked with the main sqlite3 structure.
在前面的章节中,我已经零零碎碎地介绍了许多控制数据结构。在本章中,我介绍了主要的用户界面结构,即sqlite3。以及它与其他内部控制数据结构的相互关系。本章为您提供了SQLite各种数据结构的内部组织的完整的端到端图片。
9.1 The Importance of Interface
正如前一章所提到的,接口是系统与其环境(即系统用户)之间的契约。它指定了系统将如何与用户交互。在软件中,它是函数和常量声明的命名集合。它还定义了用户和系统之间的通信协议,并定义了这些功能的行为。它描述了系统对环境的输入假设和它提供的输出保证。它是一种不相关的实体用来相互交互的机制。接口的实现构造接口规范中声明的所有函数。接口的目的是最小化使用接口函数的应用程序和实现接口的服务提供者之间的依赖关系。
经过一些实验,SQLite开发团队已经完成了它的大部分接口函数和常量。他们偶尔会添加实验性的接口函数和常量,但要添加新功能。这些新添加的接口函数可能会在以后的版本中进行更改。除了函数之外,SQLite还使用了一些控制结构。控制结构会不断变化,但这些变化不会影响SQLite应用程序。它的主要结构是sqlite3,我将在下一节中讨论它。
9.2 The sqlite3 Structure
当应用程序调用sqlite3 open API函数时,该函数创建并设置一个新的库连接或会话,它还为应用程序创建和/或打开一个数据库文件。该函数创建一个sqlite3类型的对象,并向应用程序返回一个指向该对象的指针。指针表示应用程序的新库连接,sqlite3对象表示SQLite库。应用程序不能篡改对象的任何组件成员变量,并且在连接上进一步调用各种API函数时使用指针作为句柄,直到应用程序成功地在连接上应用sqlite3 _close API函数。我们说连接已关闭,句柄已消失。
sqlite3对象的各种组件如图9.1所示。sqlite3的aDb成员是一个Db类型的对象数组。每个Db对象代表一个打开的数据库文件的实例,也就是数据库连接。在aDb数组中通常有两个Db对象。aDb0是主数据库,aDb1是临时数据库。aDb0对象表示数据库,其名称由应用程序向下传递给sqlite3_open API函数。在sqlite3_open函数调用结束时,这两个Db对象被适当地初始化。其他Db对象(如果有的话)稍后创建,每个附加的数据库一个。(当应用程序将它们从连接中分离出来时,它们将被销毁。)在内部,VM通过到aDb数组的索引号来引用每个数据库,而不是通过数据库名称。名称到索引的转换在代码生成时完成。索引值0(分别为1)总是指向主数据库(分别为1,temp);值大于1表示附加的数据库,sqlite3对象的nDb成员变量表示库连接上当前打开的数据库的数量。

每个Db对象有以下成员变量:(1)zName—-一个指向数据库名称的指针;(2)pBt—-指向一个b树对象的指针,作为句柄在数据库上应用树级函数;(3) inTrans —-数据库上当前事务的类型;(4)pSchema —-指向模式对象的指针。schema对象有以下成员变量:(1)schema_cookie —-数据库模式版本号;(2)cache_size —-页面缓存中使用的页数;(3)tblHash—-所有表;(4)所有索引的idxHash —-;(5)所有触发器的trigHash —-;(6) fkeyHash——用于所有外键;(7) pseqtab -指向qlite_sequence目录的指针;(8)其他许多人。(当SQLite读取数据库文件时,它解析模式并分别为数据库中定义的SQL表/视图、SQL索引、触发器和外键填充四个内部哈希表:tblHash、idxHash、trigHash和fkeyHash。)
每个SQL表在内存中由table对象的一个实例表示(参见图9.2)。aCol是一个表示表的nCol列的对象数组。每个列由column对象的一个实例表示。该节点包含以下字段:(1)zName—-该列的名称;(2)pDflt—-本列默认值;(3)zType—-该列的SQL类型;(4)notNull—-如果存在NOT NULL约束,则为true;(5)isPrimKey—-如果该列是PRIMARY KEY的一部分,则为true;(6)其他许多人。
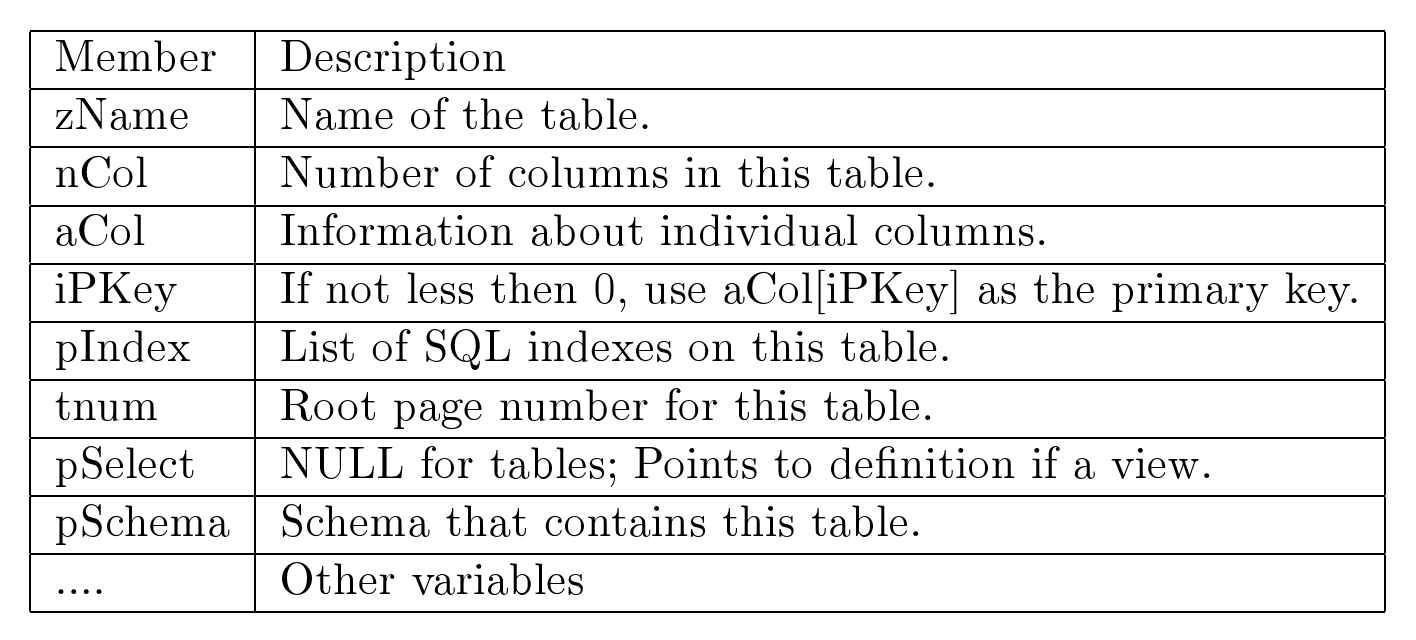
每个索引在内存中由index对象的一个实例表示(见图9.3)。aiColumn是一个包含nColumn整数的数组,其中每个整数标识基表中的一个列;第一列是0。num是索引根所在的页码。
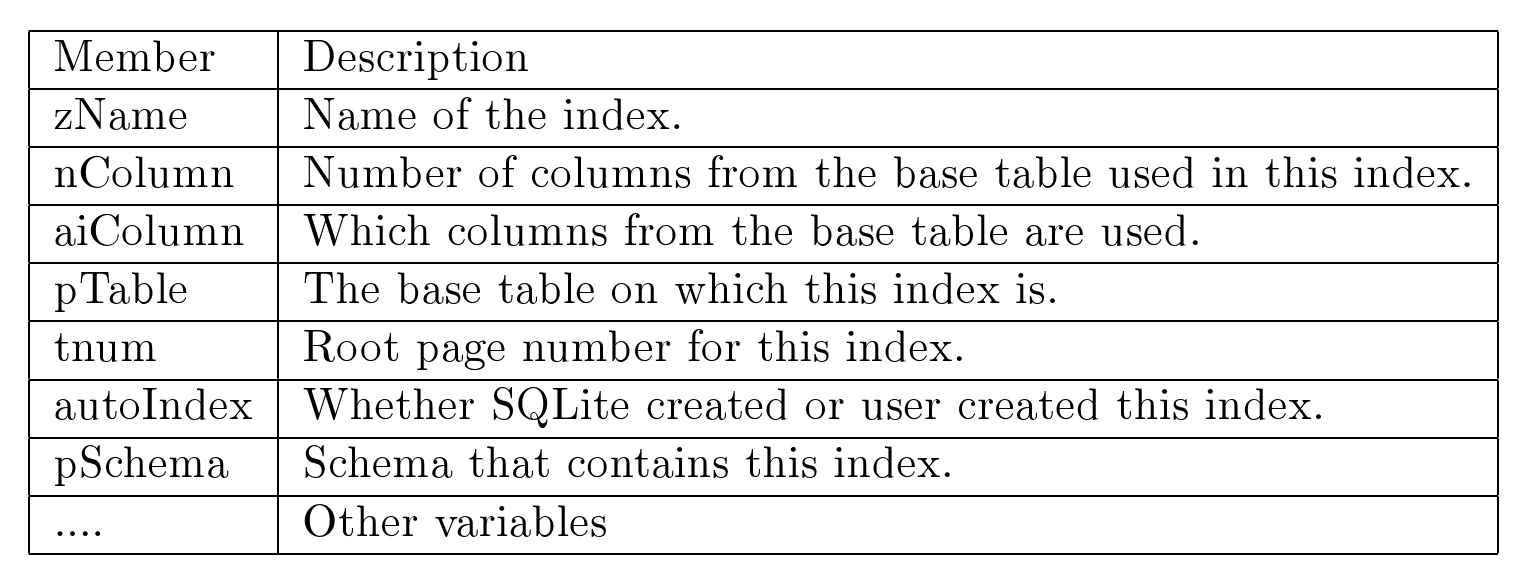
sqlite3对象中的lastwid字段记录了插入语句生成的最后插入行。(视图上的插入不影响lastwid值。)errCode和pErr分别存储最近的错误代码和(如果适用的话)错误字符串。这些标志编码sqlite3对象的各种运行时状态。pVdbe是一个由Vdbe对象组成的桶,每个对象在库连接上表示一个单独编译的SOL语句,也就是字节码程序。每个Vdbe对象都由用户应用程序中的sqlite3_stmt指针直接引用。
9.3 The Final Confguration
应用程序和$QLite数据结构之间的相互链接如图9.4所示。应用程序在sqlite3和sqlite3_stmt指针上应用SQLite API函数。您可能会注意到,SQLite允许应用程序使用它注册各种用户定义的回调函数。如果需要,SQLite会执行这些函数来操作应用程序空间中的数据。
不如图9.4所示,一个应用程序可以有多个库连接(也就是sqlite3*),它们每个都可以有多个打开的连接到相同或不同的数据库。也就是说,一个库连接可以有多个数据库(主数据库、临时数据库和其他附加数据库)与之关联;Db阵列如图9.4所示。每个这样的数据库都是通过一个专用的b树对象访问的,并且该对象有自己的Pager对象。(在共享缓存模式下,Pager对象通过BtShared对象共享为同一个数据库文件创建的多个b树对象。)Pager对象跟踪数据库文件、日志文件、锁、页面缓存等的状态。在任何时候,应用程序在库连接上最多只能有一个活动事务。并且,根据需要,库连接在各个数据库上启动事务。
每个SQL语句(也称为sqlite3_stmt*)都有自己的字节码程序。当执行时,vm打开游标,通过游标访问数据库;图9.4中的VdbeCursor数组。游标引用一个BtCursor来访问单个数据库中的单个B/B+树。一个BtCursor引用一个(表或索引)树,并且可以遍历树中的记录。同一棵树上可以有多个vdbecursor,它们彼此独立。
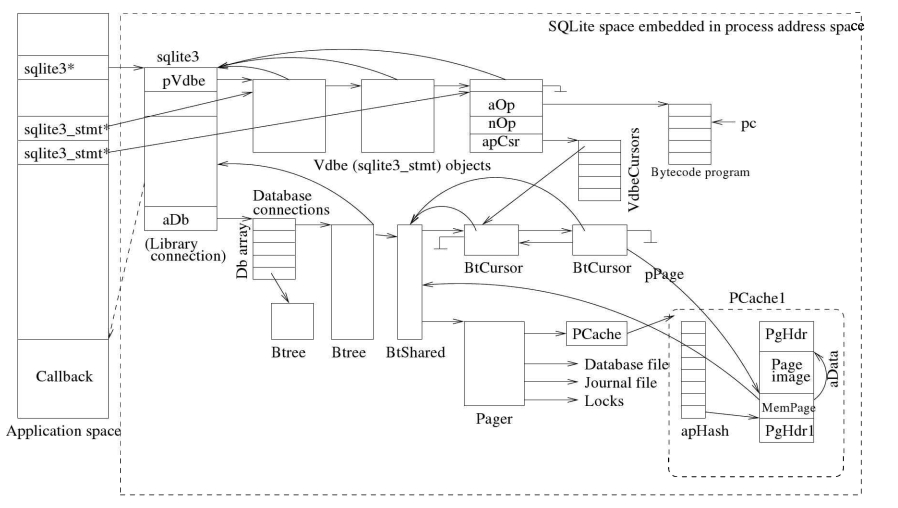
9.4 API Interaction
当应用程序成功调用sqlite3_open API函数时。SQLite创建一个sqlite3对象(在应用程序进程地址空间的堆上)。对象中的pVdbe指针变量为NULL(即空)。当应用程序编译SQL语句时(通过调用sqlite3_prepare API函数),SQLite创建一个准备好的语句对象(类型为/Vdbe),并将其附加到Vdbe列表中。这个预处理语句没有任何与之关联的游标。应用程序调用对象指针(sqlite3_stmt*)上的sqlite3_bind _* API函数来定义参数的值。然后调用sqlite _stmt*上的sqlite3_step API函数来执行字节码程序。在程序执行过程中,虚拟机创建游标,对各个数据库中的B/B+树应用操作。在程序执行结束时,VM关闭并删除那些游标(如果应用程序在准备好的语句上调用salite3_reset API函数,那么它的所有游标也将关闭和删除)。应用程序可以通过在Vdbe对象上应用sqlite3_finalize API函数来销毁该对象(以及它分配的资源)。当它完成所有准备好的语句时,它可以通过对其应用sqlite3_close API函数来销毁sqlite3对象:我们说库连接或会话已关闭。所有与库连接相关的SQLite句柄都将失效。
Summary
本章向你展示了SQLite内部数据结构是如何相互连接在一起来定义sqlite3主接口结构的。为了打开一个库连接,应用程序调用sqlite3_open API函数,这个函数创建一个sqlite3对象。此对象的指针由应用程序使用。这个对象包含所有数据库连接(主连接、临时连接和附加连接)。
Chapter 10 Advance Features
After reading this chapter, you should be able to explain/describe.
- 各种高级SQLite功能,如pragma, view, trigger, collation,子查询,autovacuum等。
- 使用sqlite_sequence编目实现自动增量特性。
- 如何在SQL表达式中使用current_date、当前时间和当前时间戳。
- 如何实现自动真空功能。
- unicode数据是如何处理的SQLite
- WAL日志记录功能是如何实现的
章节简介 RDBMS应该具备的最小特性是对单个表进行简单的插入、删除和选择,当然还有事务的ACID属性。 有了这些最小的特性,您就可以设计出大多数数据库问题的解决方案。但是,应用程序开发可能会变得繁琐和耗时。 大多数rdbms还支持单个表上的更新操作和两个或多个表上的交叉产品操作。SQLite也支持它们,此外,像许多其他rdbms一样, 它支持许多可选的高级特性。SQLite的一个优点是,每个高级特性都是在编译包下实现的。通过在从源代码构建SQLite库时设置适当的标记, 可以单独关闭这些特性。其中一些也可以在运行时关闭。本章将讨论其中的一些特性。
10.1 Pragma
pragma是特殊的SQLite命令,您可以使用它来查询SQLite库以获取内部(非表)元数据,或修改库的默认行为。 SQLite支持许多pragma,每个pragma都有不同的名称,PRAGA命令与其他SQLite命令和SQL语句使用相同的接口发送给SQLite,但在以下重要方面有所不同。
- 如果你发送一个未知的pragma, SQLite不会产生任何错误信息。它忽略未知的pragma。这意味着如果您在pragma命令中犯了一个排版错误,SQLite不会通知您该错误。在拼写pragma名称时需要非常小心。
- 一些pragma命令在编译阶段而不是在执行阶段生效。如果您的应用程序正在使用sqlite3_prepare、sqlite3_step、sqlite3_finalize API函数序列来执行SOL语句,那么这些pragma命令可能只在sqlite3_prepare调用期间应用于库。
- Pragmas不太可能与任何其他SQL RDBMS兼容。将应用程序移植到其他系统可能会变得困难。
有两种方法可以为pragma名称指定值:(1)pragma name = value和(2)pragma name(value);这里的名称是一个编译标识符,值是一个字符串或数字。(另外,‘PRAGMA name ’返回由该名称标识的PRAGMA的当前值。)该名称的前缀可以是数据库名称,后跟一个点。如。, pragma temp.name。接受整数值0和1的pragma也接受符号名;字符串“on”、“true”和“yes”等价于1,字符串“of”、“false”和“no”等价于0。这些字符串不区分大小写,不需要引号。无法识别的字符串将被视为1,并且不会产生错误。例如,考虑一个pragma命令pragma synchronous = OFF。该命令关闭事务的同步日志记录和数据库写入,也就是说,这些事务变成异步事务。当这样的编译返回一个值时,它总是一个整数。
所有的pragmas都可以分为四类基本类型:(1)查询当前数据库模式的pragmas;(2)以某种方式修改SQLite库的操作以查询当前操作模式的pragmas;(3)查询或修改两个数据库版本值(schema-version和user-version)的pragmas;(4)调试库和验证数据库没有损坏的pragmas。目前支持的pragmas包括auto_vacuum, cache_size, case_sensitive_like,count_changes,default_cache_size,empty_result_callbacks,encoding, Full_column_names, page_size, short_column_names, synchronous, temp_store, temp_store_directory, database_list, foreign_key_list, index_info, index_list, table_info, schema。版本,user_version, inegrity_check, parser_trace, vdbe_trace, vdbe_listing。下面我们将讨论几个示例pragma命令。SQLite网页http://www.sglite.org/pragma.html有关于这些和其他pragmas的更多信息。
-
数据库模式查询的Pragmas
- Pragma foreign key_list (table-name)。对于引用参数表中的列的每个外键,此pragma返回一行。
-
修改SQLite库操作的实用程序
-
Pragma auto_vacuum=0、1或2(分别为NONE、FULL或INCREMENTAL)设置auto_vacuum参数的值。默认值为0或NONE。只有在数据库中创建任何表之前,才能修改fag的值。如果在创建了一个或多个表之后尝试修改fag,则不会返回错误消息。这个pragma有一些限制;请参阅http://www.sglite.org/pragma.htmlpragma_auto_vacuum网页。
-
Pragma cache_size= Number-of-pages设置页面缓存大小。当您使用此pragma更改缓存大小时,该更改仅对当前数据库会话有效。当数据库连接关闭并重新打开时,缓存大小恢复为默认值。您可以使用default_cache_size pragma来永久更改缓存大小。一旦设置了默认缓存大小,设置值将被保留,并在每次重新打开数据库时重用。
-
-
Pragmas for querying or modifying the database versions
- Pragma schema_version = integer value和Pragma user_version = integer value分别设置schema_version和user version的值。模式版本和用户版本都是存储在数据库头中的32位带符号整数。模式版本通常只由SQLite在内部操作。每当数据库模式被修改(通过创建、修改或删除表或索引)时,它就会增加。SQLite在每次执行查询时使用模式版本,以确保在编译SQL查询时使用的模式的内部缓存与实际执行编译查询的数据库的模式匹配。通过使用pragma schema_version修改模式版本来破坏这种机制是潜在的危险,并且可能导致程序崩溃或数据库损坏。谨慎使用这个pragma。我警告过你了!用户版本不被SQLite内部使用,它可以被应用程序用于任何目的,例如,为了备份目的而跟踪数据库文件的版本。
-
Pragmas for debugging the library
- 编译指示integrity_check。该命令对整个数据库进行完整性检查。它查找乱序记录、缺页、格式错误的记录和损坏的索引。如果发现任何问题,则返回一个字符串,该字符串描述了所有问题。如果一切正常,则返回“ok”。
10.2 Subquery
一个简单的SQL选择语句是select x from y where z,其中x是属性或表达式列表,y是表列表,z是布尔表达式。SQL的一个强大特性是,z本身可以包含作为另一个选择语句的SQL(子)查询。例如,在select name from Students where sid in (select sid from Admitted to where doj=‘Jan 01, 2000’)中,括号中的语句是一个简单的子查询,它本身就是一个独立的sql查询。并且可以独立执行。这样的子查询也可以出现在from-和groupby的having子句中。在执行完整查询时,子查询只执行一次
SQLite也支持相关子查询。关联子查询是嵌套在另一个SQL选择中的SQL选择语句,其中嵌套的子查询包含对外部选择中的一个或多个列的引用。它是一个依赖子查询,不能单独执行。下面是一个简单的关联查询示例:select name from Students where exists (select * from Admitted to where sid = Students)。sid and doj= ‘Jan 01, 2000’)。这里,嵌套子查询引用student。sid列。
相关子查询依赖于外部查询。子查询将在处理外部查询时执行多次,对于外部查询选择的每个候选行,子查询将运行一次。在相关子查询中引用的外部查询中的列在每次执行子查询之前被替换为候选行中的值。根据子查询执行的结果,VM决定是否将候选行放入完整查询的结果集中。
10.3 View
视图是一个虚拟表,它的行没有显式地作为独立的存在单独存储在数据库中,而是根据需要从一个或多个基表派生。 也就是说,视图不是持久化表;它们的内容是在使用时动态生成的。 是一个虚表,SQLite为其存储一个纯查询定义,该定义用于在运行时派生视图的行集。 视图通常用于向用户显示必要的信息,同时将详细信息隐藏在基础表中。出于查询目的,视图几乎被视为普通表。 用户通常无法分辨他们访问的是视图还是表。在视图上应用查询时,SQL的行为就像将查询应用于由视图定义在该时间点派生的新临时表一样。
视图提供了某种模式独立性。如果基表定义被更改(例如,添加一个新列),视图定义可能不会受到影响。访问视图的应用程序不会受到影响,但访问基表的应用程序可能会受到影响。
SQL构造create view view1作为select name, sid from Students是一个典型的创建视图语句。create view语句为预封装的select语句指定一个名称,并将这一行(view, view1, view1,0, create view view1 as select name, sid from Students)插入到sqlite主编目表中。一旦创建了视图,就可以在另一个SELECT的FROM子句中使用它来代替表名。例如,select name from view1 where sid = 1001返回sid值为1001的学生的名字。视图定义的模板是create [temp | temporary] view [database-name .]view-name as select-statement。(除非数据库名称本身是temp,否则不能在视图定义中同时使用temp/temporary和database-name。)
虽然SQL语义允许更新视图,但SQLite禁止这样做。因此,插入、更新和删除不适用于视图。SQLite允许你在视图上创建一种特殊的触发器,通过它你可以更新基表。参见230页10.5节。
通过在create语句中将temp或temporary关键字放在create和view关键字之间,SQLite允许创建临时视图。临时视图仅对库连接可见,并在库连接关闭时自动删除
10.4 Autoincrement
在用户表中,如果将一列声明为INTEGER PRIMARY KEY,该列将自动递增。我的意思是,每当在表中插入一行时向该列插入SQL NULl值(或者不为该列指定任何值),NULl或缺席值就会自动转换为(64位符号)整数。整数值通常为1,大于该列在表中所有其他行的最大值,如果所有现有值都为负,则为0,如果表为空,则为1。例如,假设您有一个表,它由以下命令创建:create table t1(a INTEGER PRIMARY KEY)。语句insert into t1 values(NULL)逻辑上变成insert into t1 values(select max(a) from t1)+1)。嗯,在大多数情况下。
备注: rowid的最大值为9,223,372,036,854,775,807。如果这个值目前在表中,那么SQLite随机选择一个未使用的正值。然而,SQLite只尝试选择一些值。如果所有尝试都失败,则返回SQLITE_FULL错误码。
新值在列中当前的所有值中肯定是唯一的,但它可能是先前从列中删除的值。如果希望在表的整个生命周期中都有唯一的值,则需要将AUTOINCREMENT关键字添加到INTEGER PRIMARY KEY声明中,即将该列声明为INTEGER PRIMARY KEY AUTOINCREMENT。那么SQLite选择的值肯定会比该列中存在的最大值大1。如果该列中先前存在最大可能值,则所有新insert都将失败,并显示SQLITE_FULL错误码。
SQLite维护了一个可选的目录表,名为sqlite_sequence,用于跟踪具有显式自增列的表的值,序列目录的模式如下:CREATE table sqlite_sequence(name, seg),其中name是表名,seq是该表所使用的整型主键的最大值。对于每个这样的表,编目都有一行保存为表中的自动递增列发出的最大值。(您可能会注意到,一个表不能有多个自动递增列。)默认情况下,在SQLite数据库中可能不存在序列表,序列表是在您第一次向具有自动增量列的表中插入一行时创建的。每当具有自动增量列的用户表接收到第一次插入时,SQLite初始化一行并将该行插入序列编目。随后的SQL插入到这样的表中可能需要更新序列表中相应的行。当用户表被删除时,序列目录中相应的行也被删除,SQLite允许您使用普通的UPDATE、INSERT和DELETE语句修改序列目录的内容。但是对该表进行修改可能会干扰AUTOINCREMENT值生成算法。我警告过你了!
10.5 Trigger
触发器是在数据库(例如大学数据库)中发生某些事件(例如指定的更改)时由DBS自动执行的过程。如果学生在一个学期中有两门或两门以上的课程不及格,则会在幕后启动终止命令。
SQL触发器语句有三个部分:(1)事件、(2)条件和(3)操作。事件标识在触发器生效之前或之后执行的SQL(插入、删除或更新)语句。我们说事件触发了触发器。在每次这样的激活中,DBMs都会评估触发器的条件,如果满足条件,则开始执行触发器操作。触发器操作由一个或多个SQL选择、插入、删除和更新语句组成,它们可以引用元组的旧值和新值来执行操作。
create trigger语句用于向数据库模式添加触发器。触发器语句的模板如下:create [temp | temporary] trigger [database-name .] trigger-name [before l after |instead of] database-event on table-name trigger-action(删除表时会自动删除触发器)。trigger-name是在指定的数据库事件发生之前或之后激活的触发器的名称。可以将触发器指定为在特定数据库表上发生DELETE、INSERT或UPDATE操作时触发,或者在表的一个或多个特定列上发生UPDATE操作时触发。
触发动作有两种标准形式:FOR EACH ROW和FOR EACH STATEMENT,从SQLite 3.7.8版本开始,SQLite只支持FOR EACH ROW触发器。(因此显式指定FOR每一行是可选的。)FOR EACH ROW子句后面跟着一个可选的WHEN子句。触发器的动作是一个选择、更新、插入和删除的序列;由关键字begin和end包围的SQL语句;这些动作语句都称为。trigger-step。一个触发动作必须至少有一个触发步骤。FOR EACH ROW意味着,对于插入、更新或删除的每一行,触发触发器的语句都可能执行触发步骤(取决于WHEN子句)。WHEN子句和触发器步骤都可以访问正在插入或删除的行中的元素。或使用“NEW,column-name”和“OLD”形式的引用进行更新。column-name”,其中column-name是与触发器关联的表中的列的名称。OLD和NEW引用只能在与它们相关的触发事件上使用,如下所示:
- INSERT:only NEW references are valid.
- UPDATE: NEW and OLD references are valid.
- DELETE:only OLD references are valid.
如果提供了WHEN子句,则仅对WHEN子句为真的那些行执行触发步骤。如果没有提供WHEN子句,则对所有行执行触发步骤。指定的触发时间(之前或之后)决定相对于相关行的插入、更新或删除何时执行触发步骤。
通过在CREATE TRIGGER语句中指定INSTEAD OF,可以在视图上创建触发器,也可以在普通表上创建触发器。虽然SOLite不允许更新视图,但是如果在一个视图上定义了一个或多个INSERT、DELETE或UPDATE触发器,那么分别在视图上执行INSERT、DELETE或UPDATE语句并不是错误的;在视图上执行它们会触发关联的触发器。视图底层的基表不会被修改(除非可能由触发器程序显式地修改)。
假设您有一个“customers”表,其中存储客户信息,还有一个“orders”表,其中存储订单状态信息。以下触发器确保在客户更改其地址时重定向所有相关订单:
CREATE TRIGGER update _customer _address UPDATE OF address ON customers
BEGIN
UPDATE orders SET address= new.address WHERE customer _name = old.name;
END:
有了数据库中可用的这个触发器,当您执行诸如update customers set address =‘364 0live Avenue ' where name= ‘Sibsankar‘这样的语句时,触发器被触发,它在后台执行更新订单set address =’364 0live Avenue ' where customer name= ‘Sibsankar’。
您可能会注意到,目前,在具有INTEGER primarykey字段的表上创建触发器时,触发器的行为可能会很奇怪。如果BEFORE触发器程序修改了一行的INTEGER PRIMARY KEY字段,该字段随后将由触发触发器的语句更新,那么更新可能不会发生。为了避免这种情况,需要使用PRIMARY KEY列而不是INTEGER PRIMARY KEY列来声明表。
递归触发器:在默认设置中,SQLite不支持递归触发器,但支持级联触发器。也就是说,一个触发器执行的操作不会导致同一个触发器触发,尽管它可能会触发另一个触发器。不过,您可以使用recursive_triggers pragma来激活递归触发器
10.6 Date.Time,and Timestamp
SQLite将所有日期和时间处理为儒略历日数,儒略历日数是表示天数的实数。根据公历系统,它将日期和时间存储为从格林威治时间公元前4714年11月24日中午开始经过的天数。这个特殊的时刻是朱利安日0.0。负数和正数分别表示该时刻之前和之后的日期。
SQLite实现的日期/时间转换算法基于[-16]中的描述;SQLite支持五个与日期和时间相关的函数:julianday, date, time, datetime和strftime。这五个函数接受一个时间字符串作为参数;时间字符串后面可以有零个或多个修饰符。strftime函数还接受一个格式字符串作为它的第一个参数。date函数以这种格式返回日期:YYYY-MM-DD。time函数返回的时间格式为HH:MM:SS。datetime函数返回YYYY-MM-DD HH:MM:SS。julianday函数返回从公元前4714年11月24日格林威治中午算起的天数。strftime例程返回根据第一个参数指定的格式字符串格式化的日期(请参阅linux手册中的strftime)。5函数的输入时间字符串可以是下列格式之一。
- YYYY-MM-DD
- YYYY-MM-DDHH:MM
- YYYY-MM-DD HH:MM:SS
- YYYY-MM-DD HH:MM:SS.SSS
- YYYY-MM-DDTHH:M
- YYYY-MM-DDTHH:MM:SS
- YYYY-MM-DDTHH:MM:SS.SSS
- HH:MM
- HH:MM:SS 10 HH:MM:SS.SSS
- now
- DDDD.DDDD
在格式5-7中,‘T’是分隔日期和时间的文字字符(参见ISO8601标准)。格式8-10只指定相对于默认日期2000-01-01的时间。格式11,字符串‘now’,被转换为当前日期和时间:通用协调时间(UTC)用于估计日期,格式12是用浮点值表示的朱利安日数
在五个date/time函数中,time字符串参数后面可以跟着零个或多个修饰符,这些修饰符可以更改日期或更改日期的解释。这些修饰符按照它们在输入中出现的从左到右的顺序应用。可用的修饰符如下。
- NNN days
- NNN hours
- NNN minutes
- NNN.NNNN seconds
- NNN months
- NNN years
- start of month
- start of year
- start of week
- start of day
- weekday N
- unixepoch
- localtime
- utc
大小修改器(项目1-6)将给定的时间量(+NNN)添加到给定时间字符串指定的日期。‘start of ’修饰符(7-10项)将日期向后移动到当前月、年或日的开始。‘weekday ’修饰符(项目11)将日期向前推进到下一个工作日编号为n的日期(周日为0,周一为1,依此类推)。‘unixepoch’修饰符(item12)仅在紧跟DDDD中的时间字符串时才有效。DDDDD格式。这个修饰符导致DDDD,DDDDD不像通常那样被解释为儒略历日数,而是自1970年以来的秒数。此修改器允许将基于unix的时间轻松转换为儒略历日数字。“localtime”修饰符(项目13)调整给定的时间字符串,使其显示正确的本地时间。‘utc ’修饰符(第14项)撤消此操作。
上面提到的五个日期和时间函数是可选的,可以在SQLite源代码编译时全部省略,SQLite在SQL级别支持三个特殊的日期和时间特性,尽管它们总是可用的:current_date, current timend current_timestamp。这三个标识符可用于SOL表达式或指定表列的默认值。该值是当时的UTC日期和/或时间。对于current_time,格式为HH:MM:SS,对于current_date,格式为YYYY-MM-DD,对于current_timestamp,格式为yyyy - dd HH:MM:SS。
SQLite webpage http:/www.salite.org/cvstrac/wiki?p=DateAndTimeFunctions has more abouate and time functions. a few examples of date/time functions are given belowe
- select date(0)returns -4713-11-24.
- select date(‘now’)returns the current date in YYYY-MM-DD format.
- select date(‘now’,,start of month’,’+1 month’,’-1 day’) returns the last day of the current month.
- select datetime(0)returns -4713-11-24 12:00:00. This date and time are represented byJulianday 0 according to the Gregorian calendar system.
- select datetime(1092941466,‘unixepoch’) returns the date and time for the given Unixtimestamp 1092941466.
- select julianday(,2000-01-01 00:00:00’)return 2451544.5
- select current_timestamp returns the current date and time
- create table t1(a int,b text not null default current date) indicates that Nllor omitted values for the b column will be converted to the then value of current_date.
日期、时间和时间戳的存储类型: 日期、时间和时间戳没有单独的存储数据类型。根据不同的情况,它们的值存储为TEXT (IS08601字符串),格式为“YYYY-MM-DD HH:MM:SS”。SSSS”格式),INTEGER (Unix时间)或REAL(Julian历日数),QLite使用内置的日期和时间函数来适当地转换日期/时间/时间戳。
10.7 Reindex
Reindex是一个SQLite命令,用于在一次操作中从头开始删除和立即重新创建索引。当排序序列的定义发生变化时,此命令非常有用。reindex命令有三种形式:(1)reindex collation-name在直接或通过基表使用命名排序序列的所有(包括附加的)数据库中重新创建所有索引。(2)重索引table-name重新创建指定表的所有索引。(3)重索引index-name只重新创建指定索引
10.8 Autovacuum
就空闲数据库页面的管理而言,默认的数据库操作模式是非自动真空的。当从活动使用中释放页面的事务提交时,数据库文件在提交处理结束时保持相同的大小。未使用的数据库页面保留在自由列表中,并在以后将新数据插入数据库时重用。所有空闲页都链接在一个单一的树干树中,起源于偏移量32的文件头记录(参见第89页的图3.5)。在默认操作模式下,您需要显式地执行vacuum命令,清除自由列表并收缩数据库文件,并将这些空闲页面释放回本机文件系统。您可能会注意到,vacuum命令不能在usr事务中执行,也就是说,不能在开始和结束命令中执行。它被称为手动真空。
SQLite有一个特殊的特性,叫做autovacuum,它可以在源代码编译时打开,也可以在运行时通过pragma命令[-2]打开。在autovacuum模式下,如果一个事务从活动使用中释放了一些页面(在sql删除或更新中),SQLite在提交事务时将这些或许多页面返回给本机文件系统。在事务执行期间,如果它释放了任何页面,则这些页面将包含在正常的自由列表中。在提交处理的最开始,将文件中等量的空间释放到本机文件系统。vacuum命令在设置了autovacuum标志的数据库中不可用。
到目前为止,没有本机文件系统从文件中间释放空间,因此,SQLite不能将任意释放的页面释放回本机文件系统。数据库文件只能收缩,因此,可以释放到本机文件系统的页面总是必须来自文件的尾部,并且SQLite可能需要在将它们释放到本机文件系统之前从尾部重新定位一些有效的页面。重定位是一种特殊的压缩,其中SQLite将有效的数据库页面与空闲页面交换。您可能会注意到,还有其他数据库页面可能会引用重定位页面,因此重定位可能需要更新其他页面中的内容,这些页面包含指向重定位页面的指针。SQLite将页重定位信息存储在文件本身的单独页面中。(为了支持这个特性,数据库将额外的信息存储在单独的页面中,从而导致数据库文件稍微大一些。)这些被称为指针映射页。它们与其他数据库页面穿插在一起。指针映射的目的是方便将页从文件中的一个位置移动到另一个位置,作为自动真空的一部分。移动页面时,必须更新其父页中指向该页的指针,使其指向新位置。(您可能还记得,在常规的树页面中,SQLite存储子页面和溢出页面的信息,而不是其他方式。指针映射页用于保存从子节点到父节点的“其他方式”链接信息。指针映射用于快速定位父页。
指针映射页共同定义了一个查找数据结构,该结构标识数据库文件中每个子页的父页。(父页是包含指向子页的指针的页。)SQLite设计的美妙之处在于数据库中的每个页面最多有一个父页面。(在这种情况下,“数据库页”是指不属于指针映射本身的任何页面。)指针映射页包含一个5字节条目的数组。每个条目由一个1字节的“类型”和一个4字节的父页码组成。以下是有效的类型。
-
PTRMAP ROOTPAGE:数据库页是树的根页。在本例中不使用父页编号,因为根没有父页编号。(您可能还记得,除了第1页之外,所有其他根页号都存储在主目录中。)父页码应为0。
-
PTRMAP BTREE:数据库页面为非根树页面。父页编号标识树中的父页。
-
PTRMAP_OVERFLOW1:数据库页是溢出页列表中的第一页。父页编号标识包含单元格的页,该单元格具有指向此溢出页的指针。
-
PTRMAP_OVERFLOW2:数据库页是溢出页列表中的第二个或更晚的页。父页码标识溢出页列表中的前一页。
-
PTRMAPFREEPAGE:数据库页面是一个未使用的(空闲的)页面。在本例中不使用父页编号,该号码应该为0。
图10.1显示了一个典型的数据库文件中指针映射页面的位置,总共有415个页面。您可能注意到第1页是特殊的,它不是指针映射的一部分。其余的页面组织在简单的(指针映射)段中。所有的段都是相同的大小,除了最后一个可以有更少的页面。每个段以一个指针映射页开始,然后是n(=该页上的可用空间除以5)个数据库页,这些数据库页的映射信息存储在指针映射页上。如图所示,黑体框是指针映射页面。假设页面大小为1024字节,并且所有字节都可用;一个指针映射页面最多可以有1024/5(=204)个映射条目。如图2所示,Page 2是一个指针映射页面,它存储了Page 3、Page 4、Page…给定一个数据库页码,SQLite定义两个宏,即PTRMAP PAGENO和PTRMAP_PTROFFSET,它们分别确定指针映射页码和页面中的偏移量,其中存储了给定数据库页面的父级信息。PTRMAP PAGENO宏实际上是由btree.c源文件中的potrmapPageno函数实现的。
Note: In case a pointer-map page clashes with the lock-byte page, that particular pointer-map page istored in the page following the lock-byte page.

在自动清空期间,只要有空闲页面,SQLite就会执行以下操作。假设页面i是空闲的,其中i>1且i< m, m是最大页数。我们可能需要将页m的内容重新定位到页i。如果m是指针映射页或空闲页,则从文件中删除该页,不需要重新定位该页。否则,SQLite执行以下操作。设PTRMAPPAGENO(m)为j。也就是说,页j包含了页m在偏移量PTRMAP_PTROFFSET(m)处的指针映射信息。页m的家长信息在那里可用。如果它是根页,我们不能再清空文件,因为SQLite不会重新定位根页。(见下文注释。)否则,我们从指针映射页j获取父信息,并相应地更新父页中的子指针。在这两种情况下,SQLite更新。现在保存当前页m副本的第i页的指针映射信息。另外,更新第i页现在指向的所有页面的指针映射信息。从文件中删除页m。
Note: When this feature is on, all B-/B+-tree root pages are stored preceding all non root pages, overflovpages, and free pages. This ensures that root pages are not relocated during autovacuum.<
10.9 Attach and Detach(连接和分离)
应用程序通常在单个数据库文件上工作。它通过指定数据库文件名打开到SQLite库的连接。如果需要,您可以通过执行SQLite命令attach database-filename AS database-name,将另一个或多个数据库文件添加到库连接中,并通过执行detech database-name命令[-3]从库连接中删除附加文件,如果附加的文件不存在,则使用attach命令自动创建该文件。当库连接关闭时,附加的文件将自动分离。
[-3]如果文件名中包含标点符号,必须加引号。数据库名可以是除‘main ’和‘temp ’以外的任何字母数字字符串,它们分别引用主数据库连接和用于临时表的数据库。不能手动从库连接中分离这两个数据库。
SQLite允许将相同的数据库文件多次附加为不同的数据库名称(前提是系统没有以共享缓存模式运行)。但是,使用相同的数据库名称附加许多(相同或不同)数据库文件是错误的。附加的数据库文件的最大数量限制为62个,(该值在AX attached编译宏中设置:deefault为10,)有一个限制,即attach和detach命令不能在用户事务中执行;也就是说,主数据库必须处于自动提交模式。附加数据库上的默认事务恢复模式始终是同步的,即使主数据库被设置为异步。在运行时,每个附加的数据库都有自己的b树对象,VM通过该对象访问数据库。更重要的是,在默认操作模式下,附加的数据库不共享单个页面缓存,即使它们是相同的数据库文件。
attach命令允许您使用多个独立的数据库,并在同一个查询中一起使用它们。并且,该命令可以帮助您避免在多个数据库的表之间手动传输数据。您可以对附加数据库进行读写操作,还可以修改附加数据库的模式。在SQL级别,SQLite不识别数据库文件名,您需要指定附加的数据库名称。可以使用database-name.table-name语法显式引用附加数据库中的表。但是,在某些情况下,可以隐式地引用表,而无需提供前缀数据库名称。如果附加表在主数据库、临时数据库或其他先前附加的数据库中没有重复,则该表不需要数据库名称前缀限定符。当附加一个数据库时,所有没有重复名称的ofts表(在其他数据库中)都成为具有这些名称的“默认”表。后面附加的这些名称的任何表都需要数据库名称前缀。如果给定名称的“默认”表被分离,则该名称的第一个表被附加为。新的默认表。话虽如此,SQLite遵循以下搜索规则来解析隐式表名。搜索顺序是首先是TEMP,然后是MAIN,然后是使用ATTACH命令按附件的顺序添加的任何辅助数据库。这是第一个算法,也就是说,使用第一个匹配表,不检查重复的表名。(应用程序开发人员已被警告!在表名前加上数据库名总是最好的选择。)同样的规则也适用于解析其他模式名称
当执行不带数据库名前缀的非临时create table语句时,默认情况下该表将在主数据库中创建。通过提供数据库名称作为前缀,可以在任何附加的数据库中创建新表,例如,创建表DB1。T1(a, b,c)语句在DBl数据库中创建Ti表。没有用于单个附件的并行临时数据库
涉及多个附加数据库的事务是原子的,假设主数据库不是‘:memory:’(也不是临时文件)。如果主数据库是‘:memory: ’,那么事务在每个单独的数据库文件中继续是原子的。但是,如果应用程序或主机在更新两个或多个数据库文件的COMMIT过程中崩溃,则其中一些文件可能会得到更改,而其他文件可能不会。
10.10 Table Level Locking
SQLite只支持文件级锁定。也就是说,就锁定粒度而言,整个数据库文件是单个单元。您可以通过修改数据库和应用程序来利用有限形式的表级锁定。您可以拆分数据库并将不同的用户表存储在不同的数据库文件中,这些单独的文件可以通过使用ATTACH命令附加到主数据库连接上,并且合并后的数据库将在“逻辑上”作为一个数据库运行。但是锁只会根据需要在单个数据库文件上获取。因此,如果您将“数据库”重新定义为两个或多个数据库文件,那么两个线程(或进程)当然可以同时写入相同的逻辑数据库(在不同文件中的不同表中)。访问两个或更多附加数据库的事务是ACID,它们将具有更高级别的并发性。
然而,这种方法有一些开销。首先,同一个逻辑数据库有多个数据库文件。其次,事务处理时间明显增加,因为您需要打开多个数据库文件及其回滚日志文件。有些提交操作可能很慢,因为它们需要处理一个主日志文件。每个数据库文件都有自己的页面缓存,因此存在内存开销
10.11 Savepoint
保存点被命名为事务,它们可以嵌套。可以通过执行savepoint命令启动保存点。该命令以保存点的名称作为输入。该名称不必在所有现有保存点中是唯一的:它将覆盖具有相同名称的前一个保存点。SQLite允许在用户事务内部或外部启动保存点。对于后一种情况,SQLite在内部将其视为开始延迟事务。应用程序可以通过执行ROLLBACK to命令将数据库状态恢复到先前设置的保存点。您可能会注意到‘rollback ’和‘rollback to ’命令之间的区别。后者不中止交易;它只撤消部分数据库操作。它取消当前数据库状态与指定保存点之间的所有中间保存点。要提交一个保存点及其前面的保存点,您可以使用保存点名称作为参数执行release命令。当你建立一个保存点时,SQLite不会在语句子事务提交结束时删除语句日志,因为当你执行回滚到命令时需要日志
10.12 n-memory Database
要打开内存中的数据库,我们使用flename “:memory:",在sqlite3 _open API函数调用中。内存数据库不使用任何文件来存储任何类型的信息:它们和它们的日志完全存储在主内存中,并且每个实例都与其他实例不同。所以数据库操作非常快。当应用程序关闭一个内存数据库时,它将从主内存中消除。内存数据库不能跨进程共享。内存数据库也有缺点。您需要大量内存来保存整个数据库,此外,使用内存数据库可能存在风险。如果应用程序进程或系统崩溃,您将丢失所有数据
10.13 Shared Page Cache
在默认操作模式下,SQLite不允许共享为不同数据库连接打开的数据库文件的页面缓存,即使这些连接是由同一线程打开的。因此,SQLite对通过不同数据库连接打开的同一个数据库文件使用多个页面缓存,这可能会导致小型设备上应用程序的空间限制;比如手机。当这个(共享页面缓存)特性被启用时,如果一个线程打开多个连接到同一个数据库(通过不同的库连接),所有的数据库连接共享一个页面缓存;它们还共享为数据库创建的内存模式缓存(即目录对象)。因此,这降低了内存压力和I/0需求。最近(从SQLite 3.5.0版本开始),同一个页面缓存可以由同一进程中的多个线程共享。(当此功能开启时,SQLite不会通过相同的库连接多次打开相同的数据库。)
到目前为止,共享缓存是一个进程范围的特性。与默认操作模式一样,每个数据库连接都有自己的Btree对象。但是,对象没有自己独立的Pager对象。这些Btree对象共享一个BtShared对象,该对象保存着Pager对象(见图10.2),其中进程1中的Pager对象保存着共享的页面缓存。BtShared。nRef变量计算拥有这个BtShared对象的b树的数量。(图中未显示,模式、缓存也是共享的。)SQLite维护一些额外的信息来跟踪所有打开的数据库。当线程打开一个数据库时,SQLite搜索打开的数据库列表。如果。匹配后,新连接共享现有的BtShared对象,而不需要调用sqlite3PagerOpen函数来打开数据库,(前面提到的搜索实际上是在salite3BtreeDpen函数中完成的,并且,进程的所有BtShared对象都通过全局指针salite3SharedCacheList单独链接在一起。)
进程可以通过调用salite3_enable_shared_cache API函数(参数分别为非零和零)来启用和禁用缓存共享。进程可以随时调用这个函数。但是当前的数据库连接不受此调用的影响。它的效果在接下来对sqlite_open api函数的调用中具体化
共享缓存的所有数据库连接看起来都是进程外部的单个连接。不同进程(不使用共享缓存)对数据库访问的同步是通过正常的SQLite锁定方案完成的,如图10.2所示。SOLite使用文件锁定方案来同步两个进程对数据库的访问。通过共享缓存对同一数据库的访问(来自所有对等线程)的同步是由不同的锁定方案完成的。共享缓存锁定模型有三个级别:事务级锁定、表级锁定和模式级锁定.

10.13.1 Transaction level locking
您可能还记得,在数据库连接上,应用程序可以打开两种事务,即读事务和写事务。这可能不会明确地完成;事务隐式地作为读事务启动,直到它第一次写入数据库,此时它被转换为写事务。单个数据库连接可以有一个写事务以及一个或多个并发读事务。然而,这里有一个限制。在任何时候,通过单个共享缓存的所有数据库连接中最多有一个可以打开写事务。然而,这个写事务可以与通过共享缓存访问同一数据库文件的其他连接中的任意数量的读事务共存,但是通过不同的页面缓存访问同一数据库文件的其他连接由于与其他写事务冲突而不能有任何读或写事务。
注意: 出于并发控制目的,所有事务中最强的事务对外部进程是可见的
10.13.2 Table level locking
当许多连接使用共享缓存时,将使用内部(非文件)锁定方案以每个表为基础序列化并发访问。有两种类型的表级锁:“读锁”和“写锁”,这些锁在任何时候都被授予数据库连接,数据库连接在每个数据库表上都有无锁、读锁或写锁。锁是BtLock类型的对象,BtLock的组成如图10.3所示。pBtree组件表示持有树上的eLock的数据库连接,该树的根位于数据库页面上。所有BtLock对象形成一个从BtShared_pLock指针开始的单链表。

在任何时候,一个表可以有任意数量的活动读锁或一个活动写锁。在从表中读取数据之前,连接首先获得表上的读锁。在向表中写入数据之前,连接首先获得表上的写锁。如果无法获得所需的表锁,则请求失败并将SQLITE_LOCKED返回给调用方,只有在当前事务完成时才释放表锁。因此,对于一个应用程序进程,可以在一个表上激活多个读事务或单个写事务。写事务永远不能更新正在被读事务访问的表:只要读事务持有表上的锁,这就确保了可重复读取属性
read-uncommitted Isolation: 在这种隔离模式下(通过read_uncommitted pragma设置),读事务不会获得表上的读锁,因此可以并发地读被写事务写的表。由于没有在表上获得读锁,所以读未提交事务是非阻塞的,也不会阻塞写事务。
10.13.3 Schema(sqlite master)level locking
sqlite_master表支持共享缓存读写锁的方式与所有其他表相同(如前一小节所述)。以下附加的特殊规则也适用于主表。
-
数据库连接必须在访问任何数据库表或获得任何其他读或写锁之前获得sqlite主表上的读锁。(此规则也适用于读取未提交的事务。
-
在执行修改数据库模式的语句(例如CREATE或DROP TABLE语句)之前,数据库连接必须在sqlite _master表上获得写锁。
-
如果任何其他连接持有主数据库或任何附加数据库的sqlite_master表上的写锁,则数据库连接可能不会编译SQL语句。
10.14 Security
数据库可能包含有关组织的有价值的信息。DBMS需要保护存储在数据库中的信息,通常,对于企业数据库,并不是所有用户都被授权访问数据库中的所有数据。与数据库安全性相关的有三个方面。
-
保密:用户必须不能看到未经授权的信息。
-
完整性:用户不能修改未经授权的数据。
-
可见性:用户必须只能看到她被允许看到的内容。
有两种方法可以确保数据库安全性:(1)$QL控制结构和(2)加密。授权约束或安全策略指定用户可以对数据库对象(如表)执行哪些操作。sql grant语句指定用户可以在哪些表上执行什么操作。不幸的是。SQLite不支持标准的授予和撤销SQL安全特性,因为SQLite数据库本身没有“数据库用户”的概念。
SQLite将整个数据库存储在一个普通的本机文件中,该文件可以位于本机文件系统目录的任何位置。由于SQLite可嵌入到应用程序进程地址空间中,因此对数据库文件的访问权限由本地操作系统/文件系统保护方案控制。SQLite使用这种保护方案。因此,具有读取文件权限的用户可以从数据库读取任何内容。对文件和容器目录具有写权限的用户可以更改数据库中的任何内容。常用的grant和revoke SQL语句在嵌入式数据库系统中是没有意义的,因此数据库容易受到安全威胁。
SQLite有一个API函数,即sqlite3_set_authorizer,用于向sqlite3连接句柄注册安全回调函数。(您可能会注意到,它不是一个完整的安全措施)回调是在SQL语句编译时(而不是在运行时)调用,每次尝试访问数据库中表的一列,以验证用户对数据库的各个字段具有读和/或写访问权限。具有库连接的所有附加数据库都使用相同的授权函数。安全回调函数的注册使所有当前准备好的语句无效
安全回调的签名是:int xAuth(void* p1, int p2, const char* p3,const char* p4,const char* p5, const char* p6)。第一个参数是在调用授权器函数时向SQlite库注册的授权句柄。第二个参数是指示授权检查类型的SQLite常量;该值表示授权何种操作(例如,创建/删除表、索引、触发器、视图)。auth函数的第三个和第四个参数分别是正在访问的表名和列名,或者为空。第五个参数是表所在数据库的名称(例如main、temp)。第六个参数是授权上下文;它是负责访问尝试的最内部触发器或视图的名称,如果该访问尝试直接来自输入SQL语句,则为NULL。除了第一个参数外,其他参数的值都是由SQLite在运行时准备的。auth函数应该返回下列值之一:(1)如果允许访问,则SQLITE_OK;(2)如果返回一个错误码,整个SQL语句应该被终止,SQLITE DENY;或者(3)SQLITE_IGNORE,如果SQL语句应该运行,但是尝试读取指定的列将返回NULL,并且尝试写该列将被忽略。将auth函数设置为NULL将禁用此安全检查。在缺省操作模式下,auth函数为NULL
SQLite支持可选的专有加密技术来保护数据库中的信息。支持RC4、AES-128 OFB、AES-128 CCM、AES-256 OFB四种加密方案。整个数据库文件(用户数据加上元数据)和日志文件使用应用程序提供的密钥进行加密。在成功调用sqlite3_open API函数之后,应用程序需要根据sqlite3_open API函数返回的连接句柄调用sqlite3 key API函数,从而通知SQLite加密密钥。可以通过使用新的加密密钥调用sqlite3_rekey API函数来重新加密已经加密的数据库。加密虽然使SQLite变慢,但它是SQLite中数据保护的最佳选择。
10.15 Unicode
Unicode是一个单一的字符集(又名字母表),其中包括来自欧洲、拉丁美洲、亚洲、非洲和许多其他主要世界语言的字符。这个集合太大了,不能在单个字节中枚举。对于单奇字符集,有两种广泛使用的编码标准。在一种标准中,每个Unicode字符由一个固定长度的唯一16位(两个8位字节)整数表示,它是UTF-16表示。(UTF代表通用文本格式。)在另一种称为UTF8的标准中,每个Unicode字符由1表示。两个。或者三个8位字节串,
SQLite支持一组不同的API函数,它们以主机的本机字节顺序接受UTF-8和UTF-16格式的输入文本。[-4](本机字节排序是平台支持的表示16位整数布局的方式。)例如,sqlite3_open16 API函数等价于sqlite3_open,不同之处在于它需要以本机字节顺序在UTP16文本字符串中输入数据库文件名。SQLite使用通用类型void*来引用UTF-16字符串。
[-4] 4A SQLite API function whose name ends with “16” is an U’TF16 API: otherwise it is an UTF8 APl, There arthe sufx“16”ome APIs thatwork for both.omitted fomthe APIan gisn璦诎暐鞧赃鈽<佥爊帜革颧蘑苠參淀萭械我e
对于每个数据库文件,SQLite使用TEXT存储类型将数据值管理为UTF-8 UTF-16BE(大端)或UTF-16LE(小端),而不会混合使用它们。在内部(在内存中)或外部(在磁盘文件上),到处都使用相同的文本表示。这是数据库文件的文本编码模式。您可能还记得,编码模式信息存储在偏移量56处的数据库文件头记录中。如果数据库文件是由sqlite3_open(分别为sqlite3_open16) API函数创建的,默认情况下,文本编码模式是UTF8(分别为UTF16,默认的本机顺序为16位整数)。您可以通过在数据库文件创建后初始化数据库文件之前适当地设置pragma编码来覆盖此默认文本编码模式。一旦文件初始化,文本编码格式将被永久设置并且不能更改。如果数据库文件的文本编码与接口api所需的输入文本编码不匹配,那么输入文本将被即时转换。例如,如果为UTF8创建了一个数据库,但是应用程序调用UTF16 API函数来插入UTF16文本,那么在插入到数据库之前,该文本将被转换为UTF8文本,SQLite为此目的使用标准转换算法。
建议: 不断地将文本从一种UTF表示转换为另一种UTF表示在计算上可能会很昂贵,因此建议应用程序开发人员选择一种表示并在整个应用程序中坚持使用它。他们已经得到警告了!
注意: 所有附加的数据库必须具有相同的文本编码格式,SQLite严格遵循主数据库的编码。因此,所有附加的数据库必须具有主数据库的编码,否则。这是一个错误,并且attach命令被拒绝。使用ATTACH命令创建的新数据库将具有与主数据库相同的默认文本编码。如果在执行ATTACH命令时还没有初始化和/或创建主数据库,则在执行ATTACH之前完成初始化
在创建新的用户定义SQL函数或排序序列时,可以指定它是使用UTF-8、UTF-16BE还是UTF-16LE文本。可以为不同的编码标准注册不同的实现。执行SQL语句。如果需要SQL函数或排序序列,但没有当前文本编码的版本,则在调用该函数之前自动转换文本。如前所述,这种转换是计算密集型的,因此建议应用程序开发人员选择一个编码标准并坚持使用它,以尽量减少不必要的杂活.
SQLite对从用户那里接收到的文本不是很挑剔,它会处理未规范化的文本字符串,甚至是格式良好的UTF-8或UTF-16。因此,您可以使用UTF-8 API函数存储ISO8859文本。只要不尝试使用UTF-16排序序列或SQL函数,文本的字节序列就不会以任何方式被修改,在这种情况下是安全的。
解析: 在SQLite的当前实现中,SQL解析器只能处理UTF-8文本。所以如果你给出UTF-16文本,它会在SQLite解析文本之前被转换成UTF-8文本。这就是SQLite现在如何实现它的解析器,在未来,SQLite可以解析UTF-16编码的SQL。
10.16 Collation
排序序列仅仅是在两个文本字符串上定义顺序的一种方式。当SQLite对数据值进行排序(或使用‘< ’或‘<=’之类的比较操作符)时,排序顺序由数据值的存储类型决定。默认排序规则在第196页的7.5.3.2节中给出。如前所述,排序序列仅用于对TEXT类型的字符串排序。排序序列不会改变null、数字或blob的顺序;只有文本。
S排序序列运算符是作为一个C函数实现的,该函数将两个文本字符串作为比较的输入,并根据排序顺序中的第一个字符串分别小于、等于或大于第二个字符串返回负、零或正整数。它是驻留在应用程序空间中的回调函数。SQLite实现了三个内置的排序序列,即‘BINARY ’, ‘RTRIM ’和‘NOCASE ’, BINARY是默认的排序序列。它是通过使用标准C库中的memcmp()函数实现的。(它适用于英语文本。)NOCASE与二进制相同,只是在执行比较之前,英语语言使用的26个大写字符被折叠成它们各自的小写对应部分。RTRIM与二进制相同,只是后面的空格字符会被忽略。
10.16.1 Collation examples
SQLite允许您定义任意的文本比较函数,称为用户定义的排序序列,它可以使用它来代替默认的BINARY排序。您需要在SQLite中注册新的排序序列操作符(参见10.16.3节),使用哪个排序序列的决定由SQL语句中的COLLATE子句控制。每个表的每个列都有一个默认的排序类型。如果需要非默认排序类型,则必须将COLLATElause指定为列定义的一部分。COLLATE子句也可以出现在索引的列或SELECT语句的ORDER BY子句中。
允许的SQL语句中的排序子句仅适用于单个列。排序规则仅用于对该列中的文本条目排序。SQLite使用相应的排列顺序来确定列中两个文本值的顺序;其他非文本值按照第196页第7.5.3.2节规定的规则排序。同一表中的不同列可以有不同的排序规则。
SQL语句create table table1(col1 text, col2 text collate Russian, col3 text)创建了一个包含三个文本列的表。col2列上的COLLATE子句指定在比较该列的文本条目时将使用用户定义的俄语排序序列操作符。它是列的默认排序规则,但可以在索引创建和按语句排序时被另一个排序规则覆盖。SQL语句create index idx on table1(col1 collate Spanish)在col1 from table1上创建索引idx1。用户定义的西班牙语排序函数将索引列中的文本条目按coll值升序排列。SQL语句create index idx2 on table1(col2)在col2上创建索引。该列中的文本条目按照用户定义的排序函数对俄语按升序排列,Select * from tablel order by col3 collate Bengali生成按col3的值排序的文本输出,如按孟加拉语排序函数排序。
10.16.2 Collation resolution
对于二进制比较(=,<,<,>,>,!)=、IS和IS NOT),如果只有一个操作数是列,则列的默认排序类型决定用于比较的排序序列操作符。如果两个操作数都是列,则在比较中使用左操作数的排序类型。如果两个操作数都不是列,则使用BINAR排序序列。
表达式“x BETWEEN y and z”等价于“x >= y and x <= z”。表达式“x IN (SELECT y from…)”的处理方式与表达式“x= y”相同,用于确定要使用的排序序列。如果x是列,则用于“ x IN (y, z…)”形式表达式的排序序列是x的默认排序类型,否则为BINARY。
作为SELECT语句一部分的ORDER BY子句可以被分配一个排序序列,以显式地用于排序操作。在这种情况下,显式排序序列取代其他排序序列并始终使用。否则,如果由ORDER by子句排序的表达式是列。然后使用列的默认排序类型来确定排序顺序。如果表达式不是列,则使用BINARY排序序列。
10.16.3 Collation registration
可以通过执行sqlite3_create_collation(或sqlite3_create_collation16) API函数来注册排序函数。函数的签名如下。
int sqlite3_create_collation(
sqlite3* db,
const char* zName,
int pref16,
void*,
int(*xCompare)(void*,int, const void*,int, const void*)
);
该函数用于通过第一个参数向sqlite3处理程序添加新的(或替换现有的)排序函数。新排序序列的名称指定为sqlite3_create_collation的UTF-8字符串和sqlite3_create_collation16的UTF-16字符串。在这两种情况下,排序规则名称都作为第二个参数(zName)传递。第三个参数必须是常量SQLITE_UTF8、SQLITE _UTF16、SQLITE UTF16LE或SQLITE _UTF16BE之一,这表明用户定义的排序例程(xCompare)将分别传递给使用UTF-8、具有本机字节顺序的UTF-16、UTF-16小端序或UTF-16大端序编码的字符串的指针。用户定义的排序比较器函数的指针必须作为第五个参数传递。如果是NULL,这与删除排序序列是一样的(这样SQLite就不能再调用它了)。
每次调用用户定义的排序序列比较器时,它都会获得void*参数的副本(作为排序注册函数的第四个参数传递)作为比较器的第一个参数。比较器的其余参数是两个字符串,每个字符串由(length, data)对表示,并以注册排序序列时作为第三个参数传递的编码格式进行编码。比较器必须返回负数、零或正数,具体取决于第一个字符串分别小于、等于或大于第二个字符串。
在应用程序初始化开始时注册所有排序函数可能会给应用程序开发人员带来很大负担。SQLite支持一个辅助API函数,即sqlite3_collation_needed(或sqlite3_collation_needded16),用于注册一个通用的用户定义函数,当SQLite需要一个未知排序序列的比较器时调用该函数。调用泛型函数时。应用程序可以为未知排序注册一个比较器。
10.17 WAL Journaling
SQLite开发团队在3.7.0版本中引入了一种新的日志机制,称为WAL日志。这是前面讨论的遗留回滚日志的(独占的)替代方案。可以通过pragma journal_mode=WAL打开这种日志记录模式。当数据库处于WAL模式时(即,文件格式值为2,文件偏移量为18),SQLite使用移动日志记录而不是回滚日志记录。在wal日志记录中,日志文件名与数据库文件名相同,并附加了‘-wal ’,并且它与原始(主、临时或附加)数据库文件位于相同的目录中。
日志活动与遗留日志活动基本相同。写事务在修改页面映像之前添加页面映像(在日志记录中)。(然而,页面图像是正在更新或添加的页面的新版本;通常称为重做映像。)当写事务提交时,在wal日志文件的末尾附加一条提交记录。事务不能获得数据库文件上的排他锁,也不能写文件。这避免了事务阻塞并发读事务完成。读事务不会阻塞写事务。也就是说,读事务的行为就像不存在写事务一样。较新的写事务不断将其日志追加到wal - journal文件中
日志文件的前32个字节描述了文件的格式。图10.4显示了wall journal头的结构。有8个4字节的无符号整数,每个都存储为一个大端数,这两个神奇的数字标识了用于计算日志帧校验和的替代校验和算法(参见下一段)

wal - journal报头后面跟着零个或多个日志帧,每个日志帧以一个24字节的帧报头开始,后面跟着被记录的页的内容。新的日志帧总是附加在日志文件的末尾。图10.5显示了墙框报头的结构。有6个4字节的无符号整数,每个都存储为一个大端数。
在wal日志记录方案中,从数据库中读取a有点复杂,当分页器启动一个新的读事务时,它会记录该读事务的wal日志中最后一个有效提交记录(一个日志帧)的索引。事务将使用这个标记帧作为所有后续读操作的岗哨点。假设分页器收到从读事务读取页p的请求。它查看wal - journal文件,看看是否有页p的日志记录出现在标记框架上或之前。在这种情况下,使用与标记帧之前或相同的page p的最后一个有效实例。否则,分页器将从数据库文件中读取页p。并发写事务可以并且确实将新的日志记录追加到日志中,但是只要读事务使用其原始标记帧值并忽略随后追加的内容,它就会看到从单个时间点开始的数据库的一致快照。这种技术允许多个并发读事务同时查看不同版本的数据库内容。由于页p的日志帧可以出现在wall journal中的任何位置,因此分页器需要从头到尾扫描日志以查找页p帧。如果在事务开始时日志很大,那么扫描的成本会很高,SQLite维护一个单独的数据结构,称为wal-index,以加快搜索。它基本上是一个哈希索引,如果p在日志中,则将页码p映射到相应的日志框架,否则为空。

wal-index是通过共享内存或内存映射文件实现的。映射文件位于与数据库文件相同的目录中,并且具有与数据库文件相同的名称,但附加了“-shm”。(由于使用共享内存或内存映射文件,如果数据库文件驻留在网络文件系统中,并且客户机位于不同的机器上,则不能使用wal日志记录,分布式客户机将无法共享将映射wal-index文件的相同内存。)当最后一个数据库连接关闭时,SQLite将截断或使wal-index文件失效。这意味着walindex文件是一个临时文件。在崩溃恢复时,从wal- journal文件重建wal-index文件。
与回滚日志记录方案不同,日志记录方案需要检查点来检查日志文件的大小。应用程序不需要手动执行检查点,但是如果他们想这样做,他们可以关闭自动检查点选项,当日志文件达到1000页的阈值大小时,SQLite自动执行检查点。(您可以通过将SQLITE_DEFAULT_WAL_AUTOCHECKPOINT编译标志设置为不同的值来设置不同的阈值。)检查点操作按顺序、互斥地执行。在每次调用检查点函数时,SQLite按照上述顺序执行以下步骤。
-
First. it flushes the wal journal file.
-
Second, it transfers some valid page contents to the database file.
-
Third, it flushes the database file (only if the entire wal journal is copied into the database file).
-
Fourth, the salt-1 component of the wal file header is incremented and the salt-2 is randomized (to invalidate the current page log images in the wal journal).
-
Fifth, update the wal-index.
检查点操作的执行可以与读事务并发运行。在这种情况下,检查点在读取任何读事务的wal-mark时或之前停止(见下文)。检查点会记住它的检查点有多远;下一个检查点从这里重新开始。当整个wall日志被检查点时,将回退日志以防止日志文件在没有绑定的情况下增长。
这个特性有利有弊。其优点是:(1)更少的数据库刷新;(2)提高并发性,因为读事务不会阻塞写事务,而写事务也不会阻塞读事务;(3)在大多数情况下事务处理相当快。缺点是:(1)来自操作系统的内存映射支持;(2)访问数据库文件的所有应用程序必须运行在同一台机器上;(3)数据库文件不能被NFS挂载;(4)多数据库事务可能不是跨所有数据库的原子事务,尽管在单个数据库中是原子事务;(5)事务回滚稍微慢一些;(6)需要两个额外的文件-(-shm和-wal);(7)需要检查点,等等。您可以在http:www.sqlite.org/wal.html上找到该特性的详细描述。
10.18 Compile Directives(指令)
SQLite源代码有许多可定制的编译标记或选项,带有默认选项值。您可以使用SQLite库的默认值来构建和安全地使用它们。但是,您可以使用不同的值或省略特定的SQLite特性(导致更小的库大小)。每个选项都可以通过在选项名前加前缀“D”传递给编译器。例如,对于NDEBUG选项,在编译命令中使用-DNDEBUG。下面描述了一些选项。它们被分为几类。(您可以在https:// www.salite.org/compile.html网页上找到当前支持的所有编译选项。)
-
Options to set debugging fags
-
SOLITE DEBUG:Many testing and debugging features are enabled.
-
SQLITE_MEMDEBUG: This option enables a modifed malloc with a lot of checking such as bounds checking, using freed memory, using uninitialized memory, memory leak testing,etc.
-
-
Options to set default parameter values
-
SQLITE_DEFAULT_AUTOVACUUM=(0,1,or 2): This macro determines whether or not SQLite creates databases with the autovacuum option set by default. The default value is 0 (do not create autovacuum databases). The compilation time default may be overridden at runtime by the PRAGMA auto_vacuum command before creating any table in the oatapase.
-
SOLITE_DEFAULT_CACHE _SIZE=(number): This macro sets the default size of the page-cache for each directly opened or attached database; the number is in pages. Thdefault value is 2000, This value can be overridden by the PRAGMA default_cache_size_command at runtime.
-
SOLITE_DEFAULT_TEMP_CACHE _SIZE=(number): This macro sets the default sizof the page-cache for temporary fles created by SQLite to store intermediate resultsthe number is in pages. The default value is 500. It does not affect the page-cache fothe temp database.
-
SQLITE_DEFAULT_PAGE_SIZE=(number): This macro is used to set the default page-size to be used when a database is created; the number is in bytes. The value assignec must be a power of 2, and between 512 and 65,536 (both inclusive). The default value is 1024. The compile-time default may be overridden at runtime by the PRAGMA page_size command.
-
-
Options to omit features. There are many omit options that causes specifc features to be disabled from the SQLite library. Each option name is prefxed with SQLITE_OMIT_character string. These option are primarily used to reduce the library footprint for embedded systems.
- SOLITE_OMIT_TEMPDB: When this option is defined, SQLite does not create ancopen the temp database for open library connections. The sqlite_temp_master catalogtable will not be created.
- SQLITE_OMIT_ALTERTABLE: When this option is defined, the SQL alter tablefeature is not included in the library, No alter table statement will be recognized by the library.
- SQLITE_OMIT_AUTHORIZATION: When this option is defned, SQLite omits the authorization callback feature from the library, The sqlite3_set_authorizer API function is not defned in the library.
- SQLITE_OMIT AUTOINCREMENT: When this option is defned, the AUTOINCREMENT functionality is not included in the SQLite library. The ‘INTEGER PRIMARYKEY AUTOINCREMENT,columns will be treated as if they are declared as ‘INTEGER PRIMARY KEY’ when a NULL value is inserted. The library does not create norlook at the existing sqlite_sequence catalog. if it already exists
- SOLITE OMIT _AUTOVACUUM: When this option is defned, the library cannot creator write to databases that support autovacuum. When this library opens a databasethat supports autovacuum, it is opened in the readonly mode; applications cannot writethe fle.
- SQLITE OMIT PRAGMA: When this option is defined, the PRAGMA feature is excluded from the library.
- SQLITE_OMIT COMPOUND_SELECT: When this option is defined,the compoundSELEOT funetionality is excluded from the library. SELEOT statements that includeUNION, UNION ALL, INTERSECT or EXCEPT will be rejected by the library duringquery parsing.
- SQLITE OMIT REINDEX: When this option is defined, the REINDEX command isexcluded from the library, REINDEX commands will be rejected by the library.
- SQLITEOMIT _SUBQUERY: When this option is defined, the support for sub-selectsand the IN operator are excluded from the library.
- SQLITE_OMIT_TRIGGER: When this option is defined, the TRIGGER feature is excluded from the library, TRIGGER commands will be rejected by the library.
- SQLITE OMIT UTF16: When this option is defined, UTF16 text encoding feature isexcluded from the library. All API functions that deal with UTF16 encoded text arenot available,
-
Options to set size limits: The limit categories are discussed in Section 2.5 on page 69. Foreach category, there is a pragma that you can use to set their max values.
-
Options to control operating characteristics: In this category, you have options such as threadsafe,case sensitive like, temp store.
-
Options to enable features: In this category, you have options such as FTS3, ICU, RTREEmemory management
-
Options to disable features: In this category, you have choices of disabling large file supporand directory sync.
您可以使用这些qlite3_compileoption_used和sqlite3_compileoption_get API函数来检查和获取用于构建SQLite库的编译时选项。这些函数在ctime.c源文件中定义
Summary
SQLite支持许多高级特性。它们是可选的,您可以通过使用适当的编译标记集编译SQLite源代码来单独关闭它们。关闭它们将减少SQLite库的占用。值得注意的是这些特性包括pragma,子查询,view, trigger, autovacuum,shared page cache,collation。
Pragmas帮助您获取有关各种数据库元数据的信息,并在运行时更改SQLite库的行为。例如,如果执行pragma synchronous=off,此后所有(系统和用户)事务都将成为异步事务,并且它们永远不会同步/刷新日志和数据库文件。
视图虽然不是持久化表,但通常非常有用。SQLite在主目录中为每个视图定义存储一行,其中create view SQL语句存储在主目录的SQL列中。当在查询中使用视图时,将执行视图的select语句以形成查询中使用的临时表。SQLite不支持在视图上执行插入、删除和更新查询。
触发器是一个重要的功能。它可以帮助您预定义包含一个或多个SQL语句的过程。当某些指定的事件发生时,SQLite将自动执行这些过程。触发器由事件、条件和操作定义。当事件(插入、删除或更新)发生时,触发器被称为激活。此时,将计算触发条件。如果条件为真,则执行触发动作(即过程)。有两种类型的触发器:(1)用于每一行,(2)用于每条语句。到目前为止,SOLite只支持前者
SQLite对unicode字符有很好的支持。它具有UTF-8和utf -16 (BE和LE)的能力。数据库只能使用其中的一种,所有的TEXT数据在使用它们之前都被翻译成所选的UTF格式.